 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-CARE: An Efficient LLM-based Commonsense-Augmented Framework for E-Commerce
Nov 06, 2025Finding relevant products given a user query plays a pivotal role in an e-commerce platform, as it can spark shopping behaviors and result in revenue gains. The challenge lies in accurately predicting the correlation between queries and products. Recently, mining the cross-features between queries and products based on the commonsense reasoning capacity of Large Language Models (LLMs) has shown promising performance. However, such methods suffer from high costs due to intensive real-time LLM inference during serving, as well as human annotations and potential Supervised Fine Tuning (SFT). To boost efficiency while leveraging the commonsense reasoning capacity of LLMs for various e-commerce tasks, we propose the Efficient Commonsense-Augmented Recommendation Enhancer (E-CARE). During inference, models augmented with E-CARE can access commonsense reasoning with only a single LLM forward pass per query by utilizing a commonsense reasoning factor graph that encodes most of the reasoning schema from powerful LLMs. The experiments on 2 downstream tasks show an improvement of up to 12.1% on precision@5.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025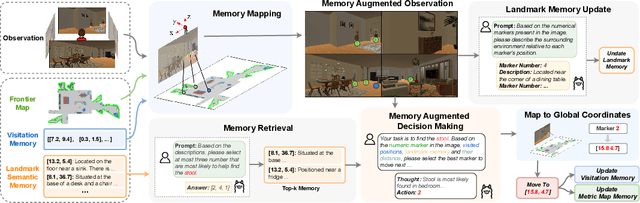
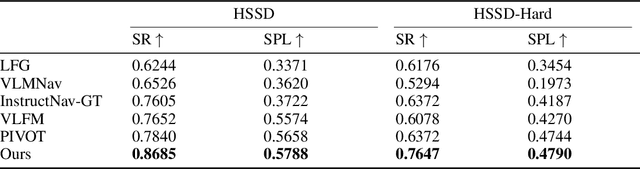
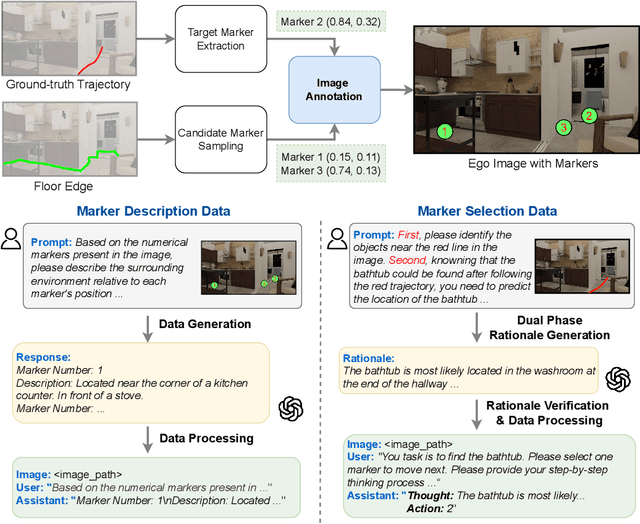

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025



Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
Path-of-Thoughts: Extracting and Following Paths for Robust Relational Reasoning with Large Language Models
Dec 23, 2024



Large language models (LLMs) possess vast semantic knowledge but often struggle with complex reasoning tasks, particularly in relational reasoning problems such as kinship or spatial reasoning. In this paper, we present Path-of-Thoughts (PoT), a novel framework designed to tackle relation reasoning by decomposing the task into three key stages: graph extraction, path identification, and reasoning. Unlike previous approaches, PoT efficiently extracts a task-agnostic graph that identifies crucial entities, relations, and attributes within the problem context. Subsequently, PoT identifies relevant reasoning chains within the graph corresponding to the posed question, facilitating inference of potential answers. Experimental evaluations on four benchmark datasets, demanding long reasoning chains, demonstrate that PoT surpasses state-of-the-art baselines by a significant margin (maximum 21.3%) without necessitating fine-tuning or extensive LLM calls. Furthermore, as opposed to prior neuro-symbolic methods, PoT exhibits improved resilience against LLM errors by leveraging the compositional nature of graphs.
Enhancing CTR Prediction in Recommendation Domain with Search Query Representation
Oct 28, 2024



Many platforms, such as e-commerce websites, offer both search and recommendation services simultaneously to better meet users' diverse needs. Recommendation services suggest items based on user preferences, while search services allow users to search for items before providing recommendations. Since users and items are often shared between the search and recommendation domains, there is a valuable opportunity to enhance the recommendation domain by leveraging user preferences extracted from the search domain. Existing approaches either overlook the shift in user intention between these domains or fail to capture the significant impact of learning from users' search queries on understanding their interests. In this paper, we propose a framework that learns from user search query embeddings within the context of user preferences in the recommendation domain. Specifically, user search query sequences from the search domain are used to predict the items users will click at the next time point in the recommendation domain. Additionally, the relationship between queries and items is explored through contrastive learning. To address issues of data sparsity, the diffusion model is incorporated to infer positive items the user will select after searching with certain queries in a denoising manner, which is particularly effective in preventing false positives. Effectively extracting this information, the queries are integrated into click-through rate prediction in the recommendation domain. Experimental analysis demonstrates that our model outperforms state-of-the-art models in the recommendation domain.
* Accepted by CIKM 2024 Full Research Track
Sparse Decomposition of Graph Neural Networks
Oct 25, 2024



