 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Language Model Pretraining for Biomedical Natural Language Processing
Aug 20, 2020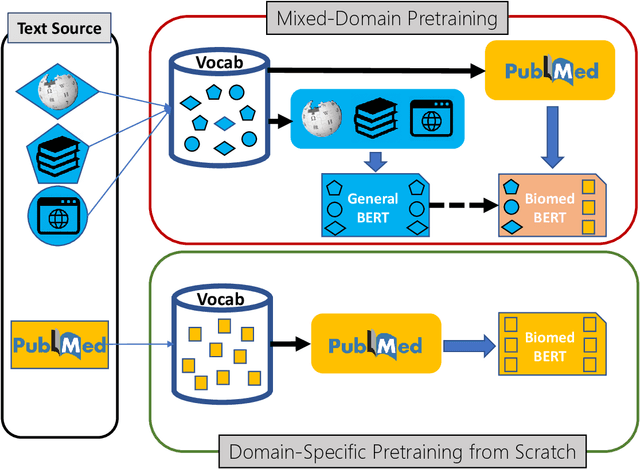
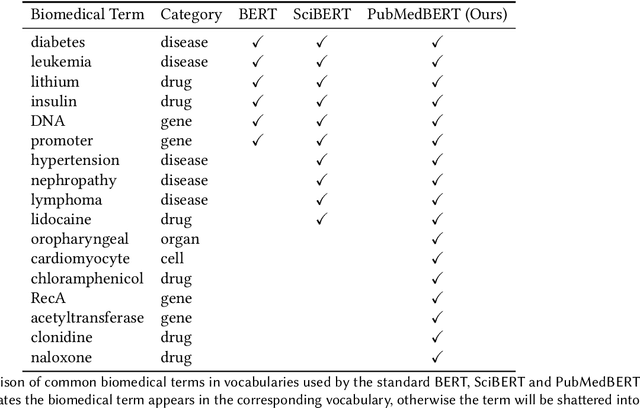
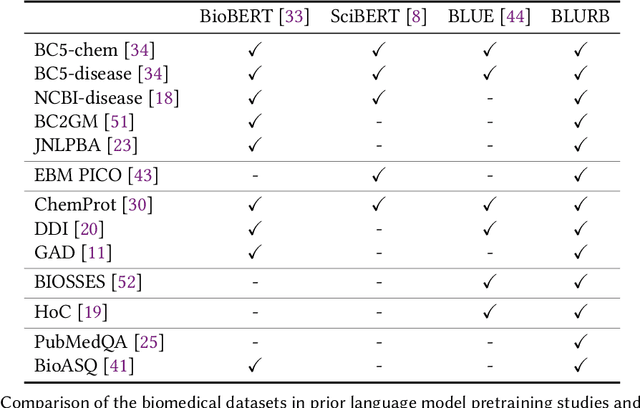
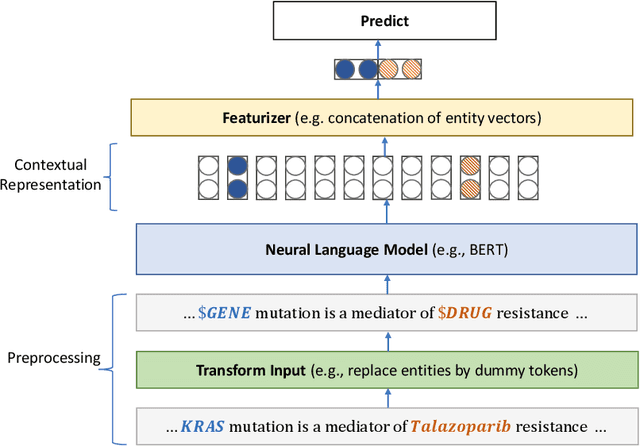
Pretraining large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. However, most pretraining efforts focus on general domain corpora, such as newswire and Web. A prevailing assumption is that even domain-specific pretraining can benefit by starting from general-domain language models. In this paper, we challenge this assumption by showing that for domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models. To facilitate this investigation, we compile a comprehensive biomedical NLP benchmark from publicly-available datasets. Our experiments show that domain-specific pretraining serves as a solid foundation for a wide range of biomedical NLP tasks, leading to new state-of-the-art results across the board. Further, in conducting a thorough evaluation of modeling choices, both for pretraining and task-specific fine-tuning, we discover that some common practices are unnecessary with BERT models, such as using complex tagging schemes in named entity recognition (NER). To help accelerate research in biomedical NLP, we have released our state-of-the-art pretrained and task-specific models for the community, and created a leaderboard featuring our BLURB benchmark (short for Biomedical Language Understanding & Reasoning Benchmark) at https://aka.ms/BLURB.
