 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking VLM Representation for VLA Initialization
May 25, 2026Vision-Language-Action (VLA) models widely adopt pretrained Vision-Language Models (VLMs) as policy backbones, yet it remains unclear what kind of pretrained VLM representation is useful as a VLA initialization. In this paper, we study VLA initialization as a controlled representation-design problem along three axes: capability-level embodied VQA supervision, parameter-update strategy, and robot-data pretraining. Our experiments show that the original pretrained VLM representation is a key source of action performance. However, embodied VQA adaptation does not yield uniform gains: its benefit depends on downstream bottlenecks, and gains from different capability domains are not simply additive. For update strategy, LoRA provides a more reliable initialization than Full Finetune, indicating that overly reshaping the pretrained representation can weaken VLA initialization. Robot-data pretraining further improves VLA initialization, with the strongest variant obtained by staged LoRA-based training. Together, these findings suggest that effective VLM-to-VLA adaptation should inject action-relevant embodied and robot-trajectory signals while preserving the pretrained VLM representation that remains useful for action learning.
A Unified Memory Perspective for Probabilistic Trustworthy AI
Mar 26, 2026Trustworthy artificial intelligence increasingly relies on probabilistic computation to achieve robustness, interpretability, security and privacy. In practical systems, such workloads interleave deterministic data access with repeated stochastic sampling across models, data paths and system functions, shifting performance bottlenecks from arithmetic units to memory systems that must deliver both data and randomness. Here we present a unified data-access perspective in which deterministic access is treated as a limiting case of stochastic sampling, enabling both modes to be analyzed within a common framework. This view reveals that increasing stochastic demand reduces effective data-access efficiency and can drive systems into entropy-limited operation. Based on this insight, we define memory-level evaluation criteria, including unified operation, distribution programmability, efficiency, robustness to hardware non-idealities and parallel compatibility. Using these criteria, we analyze limitations of conventional architectures and examine emerging probabilistic compute-in-memory approaches that integrate sampling with memory access, outlining pathways toward scalable hardware for trustworthy AI.
ACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
A 65 nm Bayesian Neural Network Accelerator with 360 fJ/Sample In-Word GRNG for AI Uncertainty Estimation
Jan 08, 2025



Uncertainty estimation is an indispensable capability for AI-enabled, safety-critical applications, e.g. autonomous vehicles or medical diagnosis. Bayesian neural networks (BNNs) use Bayesian statistics to provide both classification predictions and uncertainty estimation, but they suffer from high computational overhead associated with random number generation and repeated sample iterations. Furthermore, BNNs are not immediately amenable to acceleration through compute-in-memory architectures due to the frequent memory writes necessary after each RNG operation. To address these challenges, we present an ASIC that integrates 360 fJ/Sample Gaussian RNG directly into the SRAM memory words. This integration reduces RNG overhead and enables fully-parallel compute-in-memory operations for BNNs. The prototype chip achieves 5.12 GSa/s RNG throughput and 102 GOp/s neural network throughput while occupying 0.45 mm2, bringing AI uncertainty estimation to edge computation.
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
May 07, 2024



Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
Mutual Exclusive Modulator for Long-Tailed Recognition
Feb 19, 2023



The long-tailed recognition (LTR) is the task of learning high-performance classifiers given extremely imbalanced training samples between categories. Most of the existing works address the problem by either enhancing the features of tail classes or re-balancing the classifiers to reduce the inductive bias. In this paper, we try to look into the root cause of the LTR task, i.e., training samples for each class are greatly imbalanced, and propose a straightforward solution. We split the categories into three groups, i.e., many, medium and few, according to the number of training images. The three groups of categories are separately predicted to reduce the difficulty for classification. This idea naturally arises a new problem of how to assign a given sample to the right class groups? We introduce a mutual exclusive modulator which can estimate the probability of an image belonging to each group. Particularly, the modulator consists of a light-weight module and learned with a mutual exclusive objective. Hence, the output probabilities of the modulator encode the data volume clues of the training dataset. They are further utilized as prior information to guide the prediction of the classifier. We conduct extensive experiments on multiple datasets, e.g., ImageNet-LT, Place-LT and iNaturalist 2018 to evaluate the proposed approach. Our method achieves competitive performance compared to the state-of-the-art benchmarks.
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023



Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
FDB: Fraud Dataset Benchmark
Aug 31, 2022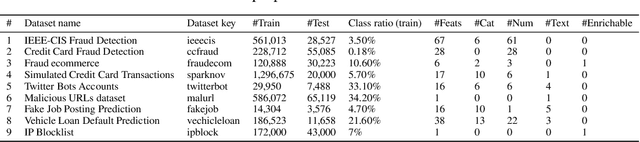


Standardized datasets and benchmarks have spurred innovations in computer vision, natural language processing, multi-modal and tabular settings. We note that, as compared to other well researched fields fraud detection has numerous differences. The differences include a high class imbalance, diverse feature types, frequently changing fraud patterns, and adversarial nature of the problem. Due to these differences, the modeling approaches that are designed for other classification tasks may not work well for the fraud detection. We introduce Fraud Dataset Benchmark (FDB), a compilation of publicly available datasets catered to fraud detection. FDB comprises variety of fraud related tasks, ranging from identifying fraudulent card-not-present transactions, detecting bot attacks, classifying malicious URLs, predicting risk of loan to content moderation. The Python based library from FDB provides consistent API for data loading with standardized training and testing splits. For reference, we also provide baseline evaluations of different modeling approaches on FDB. Considering the increasing popularity of Automated Machine Learning (AutoML) for various research and business problems, we used AutoML frameworks for our baseline evaluations. For fraud prevention, the organizations that operate with limited resources and lack ML expertise often hire a team of investigators, use blocklists and manual rules, all of which are inefficient and do not scale well. Such organizations can benefit from AutoML solutions that are easy to deploy in production and pass the bar of fraud prevention requirements. We hope that FDB helps in the development of customized fraud detection techniques catered to different fraud modus operandi (MOs) as well as in the improvement of AutoML systems that can work well for all datasets in the benchmark.