Graph Neural Networks (GNN) exhibit superior performance in graph representation learning, but their inference cost can be high, due to an aggregation operation that can require a memory fetch for a very large number of nodes. This inference cost is the major obstacle to deploying GNN models with \emph{online prediction} to reflect the potentially dynamic node features. To address this, we propose an approach to reduce the number of nodes that are included during aggregation. We achieve this through a sparse decomposition, learning to approximate node representations using a weighted sum of linearly transformed features of a carefully selected subset of nodes within the extended neighbourhood. The approach achieves linear complexity with respect to the average node degree and the number of layers in the graph neural network. We introduce an algorithm to compute the optimal parameters for the sparse decomposition, ensuring an accurate approximation of the original GNN model, and present effective strategies to reduce the training time and improve the learning process. We demonstrate via extensive experiments that our method outperforms other baselines designed for inference speedup, achieving significant accuracy gains with comparable inference times for both node classification and spatio-temporal forecasting tasks.
Towards Automated Negative Sampling in Implicit Recommendation
Nov 06, 2023



Negative sampling methods are vital in implicit recommendation models as they allow us to obtain negative instances from massive unlabeled data. Most existing approaches focus on sampling hard negative samples in various ways. These studies are orthogonal to the recommendation model and implicit datasets. However, such an idea contradicts the common belief in AutoML that the model and dataset should be matched. Empirical experiments suggest that the best-performing negative sampler depends on the implicit dataset and the specific recommendation model. Hence, we propose a hypothesis that the negative sampler should align with the capacity of the recommendation models as well as the statistics of the datasets to achieve optimal performance. A mismatch between these three would result in sub-optimal outcomes. An intuitive idea to address the mismatch problem is to exhaustively select the best-performing negative sampler given the model and dataset. However, such an approach is computationally expensive and time-consuming, leaving the problem unsolved. In this work, we propose the AutoSample framework that adaptively selects the best-performing negative sampler among candidates. Specifically, we propose a loss-to-instance approximation to transform the negative sampler search task into the learning task over a weighted sum, enabling end-to-end training of the model. We also designed an adaptive search algorithm to extensively and efficiently explore the search space. A specific initialization approach is also obtained to better utilize the obtained model parameters during the search stage, which is similar to curriculum learning and leads to better performance and less computation resource consumption. We evaluate the proposed framework on four benchmarks over three models. Extensive experiments demonstrate the effectiveness and efficiency of our proposed framework.
Compressed Interaction Graph based Framework for Multi-behavior Recommendation
Mar 04, 2023



Multi-types of user behavior data (e.g., clicking, adding to cart, and purchasing) are recorded in most real-world recommendation scenarios, which can help to learn users' multi-faceted preferences. However, it is challenging to explore multi-behavior data due to the unbalanced data distribution and sparse target behavior, which lead to the inadequate modeling of high-order relations when treating multi-behavior data ''as features'' and gradient conflict in multitask learning when treating multi-behavior data ''as labels''. In this paper, we propose CIGF, a Compressed Interaction Graph based Framework, to overcome the above limitations. Specifically, we design a novel Compressed Interaction Graph Convolution Network (CIGCN) to model instance-level high-order relations explicitly. To alleviate the potential gradient conflict when treating multi-behavior data ''as labels'', we propose a Multi-Expert with Separate Input (MESI) network with separate input on the top of CIGCN for multi-task learning. Comprehensive experiments on three large-scale real-world datasets demonstrate the superiority of CIGF. Ablation studies and in-depth analysis further validate the effectiveness of our proposed model in capturing high-order relations and alleviating gradient conflict. The source code and datasets are available at https://github.com/MC-CV/CIGF.
A Survey on User Behavior Modeling in Recommender Systems
Feb 22, 2023


User Behavior Modeling (UBM) plays a critical role in user interest learning, which has been extensively used in recommender systems. Crucial interactive patterns between users and items have been exploited, which brings compelling improvements in many recommendation tasks. In this paper, we attempt to provide a thorough survey of this research topic. We start by reviewing the research background of UBM. Then, we provide a systematic taxonomy of existing UBM research works, which can be categorized into four different directions including Conventional UBM, Long-Sequence UBM, Multi-Type UBM, and UBM with Side Information. Within each direction, representative models and their strengths and weaknesses are comprehensively discussed. Besides, we elaborate on the industrial practices of UBM methods with the hope of providing insights into the application value of existing UBM solutions. Finally, we summarize the survey and discuss the future prospects of this field.