Very Deep Transformers for Neural Machine Translation
Aug 18, 2020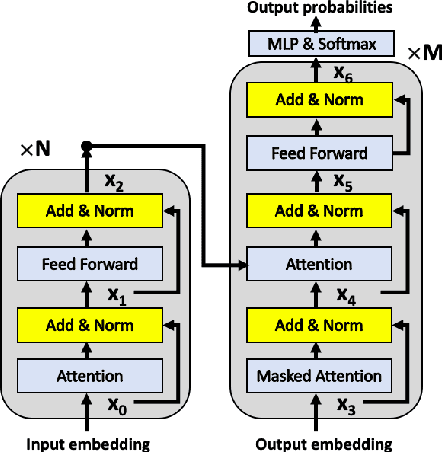
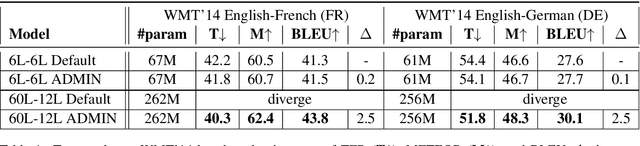
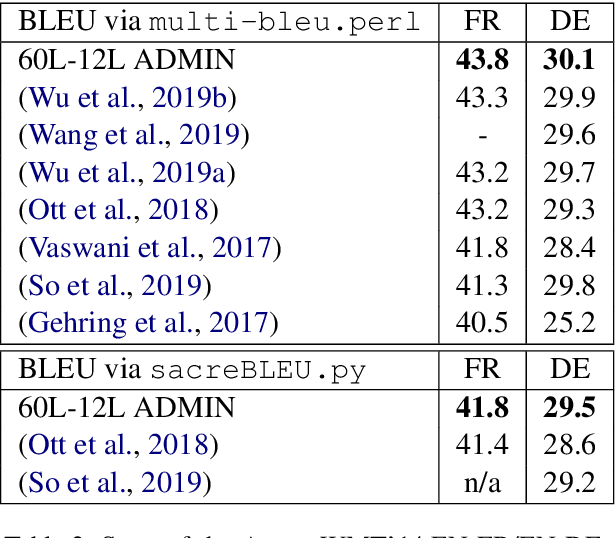
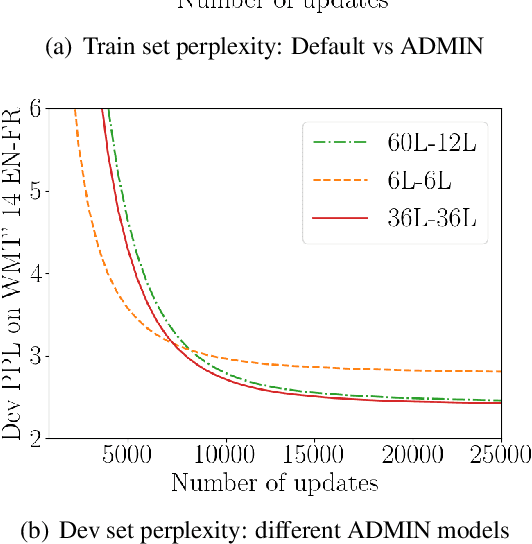
We explore the application of very deep Transformer models for Neural Machine Translation (NMT). Using a simple yet effective initialization technique that stabilizes training, we show that it is feasible to build standard Transformer-based models with up to 60 encoder layers and 12 decoder layers. These deep models outperform their baseline 6-layer counterparts by as much as 2.5 BLEU, and achieve new state-of-the-art benchmark results on WMT14 English-French (43.8 BLEU) and WMT14 English-German (30.1 BLEU).The code and trained models will be publicly available at: https://github.com/namisan/exdeep-nmt.