Pyramid Fusion Transformer for Semantic Segmentation
Jan 11, 2022
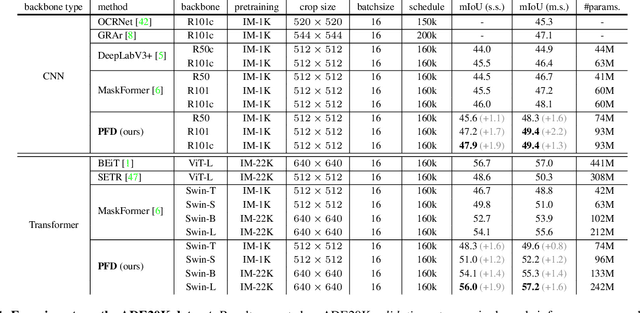
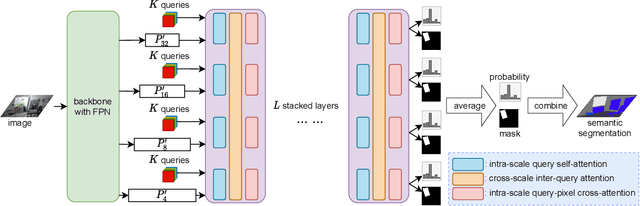
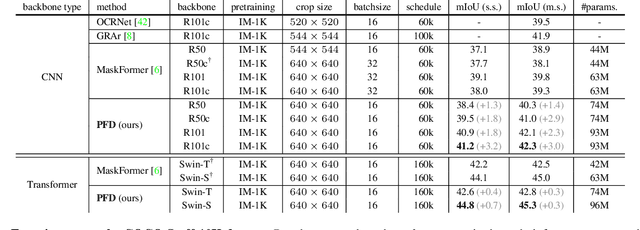
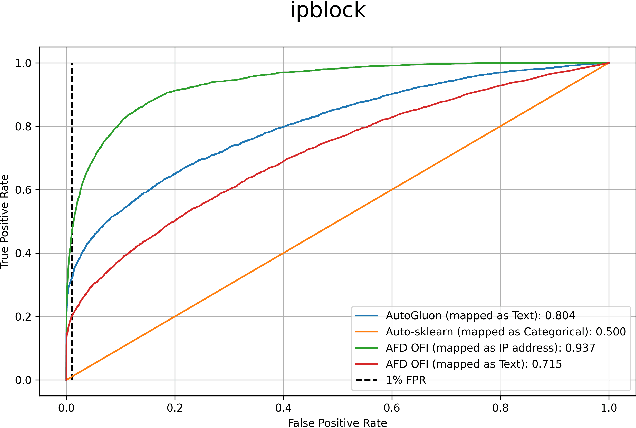
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.
Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation
Sep 06, 2021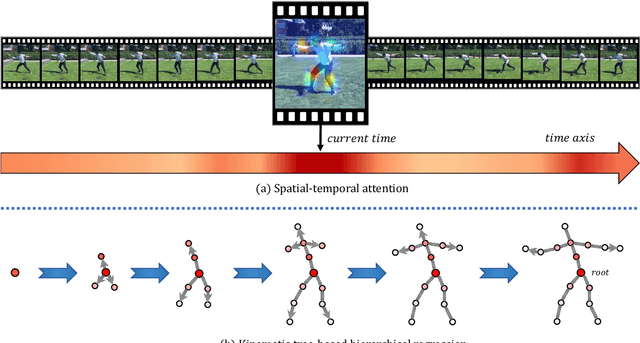
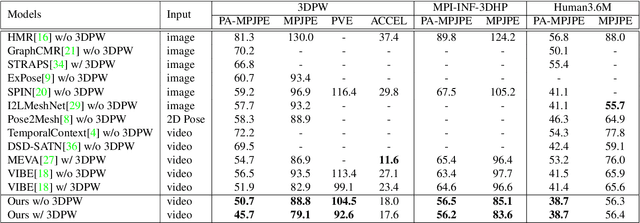
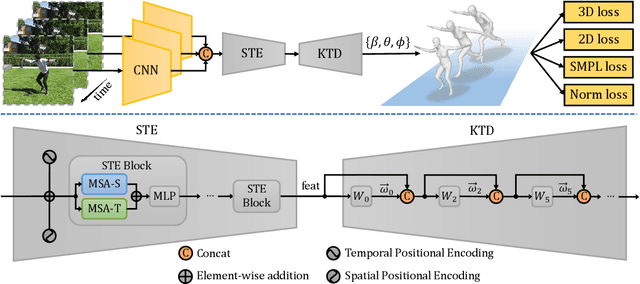
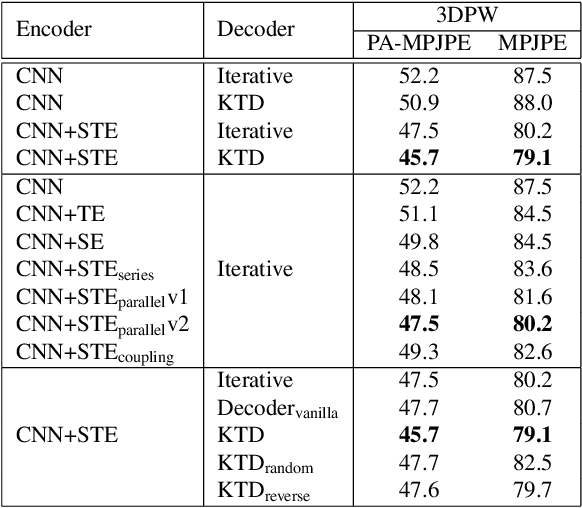
3D human shape and pose estimation is the essential task for human motion analysis, which is widely used in many 3D applications. However, existing methods cannot simultaneously capture the relations at multiple levels, including spatial-temporal level and human joint level. Therefore they fail to make accurate predictions in some hard scenarios when there is cluttered background, occlusion, or extreme pose. To this end, we propose Multi-level Attention Encoder-Decoder Network (MAED), including a Spatial-Temporal Encoder (STE) and a Kinematic Topology Decoder (KTD) to model multi-level attentions in a unified framework. STE consists of a series of cascaded blocks based on Multi-Head Self-Attention, and each block uses two parallel branches to learn spatial and temporal attention respectively. Meanwhile, KTD aims at modeling the joint level attention. It regards pose estimation as a top-down hierarchical process similar to SMPL kinematic tree. With the training set of 3DPW, MAED outperforms previous state-of-the-art methods by 6.2, 7.2, and 2.4 mm of PA-MPJPE on the three widely used benchmarks 3DPW, MPI-INF-3DHP, and Human3.6M respectively. Our code is available at https://github.com/ziniuwan/maed.