 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diffusion-Based Framework for Occluded Object Movement
Apr 02, 2025Seamlessly moving objects within a scene is a common requirement for image editing, but it is still a challenge for existing editing methods. Especially for real-world images, the occlusion situation further increases the difficulty. The main difficulty is that the occluded portion needs to be completed before movement can proceed. To leverage the real-world knowledge embedded in the pre-trained diffusion models, we propose a Diffusion-based framework specifically designed for Occluded Object Movement, named DiffOOM. The proposed DiffOOM consists of two parallel branches that perform object de-occlusion and movement simultaneously. The de-occlusion branch utilizes a background color-fill strategy and a continuously updated object mask to focus the diffusion process on completing the obscured portion of the target object. Concurrently, the movement branch employs latent optimization to place the completed object in the target location and adopts local text-conditioned guidance to integrate the object into new surroundings appropriately. Extensive evaluations demonstrate the superior performance of our method, which is further validated by a comprehensive user study.
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
Mar 30, 2025



Large-scale pre-trained diffusion models are becoming increasingly popular in solving the Real-World Image Super-Resolution (Real-ISR) problem because of their rich generative priors. The recent development of diffusion transformer (DiT) has witnessed overwhelming performance over the traditional UNet-based architecture in image generation, which also raises the question: Can we adopt the advanced DiT-based diffusion model for Real-ISR? To this end, we propose our DiT4SR, one of the pioneering works to tame the large-scale DiT model for Real-ISR. Instead of directly injecting embeddings extracted from low-resolution (LR) images like ControlNet, we integrate the LR embeddings into the original attention mechanism of DiT, allowing for the bidirectional flow of information between the LR latent and the generated latent. The sufficient interaction of these two streams allows the LR stream to evolve with the diffusion process, producing progressively refined guidance that better aligns with the generated latent at each diffusion step. Additionally, the LR guidance is injected into the generated latent via a cross-stream convolution layer, compensating for DiT's limited ability to capture local information. These simple but effective designs endow the DiT model with superior performance in Real-ISR, which is demonstrated by extensive experiments. Project Page: https://adam-duan.github.io/projects/dit4sr/.
DeblurDiff: Real-World Image Deblurring with Generative Diffusion Models
Feb 06, 2025



Diffusion models have achieved significant progress in image generation. The pre-trained Stable Diffusion (SD) models are helpful for image deblurring by providing clear image priors. However, directly using a blurry image or pre-deblurred one as a conditional control for SD will either hinder accurate structure extraction or make the results overly dependent on the deblurring network. In this work, we propose a Latent Kernel Prediction Network (LKPN) to achieve robust real-world image deblurring. Specifically, we co-train the LKPN in latent space with conditional diffusion. The LKPN learns a spatially variant kernel to guide the restoration of sharp images in the latent space. By applying element-wise adaptive convolution (EAC), the learned kernel is utilized to adaptively process the input feature, effectively preserving the structural information of the input. This process thereby more effectively guides the generative process of Stable Diffusion (SD), enhancing both the deblurring efficacy and the quality of detail reconstruction. Moreover, the results at each diffusion step are utilized to iteratively estimate the kernels in LKPN to better restore the sharp latent by EAC. This iterative refinement enhances the accuracy and robustness of the deblurring process. Extensive experimental results demonstrate that the proposed method outperforms state-of-the-art image deblurring methods on both benchmark and real-world images.
Semantic Segmentation Prior for Diffusion-Based Real-World Super-Resolution
Dec 04, 2024



Real-world image super-resolution (Real-ISR) has achieved a remarkable leap by leveraging large-scale text-to-image models, enabling realistic image restoration from given recognition textual prompts. However, these methods sometimes fail to recognize some salient objects, resulting in inaccurate semantic restoration in these regions. Additionally, the same region may have a strong response to more than one prompt and it will lead to semantic ambiguity for image super-resolution. To alleviate the above two issues, in this paper, we propose to consider semantic segmentation as an additional control condition into diffusion-based image super-resolution. Compared to textual prompt conditions, semantic segmentation enables a more comprehensive perception of salient objects within an image by assigning class labels to each pixel. It also mitigates the risks of semantic ambiguities by explicitly allocating objects to their respective spatial regions. In practice, inspired by the fact that image super-resolution and segmentation can benefit each other, we propose SegSR which introduces a dual-diffusion framework to facilitate interaction between the image super-resolution and segmentation diffusion models. Specifically, we develop a Dual-Modality Bridge module to enable updated information flow between these two diffusion models, achieving mutual benefit during the reverse diffusion process. Extensive experiments show that SegSR can generate realistic images while preserving semantic structures more effectively.
Deep Richardson-Lucy Deconvolution for Low-Light Image Deblurring
Aug 10, 2023