Evaluation of Text Generation: A Survey
Jun 26, 2020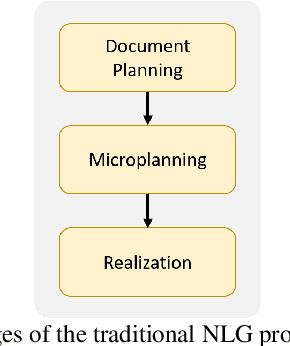

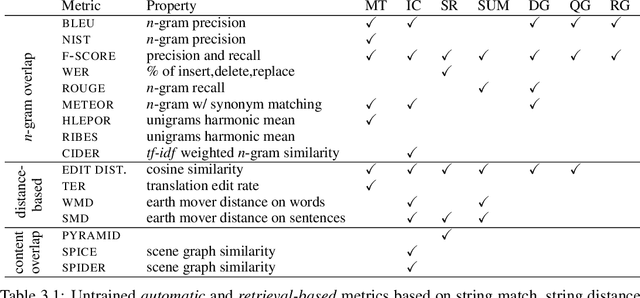
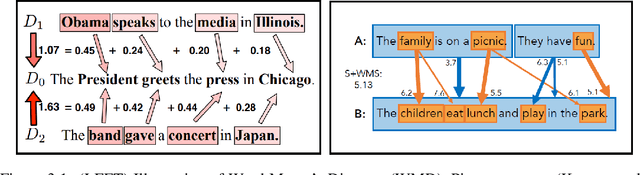
The paper surveys evaluation methods of natural language generation (NLG) systems that have been developed in the last few years. We group NLG evaluation methods into three categories: (1) human-centric evaluation metrics, (2) automatic metrics that require no training, and (3) machine-learned metrics. For each category, we discuss the progress that has been made and the challenges still being faced, with a focus on the evaluation of recently proposed NLG tasks and neural NLG models. We then present two case studies of automatic text summarization and long text generation, and conclude the paper by proposing future research directions.
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Jun 05, 2020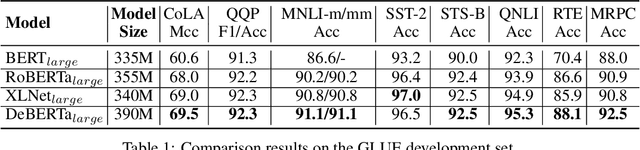
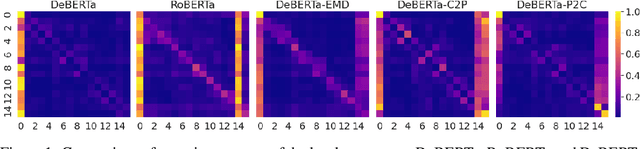
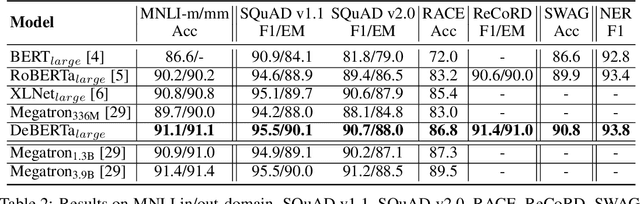
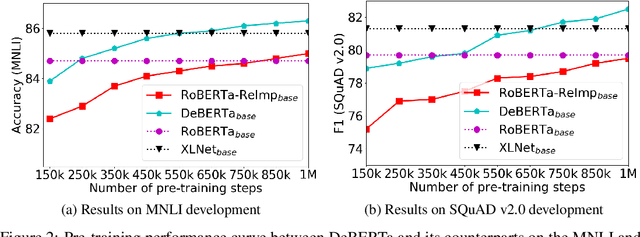
Recent progress in pre-trained neural language models has significantly improved the performance of many natural language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where each word is represented using two vectors that encode its content and position, respectively, and the attention weights among words are computed using disentangled matrices on their contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency of model pre-training and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9% (90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020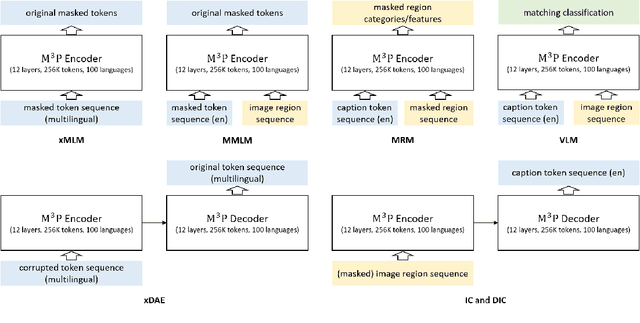


