 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCase-Structured: A Text-to-FHIR Dataset for Benchmarking Diagnostic Reasoning in Clinically Realistic EHR Settings
May 28, 2026Large language models (LLMs) show promise for clinical reasoning and decision support, but evaluation in realistic, electronic health record-congruent settings remains limited. Existing benchmarks often rely on static datasets or unstructured inputs that do not reflect the structured, interoperable data formats used in clinical systems. We introduce a pipeline for generating clinically realistic HL7 FHIR R4 bundles from unstructured text, enabling controllable evaluation of clinical decision support systems. The pipeline combines staged LLM generation with terminology-grounded validation and repair to reduce hallucinated codes and enforce structural and semantic consistency. Applying this approach to MedCaseReasoning, we construct MedCase-Structured, a synthetic dataset aligned with clinician-authored diagnostic cases, achieving valid FHIR generation for 82.5% of cases. Evaluation on MedCase-Structured reveals consistently lower diagnostic accuracy for LLMs on structured FHIR inputs than with plain text, highlighting the importance of deployment-aligned benchmarking.
TravelAgent: An AI Assistant for Personalized Travel Planning
Sep 12, 2024



As global tourism expands and artificial intelligence technology advances, intelligent travel planning services have emerged as a significant research focus. Within dynamic real-world travel scenarios with multi-dimensional constraints, services that support users in automatically creating practical and customized travel itineraries must address three key objectives: Rationality, Comprehensiveness, and Personalization. However, existing systems with rule-based combinations or LLM-based planning methods struggle to fully satisfy these criteria. To overcome the challenges, we introduce TravelAgent, a travel planning system powered by large language models (LLMs) designed to provide reasonable, comprehensive, and personalized travel itineraries grounded in dynamic scenarios. TravelAgent comprises four modules: Tool-usage, Recommendation, Planning, and Memory Module. We evaluate TravelAgent's performance with human and simulated users, demonstrating its overall effectiveness in three criteria and confirming the accuracy of personalized recommendations.
From Persona to Personalization: A Survey on Role-Playing Language Agents
Apr 28, 2024



Recent advancements in large language models (LLMs) have significantly boosted the rise of Role-Playing Language Agents (RPLAs), i.e., specialized AI systems designed to simulate assigned personas. By harnessing multiple advanced abilities of LLMs, including in-context learning, instruction following, and social intelligence, RPLAs achieve a remarkable sense of human likeness and vivid role-playing performance. RPLAs can mimic a wide range of personas, ranging from historical figures and fictional characters to real-life individuals. Consequently, they have catalyzed numerous AI applications, such as emotional companions, interactive video games, personalized assistants and copilots, and digital clones. In this paper, we conduct a comprehensive survey of this field, illustrating the evolution and recent progress in RPLAs integrating with cutting-edge LLM technologies. We categorize personas into three types: 1) Demographic Persona, which leverages statistical stereotypes; 2) Character Persona, focused on well-established figures; and 3) Individualized Persona, customized through ongoing user interactions for personalized services. We begin by presenting a comprehensive overview of current methodologies for RPLAs, followed by the details for each persona type, covering corresponding data sourcing, agent construction, and evaluation. Afterward, we discuss the fundamental risks, existing limitations, and future prospects of RPLAs. Additionally, we provide a brief review of RPLAs in AI applications, which reflects practical user demands that shape and drive RPLA research. Through this work, we aim to establish a clear taxonomy of RPLA research and applications, and facilitate future research in this critical and ever-evolving field, and pave the way for a future where humans and RPLAs coexist in harmony.
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
May 22, 2023



In everyday life, humans often plan their actions by following step-by-step instructions in the form of goal-oriented scripts. Previous work has exploited language models (LMs) to plan for abstract goals of stereotypical activities (e.g., "make a cake"), but leaves more specific goals with multi-facet constraints understudied (e.g., "make a cake for diabetics"). In this paper, we define the task of constrained language planning for the first time. We propose an overgenerate-then-filter approach to improve large language models (LLMs) on this task, and use it to distill a novel constrained language planning dataset, CoScript, which consists of 55,000 scripts. Empirical results demonstrate that our method significantly improves the constrained language planning ability of LLMs, especially on constraint faithfulness. Furthermore, CoScript is demonstrated to be quite effective in endowing smaller LMs with constrained language planning ability.
Say What You Mean! Large Language Models Speak Too Positively about Negative Commonsense Knowledge
May 13, 2023