Images taken under the low-light condition often contain blur and saturated pixels at the same time. Deblurring images with saturated pixels is quite challenging. Because of the limited dynamic range, the saturated pixels are usually clipped in the imaging process and thus cannot be modeled by the linear blur model. Previous methods use manually designed smooth functions to approximate the clipping procedure. Their deblurring processes often require empirically defined parameters, which may not be the optimal choices for different images. In this paper, we develop a data-driven approach to model the saturated pixels by a learned latent map. Based on the new model, the non-blind deblurring task can be formulated into a maximum a posterior (MAP) problem, which can be effectively solved by iteratively computing the latent map and the latent image. Specifically, the latent map is computed by learning from a map estimation network (MEN), and the latent image estimation process is implemented by a Richardson-Lucy (RL)-based updating scheme. To estimate high-quality deblurred images without amplified artifacts, we develop a prior estimation network (PEN) to obtain prior information, which is further integrated into the RL scheme. Experimental results demonstrate that the proposed method performs favorably against state-of-the-art algorithms both quantitatively and qualitatively on synthetic and real-world images.
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023



Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
Low-Dose CT Denoising Using a Structure-Preserving Kernel Prediction Network
May 31, 2021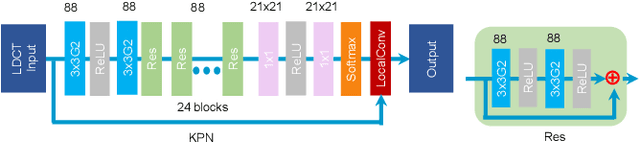
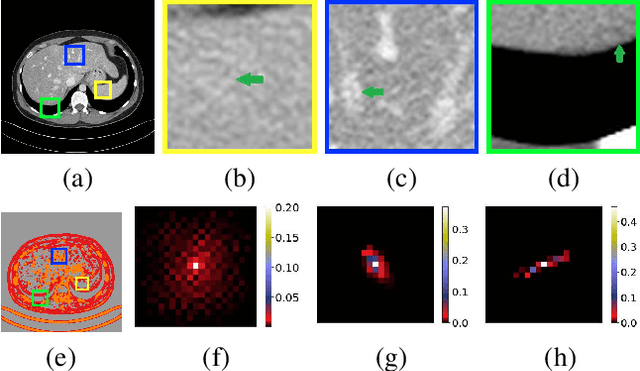


Low-dose CT has been a key diagnostic imaging modality to reduce the potential risk of radiation overdose to patient health. Despite recent advances, CNN-based approaches typically apply filters in a spatially invariant way and adopt similar pixel-level losses, which treat all regions of the CT image equally and can be inefficient when fine-grained structures coexist with non-uniformly distributed noises. To address this issue, we propose a Structure-preserving Kernel Prediction Network (StructKPN) that combines the kernel prediction network with a structure-aware loss function that utilizes the pixel gradient statistics and guides the model towards spatially-variant filters that enhance noise removal, prevent over-smoothing and preserve detailed structures for different regions in CT imaging. Extensive experiments demonstrated that our approach achieved superior performance on both synthetic and non-synthetic datasets, and better preserves structures that are highly desired in clinical screening and low-dose protocol optimization.
Efficient Deep Image Denoising via Class Specific Convolution
Mar 02, 2021


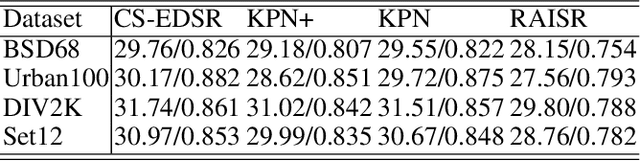
Deep neural networks have been widely used in image denoising during the past few years. Even though they achieve great success on this problem, they are computationally inefficient which makes them inappropriate to be implemented in mobile devices. In this paper, we propose an efficient deep neural network for image denoising based on pixel-wise classification. Despite using a computationally efficient network cannot effectively remove the noises from any content, it is still capable to denoise from a specific type of pattern or texture. The proposed method follows such a divide and conquer scheme. We first use an efficient U-net to pixel-wisely classify pixels in the noisy image based on the local gradient statistics. Then we replace part of the convolution layers in existing denoising networks by the proposed Class Specific Convolution layers (CSConv) which use different weights for different classes of pixels. Quantitative and qualitative evaluations on public datasets demonstrate that the proposed method can reduce the computational costs without sacrificing the performance compared to state-of-the-art algorithms.
Image Quality Assessment for Perceptual Image Restoration: A New Dataset, Benchmark and Metric
Nov 30, 2020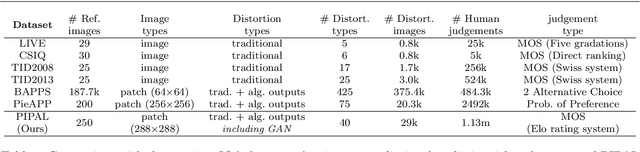