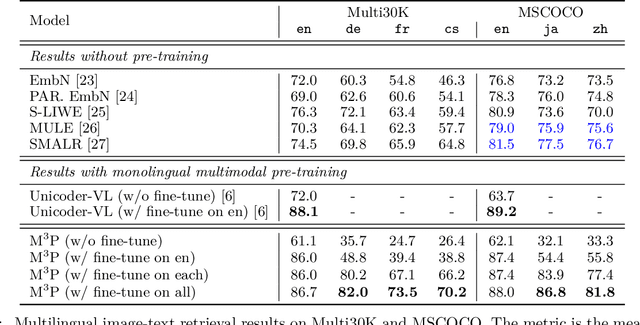
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
Novel Human-Object Interaction Detection via Adversarial Domain Generalization
May 22, 2020
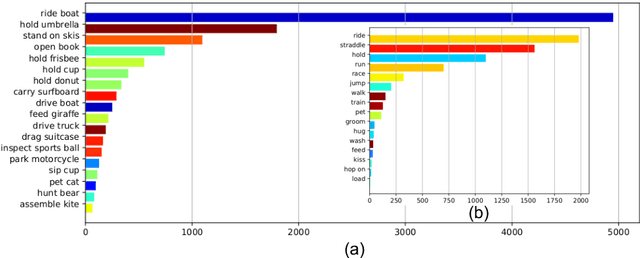
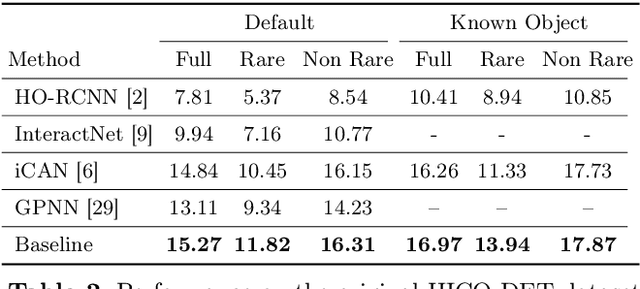
We study in this paper the problem of novel human-object interaction (HOI) detection, aiming at improving the generalization ability of the model to unseen scenarios. The challenge mainly stems from the large compositional space of objects and predicates, which leads to the lack of sufficient training data for all the object-predicate combinations. As a result, most existing HOI methods heavily rely on object priors and can hardly generalize to unseen combinations. To tackle this problem, we propose a unified framework of adversarial domain generalization to learn object-invariant features for predicate prediction. To measure the performance improvement, we create a new split of the HICO-DET dataset, where the HOIs in the test set are all unseen triplet categories in the training set. Our experiments show that the proposed framework significantly increases the performance by up to 50% on the new split of HICO-DET dataset and up to 125% on the UnRel dataset for auxiliary evaluation in detecting novel HOIs.