Large language models (LLMs) have been widely studied for their ability to store and utilize positive knowledge. However, negative knowledge, such as "lions don't live in the ocean", is also ubiquitous in the world but rarely mentioned explicitly in the text. What do LLMs know about negative knowledge? This work examines the ability of LLMs to negative commonsense knowledge. We design a constrained keywords-to-sentence generation task (CG) and a Boolean question-answering task (QA) to probe LLMs. Our experiments reveal that LLMs frequently fail to generate valid sentences grounded in negative commonsense knowledge, yet they can correctly answer polar yes-or-no questions. We term this phenomenon the belief conflict of LLMs. Our further analysis shows that statistical shortcuts and negation reporting bias from language modeling pre-training cause this conflict.
E-KAR: A Benchmark for Rationalizing Natural Language Analogical Reasoning
Mar 16, 2022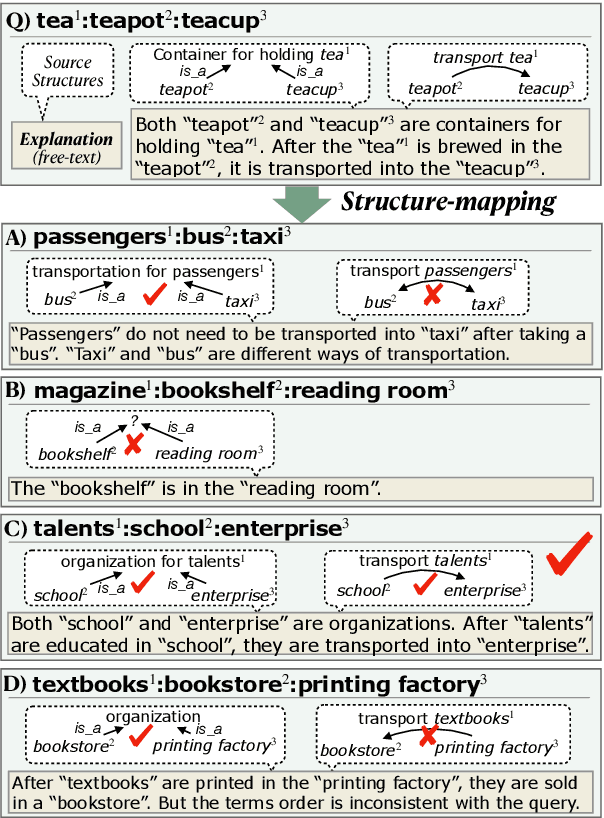
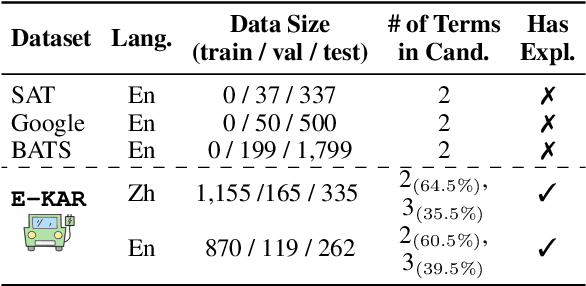
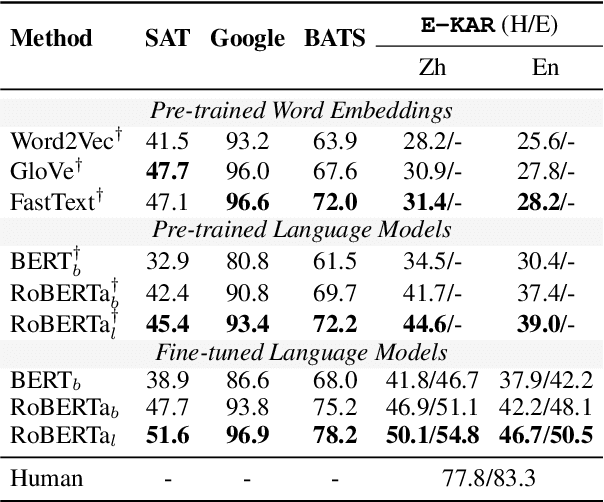
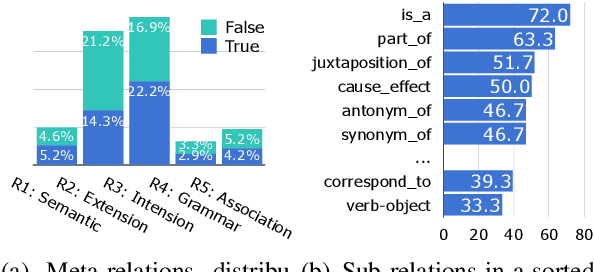
The ability to recognize analogies is fundamental to human cognition. Existing benchmarks to test word analogy do not reveal the underneath process of analogical reasoning of neural models. Holding the belief that models capable of reasoning should be right for the right reasons, we propose a first-of-its-kind Explainable Knowledge-intensive Analogical Reasoning benchmark (E-KAR). Our benchmark consists of 1,655 (in Chinese) and 1,251 (in English) problems sourced from the Civil Service Exams, which require intensive background knowledge to solve. More importantly, we design a free-text explanation scheme to explain whether an analogy should be drawn, and manually annotate them for each and every question and candidate answer. Empirical results suggest that this benchmark is very challenging for some state-of-the-art models for both explanation generation and analogical question answering tasks, which invites further research in this area.