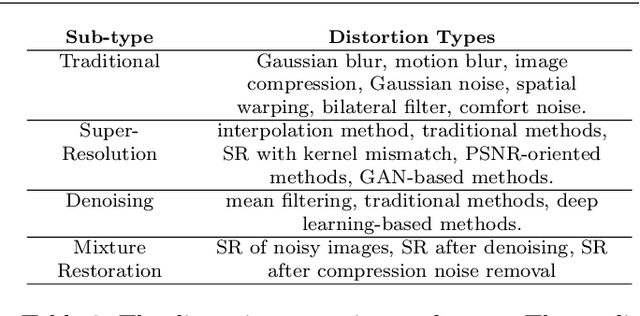

Image quality assessment (IQA) is the key factor for the fast development of image restoration (IR) algorithms. The most recent perceptual IR algorithms based on generative adversarial networks (GANs) have brought in significant improvement on visual performance, but also pose great challenges for quantitative evaluation. Notably, we observe an increasing inconsistency between perceptual quality and the evaluation results. We present two questions: Can existing IQA methods objectively evaluate recent IR algorithms? With the focus on beating current benchmarks, are we getting better IR algorithms? To answer the questions and promote the development of IQA methods, we contribute a large-scale IQA dataset, called Perceptual Image Processing ALgorithms (PIPAL) dataset. Especially, this dataset includes the results of GAN-based IR algorithms, which are missing in previous datasets. We collect more than 1.13 million human judgments to assign subjective scores for PIPAL images using the more reliable Elo system. Based on PIPAL, we present new benchmarks for both IQA and SR methods. Our results indicate that existing IQA methods cannot fairly evaluate GAN-based IR algorithms. While using appropriate evaluation methods is important, IQA methods should also be updated along with the development of IR algorithms. At last, we shed light on how to improve the IQA performance on GAN-based distortion. Inspired by the find that the existing IQA methods have an unsatisfactory performance on the GAN-based distortion partially because of their low tolerance to spatial misalignment, we propose to improve the performance of an IQA network on GAN-based distortion by explicitly considering this misalignment. We propose the Space Warping Difference Network, which includes the novel l_2 pooling layers and Space Warping Difference layers. Experiments demonstrate the effectiveness of the proposed method.
PIPAL: a Large-Scale Image Quality Assessment Dataset for Perceptual Image Restoration
Jul 23, 2020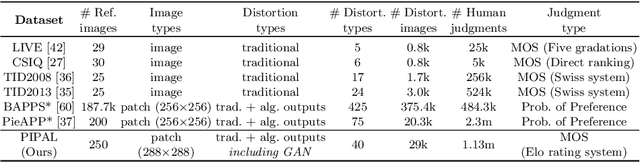


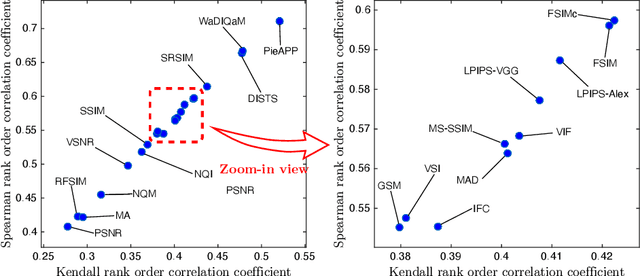
Image quality assessment (IQA) is the key factor for the fast development of image restoration (IR) algorithms. The most recent IR methods based on Generative Adversarial Networks (GANs) have achieved significant improvement in visual performance, but also presented great challenges for quantitative evaluation. Notably, we observe an increasing inconsistency between perceptual quality and the evaluation results. Then we raise two questions: (1) Can existing IQA methods objectively evaluate recent IR algorithms? (2) When focus on beating current benchmarks, are we getting better IR algorithms? To answer these questions and promote the development of IQA methods, we contribute a large-scale IQA dataset, called Perceptual Image Processing Algorithms (PIPAL) dataset. Especially, this dataset includes the results of GAN-based methods, which are missing in previous datasets. We collect more than 1.13 million human judgments to assign subjective scores for PIPAL images using the more reliable "Elo system". Based on PIPAL, we present new benchmarks for both IQA and super-resolution methods. Our results indicate that existing IQA methods cannot fairly evaluate GAN-based IR algorithms. While using appropriate evaluation methods is important, IQA methods should also be updated along with the development of IR algorithms. At last, we improve the performance of IQA networks on GAN-based distortions by introducing anti-aliasing pooling. Experiments show the effectiveness of the proposed method.