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
May 18, 2020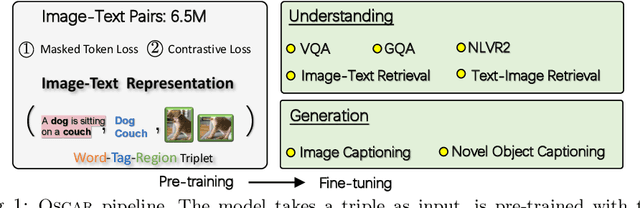

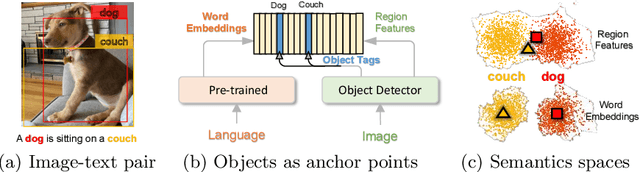
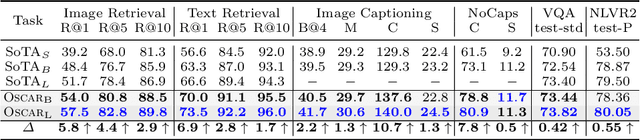
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text. We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fine-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.
Is Your Goal-Oriented Dialog Model Performing Really Well? Empirical Analysis of System-wise Evaluation
May 15, 2020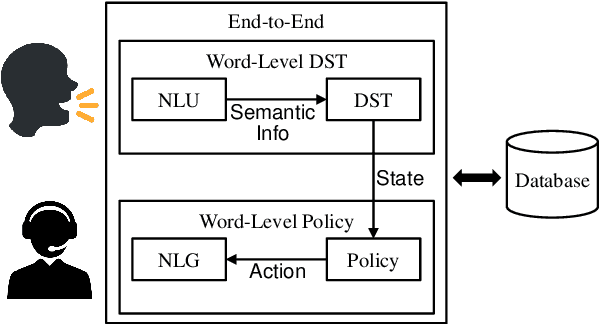
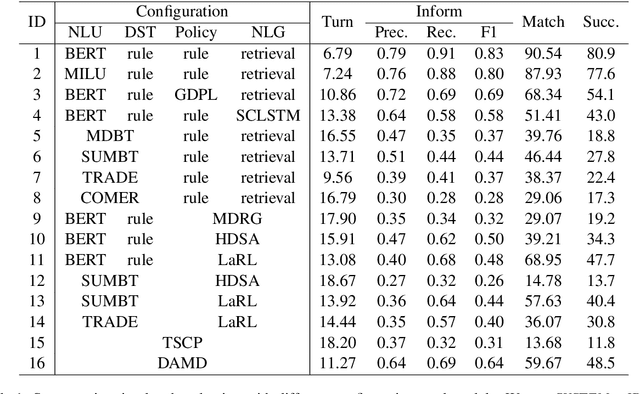
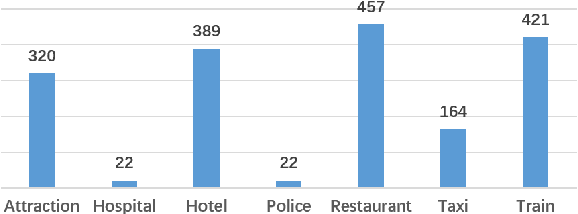
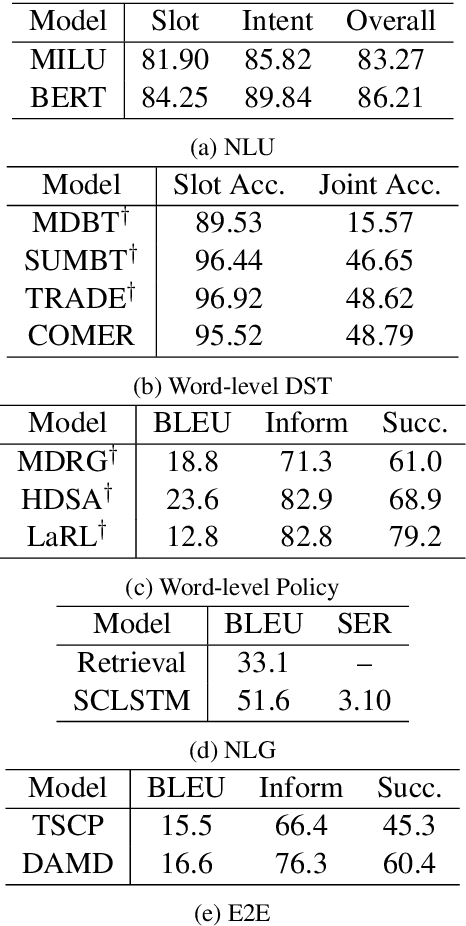
There is a growing interest in developing goal-oriented dialog systems which serve users in accomplishing complex tasks through multi-turn conversations. Although many methods are devised to evaluate and improve the performance of individual dialog components, there is a lack of comprehensive empirical study on how different components contribute to the overall performance of a dialog system. In this paper, we perform a system-wise evaluation and present an empirical analysis on different types of dialog systems which are composed of different modules in different settings. Our results show that (1) a pipeline dialog system trained using fine-grained supervision signals at different component levels often obtains better performance than the systems that use joint or end-to-end models trained on coarse-grained labels, (2) component-wise, single-turn evaluation results are not always consistent with the overall performance of a dialog system, and (3) despite the discrepancy between simulators and human users, simulated evaluation is still a valid alternative to the costly human evaluation especially in the early stage of development.
