 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatarMakeup: Realistic Makeup Transfer for 3D Animatable Head Avatars
Jul 03, 2025Similar to facial beautification in real life, 3D virtual avatars require personalized customization to enhance their visual appeal, yet this area remains insufficiently explored. Although current 3D Gaussian editing methods can be adapted for facial makeup purposes, these methods fail to meet the fundamental requirements for achieving realistic makeup effects: 1) ensuring a consistent appearance during drivable expressions, 2) preserving the identity throughout the makeup process, and 3) enabling precise control over fine details. To address these, we propose a specialized 3D makeup method named AvatarMakeup, leveraging a pretrained diffusion model to transfer makeup patterns from a single reference photo of any individual. We adopt a coarse-to-fine idea to first maintain the consistent appearance and identity, and then to refine the details. In particular, the diffusion model is employed to generate makeup images as supervision. Due to the uncertainties in diffusion process, the generated images are inconsistent across different viewpoints and expressions. Therefore, we propose a Coherent Duplication method to coarsely apply makeup to the target while ensuring consistency across dynamic and multiview effects. Coherent Duplication optimizes a global UV map by recoding the averaged facial attributes among the generated makeup images. By querying the global UV map, it easily synthesizes coherent makeup guidance from arbitrary views and expressions to optimize the target avatar. Given the coarse makeup avatar, we further enhance the makeup by incorporating a Refinement Module into the diffusion model to achieve high makeup quality. Experiments demonstrate that AvatarMakeup achieves state-of-the-art makeup transfer quality and consistency throughout animation.
Fast Extrinsic Calibration for Multiple Inertial Measurement Units in Visual-Inertial System
Sep 24, 2024



In this paper, we propose a fast extrinsic calibration method for fusing multiple inertial measurement units (MIMU) to improve visual-inertial odometry (VIO) localization accuracy. Currently, data fusion algorithms for MIMU highly depend on the number of inertial sensors. Based on the assumption that extrinsic parameters between inertial sensors are perfectly calibrated, the fusion algorithm provides better localization accuracy with more IMUs, while neglecting the effect of extrinsic calibration error. Our method builds two non-linear least-squares problems to estimate the MIMU relative position and orientation separately, independent of external sensors and inertial noises online estimation. Then we give the general form of the virtual IMU (VIMU) method and propose its propagation on manifold. We perform our method on datasets, our self-made sensor board, and board with different IMUs, validating the superiority of our method over competing methods concerning speed, accuracy, and robustness. In the simulation experiment, we show that only fusing two IMUs with our calibration method to predict motion can rival nine IMUs. Real-world experiments demonstrate better localization accuracy of the VIO integrated with our calibration method and VIMU propagation on manifold.
DreamLCM: Towards High-Quality Text-to-3D Generation via Latent Consistency Model
Aug 06, 2024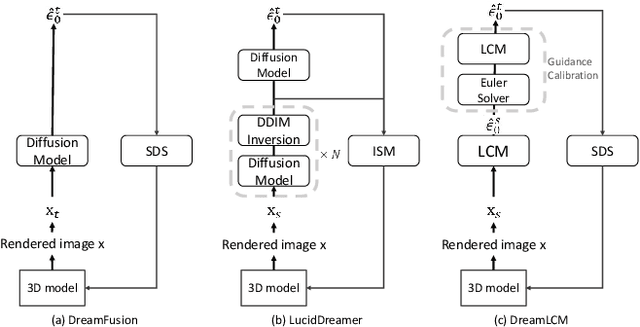
Recently, the text-to-3D task has developed rapidly due to the appearance of the SDS method. However, the SDS method always generates 3D objects with poor quality due to the over-smooth issue. This issue is attributed to two factors: 1) the DDPM single-step inference produces poor guidance gradients; 2) the randomness from the input noises and timesteps averages the details of the 3D contents.In this paper, to address the issue, we propose DreamLCM which incorporates the Latent Consistency Model (LCM). DreamLCM leverages the powerful image generation capabilities inherent in LCM, enabling generating consistent and high-quality guidance, i.e., predicted noises or images. Powered by the improved guidance, the proposed method can provide accurate and detailed gradients to optimize the target 3D models.In addition, we propose two strategies to enhance the generation quality further. Firstly, we propose a guidance calibration strategy, utilizing Euler Solver to calibrate the guidance distribution to accelerate 3D models to converge. Secondly, we propose a dual timestep strategy, increasing the consistency of guidance and optimizing 3D models from geometry to appearance in DreamLCM. Experiments show that DreamLCM achieves state-of-the-art results in both generation quality and training efficiency. The code is available at https://github.com/1YimingZhong/DreamLCM.
Structure-Aware Consensus Network on Graphs with Few Labeled Nodes
Jul 02, 2024



Graph node classification with few labeled nodes presents significant challenges due to limited supervision. Conventional methods often exploit the graph in a transductive learning manner. They fail to effectively utilize the abundant unlabeled data and the structural information inherent in graphs. To address these issues, we introduce a Structure-Aware Consensus Network (SACN) from three perspectives. Firstly, SACN leverages a novel structure-aware consensus learning strategy between two strongly augmented views. The proposed strategy can fully exploit the potentially useful information of the unlabeled nodes and the structural information of the entire graph. Secondly, SACN uniquely integrates the graph's structural information to achieve strong-to-strong consensus learning, improving the utilization of unlabeled data while maintaining multiview learning. Thirdly, unlike two-branch graph neural network-based methods, SACN is designed for multiview feature learning within a single-branch architecture. Furthermore, a class-aware pseudolabel selection strategy helps address class imbalance and achieve effective weak-to-strong supervision. Extensive experiments on three benchmark datasets demonstrate SACN's superior performance in node classification tasks, particularly at very low label rates, outperforming state-of-the-art methods while maintaining computational simplicity.The source code is available at https://github.com/kunzhan/SACN
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Jun 14, 2024



Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Exploring the Intersection of Complex Aesthetics and Generative AI for Promoting Cultural Creativity in Rural China after the Post-Pandemic Era
Sep 05, 2023


This paper explores using generative AI and aesthetics to promote cultural creativity in rural China amidst COVID-19's impact. Through literature reviews, case studies, surveys, and text analysis, it examines art and technology applications in rural contexts and identifies key challenges. The study finds artworks often fail to resonate locally, while reliance on external artists limits sustainability. Hence, nurturing grassroots "artist villagers" through AI is proposed. Our approach involves training machine learning on subjective aesthetics to generate culturally relevant content. Interactive AI media can also boost tourism while preserving heritage. This pioneering research puts forth original perspectives on the intersection of AI and aesthetics to invigorate rural culture. It advocates holistic integration of technology and emphasizes AI's potential as a creative enabler versus replacement. Ultimately, it lays the groundwork for further exploration of leveraging AI innovations to empower rural communities. This timely study contributes to growing interest in emerging technologies to address critical issues facing rural China.
$\mathcal{G}^2Pxy$: Generative Open-Set Node Classification on Graphs with Proxy Unknowns
Aug 10, 2023Node classification is the task of predicting the labels of unlabeled nodes in a graph. State-of-the-art methods based on graph neural networks achieve excellent performance when all labels are available during training. But in real-life, models are often applied on data with new classes, which can lead to massive misclassification and thus significantly degrade performance. Hence, developing open-set classification methods is crucial to determine if a given sample belongs to a known class. Existing methods for open-set node classification generally use transductive learning with part or all of the features of real unseen class nodes to help with open-set classification. In this paper, we propose a novel generative open-set node classification method, i.e. $\mathcal{G}^2Pxy$, which follows a stricter inductive learning setting where no information about unknown classes is available during training and validation. Two kinds of proxy unknown nodes, inter-class unknown proxies and external unknown proxies are generated via mixup to efficiently anticipate the distribution of novel classes. Using the generated proxies, a closed-set classifier can be transformed into an open-set one, by augmenting it with an extra proxy classifier. Under the constraints of both cross entropy loss and complement entropy loss, $\mathcal{G}^2Pxy$ achieves superior effectiveness for unknown class detection and known class classification, which is validated by experiments on benchmark graph datasets. Moreover, $\mathcal{G}^2Pxy$ does not have specific requirement on the GNN architecture and shows good generalizations.
Entropy Neural Estimation for Graph Contrastive Learning
Jul 26, 2023



Contrastive learning on graphs aims at extracting distinguishable high-level representations of nodes. In this paper, we theoretically illustrate that the entropy of a dataset can be approximated by maximizing the lower bound of the mutual information across different views of a graph, \ie, entropy is estimated by a neural network. Based on this finding, we propose a simple yet effective subset sampling strategy to contrast pairwise representations between views of a dataset. In particular, we randomly sample nodes and edges from a given graph to build the input subset for a view. Two views are fed into a parameter-shared Siamese network to extract the high-dimensional embeddings and estimate the information entropy of the entire graph. For the learning process, we propose to optimize the network using two objectives, simultaneously. Concretely, the input of the contrastive loss function consists of positive and negative pairs. Our selection strategy of pairs is different from previous works and we present a novel strategy to enhance the representation ability of the graph encoder by selecting nodes based on cross-view similarities. We enrich the diversity of the positive and negative pairs by selecting highly similar samples and totally different data with the guidance of cross-view similarity scores, respectively. We also introduce a cross-view consistency constraint on the representations generated from the different views. This objective guarantees the learned representations are consistent across views from the perspective of the entire graph. We conduct extensive experiments on seven graph benchmarks, and the proposed approach achieves competitive performance compared to the current state-of-the-art methods. The source code will be publicly released once this paper is accepted.
* ACM MM 2023 accepted
Improving Semi-Supervised Semantic Segmentation with Dual-Level Siamese Structure Network
Jul 26, 2023Semi-supervised semantic segmentation (SSS) is an important task that utilizes both labeled and unlabeled data to reduce expenses on labeling training examples. However, the effectiveness of SSS algorithms is limited by the difficulty of fully exploiting the potential of unlabeled data. To address this, we propose a dual-level Siamese structure network (DSSN) for pixel-wise contrastive learning. By aligning positive pairs with a pixel-wise contrastive loss using strong augmented views in both low-level image space and high-level feature space, the proposed DSSN is designed to maximize the utilization of available unlabeled data. Additionally, we introduce a novel class-aware pseudo-label selection strategy for weak-to-strong supervision, which addresses the limitations of most existing methods that do not perform selection or apply a predefined threshold for all classes. Specifically, our strategy selects the top high-confidence prediction of the weak view for each class to generate pseudo labels that supervise the strong augmented views. This strategy is capable of taking into account the class imbalance and improving the performance of long-tailed classes. Our proposed method achieves state-of-the-art results on two datasets, PASCAL VOC 2012 and Cityscapes, outperforming other SSS algorithms by a significant margin.
* ACM MM 2023 accpeted