 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed2Scale: A Self-Evolving Data Engine for Embodied AI via Small to Large Model Synergy and Multimodal Evaluation
Mar 09, 2026Existing data generation methods suffer from exploration limits, embodiment gaps, and low signal-to-noise ratios, leading to performance degradation during self-iteration. To address these challenges, we propose Seed2Scale, a self-evolving data engine that overcomes the data bottleneck through a heterogeneous synergy of "small-model collection, large-model evaluation, and target-model learning". Starting with as few as four seed demonstrations, the engine employs the lightweight Vision-Language-Action model, SuperTiny, as a dedicated collector, leveraging its strong inductive bias for robust exploration in parallel environments. Concurrently, a pre-trained Vision-Language Model is integrated as a Verifer to autonomously perform success/failure judgment and quality scoring for the massive generated trajectories. Seed2Scale effectively mitigates model collapse, ensuring the stability of the self-evolution process. Experimental results demonstrate that Seed2Scale exhibits signifcant scaling potential: as iterations progress, the success rate of the target model shows a robust upward trend, achieving a performance improvement of 131.2%. Furthermore, Seed2Scale signifcantly outperforms existing data augmentation methods, providing a scalable and cost-effective pathway for the large-scale development of Generalist Embodied AI. Project page: https://terminators2025.github.io/Seed2Scale.github.io
MirrorLimb: Implementing hand pose acquisition and robot teleoperation based on RealMirror
Nov 12, 2025In this work, we present a PICO-based robot remote operating framework that enables low-cost, real-time acquisition of hand motion and pose data, outperforming mainstream visual tracking and motion capture solutions in terms of cost-effectiveness. The framework is natively compatible with the RealMirror ecosystem, offering ready-to-use functionality for stable and precise robotic trajectory recording within the Isaac simulation environment, thereby facilitating the construction of Vision-Language-Action (VLA) datasets. Additionally, the system supports real-time teleoperation of a variety of end-effector-equipped robots, including dexterous hands and robotic grippers. This work aims to lower the technical barriers in the study of upper-limb robotic manipulation, thereby accelerating advancements in VLA-related research.
RealMirror: A Comprehensive, Open-Source Vision-Language-Action Platform for Embodied AI
Sep 18, 2025



The emerging field of Vision-Language-Action (VLA) for humanoid robots faces several fundamental challenges, including the high cost of data acquisition, the lack of a standardized benchmark, and the significant gap between simulation and the real world. To overcome these obstacles, we propose RealMirror, a comprehensive, open-source embodied AI VLA platform. RealMirror builds an efficient, low-cost data collection, model training, and inference system that enables end-to-end VLA research without requiring a real robot. To facilitate model evolution and fair comparison, we also introduce a dedicated VLA benchmark for humanoid robots, featuring multiple scenarios, extensive trajectories, and various VLA models. Furthermore, by integrating generative models and 3D Gaussian Splatting to reconstruct realistic environments and robot models, we successfully demonstrate zero-shot Sim2Real transfer, where models trained exclusively on simulation data can perform tasks on a real robot seamlessly, without any fine-tuning. In conclusion, with the unification of these critical components, RealMirror provides a robust framework that significantly accelerates the development of VLA models for humanoid robots. Project page: https://terminators2025.github.io/RealMirror.github.io
Mutual Exclusive Modulator for Long-Tailed Recognition
Feb 19, 2023



The long-tailed recognition (LTR) is the task of learning high-performance classifiers given extremely imbalanced training samples between categories. Most of the existing works address the problem by either enhancing the features of tail classes or re-balancing the classifiers to reduce the inductive bias. In this paper, we try to look into the root cause of the LTR task, i.e., training samples for each class are greatly imbalanced, and propose a straightforward solution. We split the categories into three groups, i.e., many, medium and few, according to the number of training images. The three groups of categories are separately predicted to reduce the difficulty for classification. This idea naturally arises a new problem of how to assign a given sample to the right class groups? We introduce a mutual exclusive modulator which can estimate the probability of an image belonging to each group. Particularly, the modulator consists of a light-weight module and learned with a mutual exclusive objective. Hence, the output probabilities of the modulator encode the data volume clues of the training dataset. They are further utilized as prior information to guide the prediction of the classifier. We conduct extensive experiments on multiple datasets, e.g., ImageNet-LT, Place-LT and iNaturalist 2018 to evaluate the proposed approach. Our method achieves competitive performance compared to the state-of-the-art benchmarks.
Robust End-to-End Offline Chinese Handwriting Text Page Spotter with Text Kernel
Jul 04, 2021
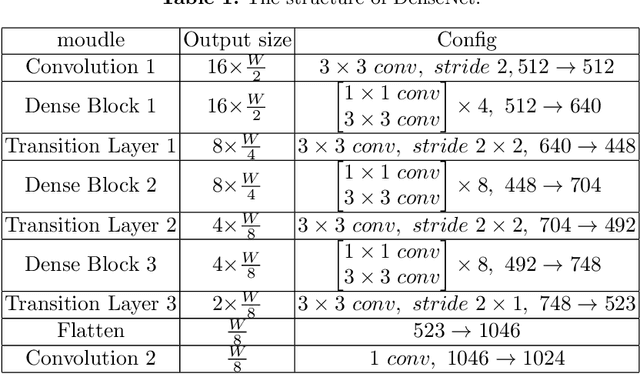
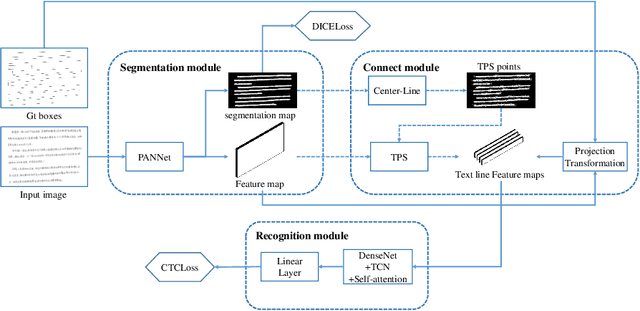
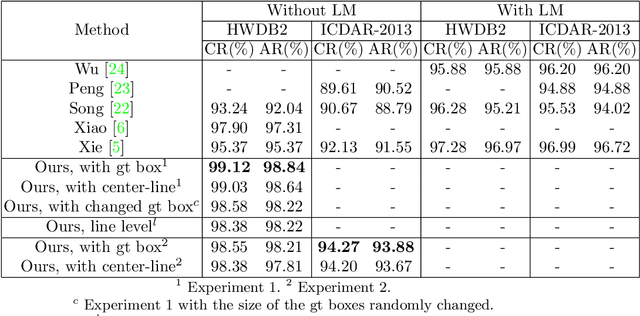
Offline Chinese handwriting text recognition is a long-standing research topic in the field of pattern recognition. In previous studies, text detection and recognition are separated, which leads to the fact that text recognition is highly dependent on the detection results. In this paper, we propose a robust end-to-end Chinese text page spotter framework. It unifies text detection and text recognition with text kernel that integrates global text feature information to optimize the recognition from multiple scales, which reduces the dependence of detection and improves the robustness of the system. Our method achieves state-of-the-art results on the CASIA-HWDB2.0-2.2 dataset and ICDAR-2013 competition dataset. Without any language model, the correct rates are 99.12% and 94.27% for line-level recognition, and 99.03% and 94.20% for page-level recognition, respectively.