SOLOIST: Few-shot Task-Oriented Dialog with A Single Pre-trained Auto-regressive Model
May 14, 2020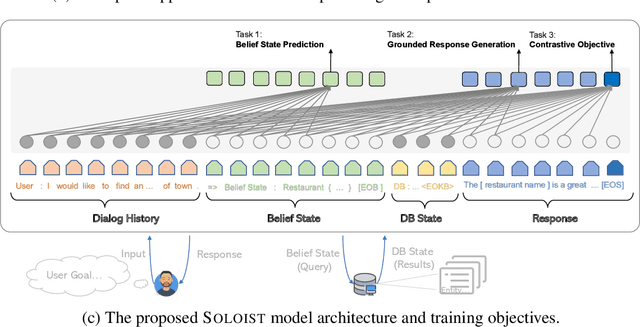
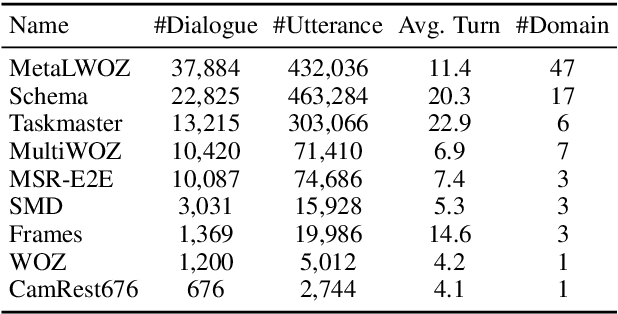
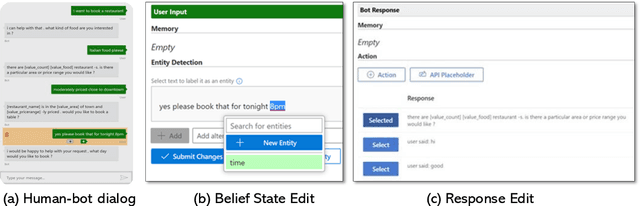

This paper presents a new method SOLOIST, which uses transfer learning to efficiently build task-oriented dialog systems at scale. We parameterize a dialog system using a Transformer-based auto-regressive language model, which subsumes different dialog modules (e.g., state tracker, dialog policy, response generator) into a single neural model. We pre-train, on large heterogeneous dialog corpora, a large-scale Transformer model which can generate dialog responses grounded in user goals and real-world knowledge for task completion. The pre-trained model can be efficiently adapted to accomplish a new dialog task with a handful of task-specific dialogs via machine teaching. Our experiments demonstrate that (i) SOLOIST creates new state-of-the-art results on two well-known benchmarks, CamRest and MultiWOZ, (ii) in the few-shot learning setting, the dialog systems developed by SOLOIST significantly outperform those developed by existing methods, and (iii) the use of machine teaching substantially reduces the labeling cost. We will release our code and pre-trained models for reproducible research.
RMM: A Recursive Mental Model for Dialog Navigation
May 02, 2020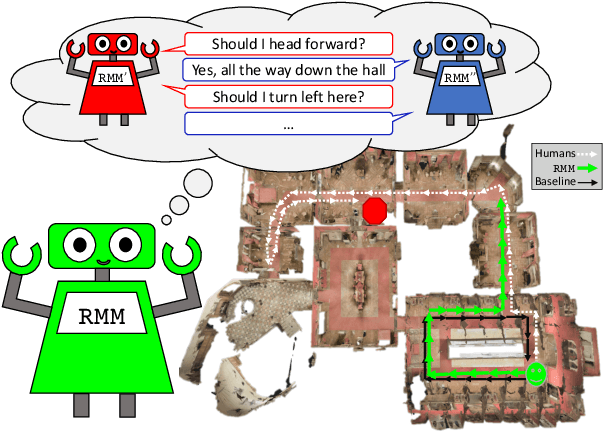
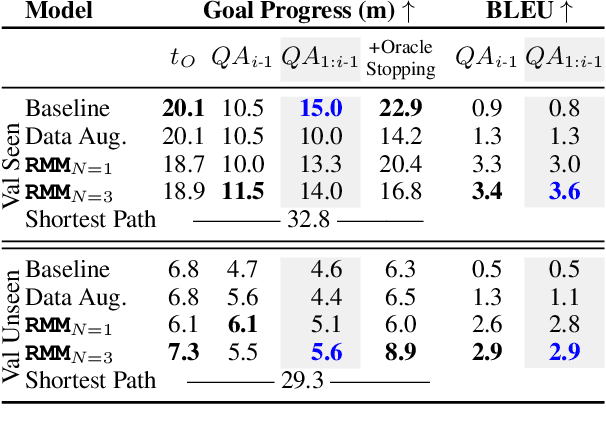
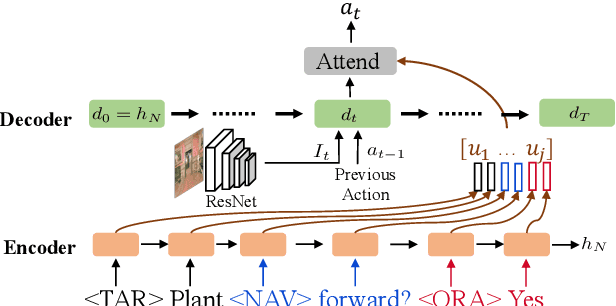

Fluent communication requires understanding your audience. In the new collaborative task of Vision-and-Dialog Navigation, one agent must ask questions and follow instructive answers, while the other must provide those answers. We introduce the first true dialog navigation agents in the literature which generate full conversations, and introduce the Recursive Mental Model (RMM) to conduct these dialogs. RMM dramatically improves generated language questions and answers by recursively propagating reward signals to find the question expected to elicit the best answer, and the answer expected to elicit the best navigation. Additionally, we provide baselines for future work to build on when investigating the unique challenges of embodied visual agents that not only interpret instructions but also ask questions in natural language.