 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
Jun 15, 2026Vision-Language-Action (VLA) models benefit from large-scale and diverse embodied data, yet scaling robot trajectory collection is costly and labor-intensive. Recent advances show that large-scale egocentric human videos provide complementary real-world supervision in pretraining. However, joint training on human and robot data remains challenging due to divergences in action spaces, embodiment structures, temporal dynamics, and supervision quality. We introduce ACE-EGO-0, a unified VLA pretraining framework jointly leveraging heterogeneous data sources. To extract large-scale pretraining supervision from egocentric human videos, we build a scalable egocentric video-to-action pipeline that converts raw human videos into robot-format pseudo-action trajectories. To make these labels comparable with robot demonstrations, ACE-EGO-0 uses a unified action representation based on camera-space actions, morphology conditioning, and time-aligned action chunking. To robustly leverage noisy pseudo-action supervision from egocentric human videos, we formulate a reliability-aware training objective with a human auxiliary loss that concentrates supervision on reliable signals. We instantiate ACE-EGO-0 on 4.53K hours of robot and simulation data, together with 1.48K hours of pseudo-action-labeled egocentric human data. Experiments show that incorporating large-scale human supervision under reliability-aware weighting consistently improves both unified joint pretraining and supervised fine-tuning. ACE-EGO-0 achieves state-of-the-art performance on RoboCasa GR1 TableTop and RoboTwin 2.0, while demonstrating strong transfer to real-world bimanual manipulation.
Edit-Based Refinement for Parallel Masked Diffusion Language Models
May 10, 2026Masked diffusion language models enable parallel token generation and offer improved decoding efficiency over autoregressive models. However, their performance degrades significantly when generating multiple tokens simultaneously, due to a mismatch between token-level training objectives and joint sequence consistency. In this paper, we propose ME-DLM, an edit-based refinement framework that augments diffusion generation with lightweight post-editing steps. After producing an initial complete response, the model refines it through minimal edit operations, including replacement, deletion, and insertion, conditioned on the full sequence. Training supervision is derived from edit distance, providing a deterministic signal under a fixed canonicalization scheme for learning minimal corrections. This approach encourages sequence-level consistency through globally conditioned edits while preserving the efficiency benefits of parallel diffusion decoding. Extensive experiments demonstrate that ME-DLM improves the quality and robustness of multi-token parallel generation. In particular, when built upon LLaDA, our method achieves consistent gains of 11.6 points on HumanEval and 33.6 points on GSM8K while using one-eighth of the total diffusion steps. Code is available at https://github.com/renhouxing/ME-DLM.
Towards Robust Real-World Spreadsheet Understanding with Multi-Agent Multi-Format Reasoning
Apr 14, 2026Spreadsheets are central to real-world applications such as enterprise reporting, auditing, and scientific data management. Despite their ubiquity, existing large language model based approaches typically treat tables as plain text, overlooking critical layout cues and visual semantics. Moreover, real-world spreadsheets are often massive in scale, exceeding the input length that LLMs can efficiently process. To address these challenges, we propose SpreadsheetAgent, a two-stage multi-agent framework for spreadsheet understanding that adopts a step-by-step reading and reasoning paradigm. Instead of loading the entire spreadsheet at once, SpreadsheetAgent incrementally interprets localized regions through multiple modalities, including code execution results, images, and LaTeX tables. The method first constructs a structural sketch and row/column summaries, and then performs task-driven reasoning over this intermediate representation in the Solving Stage. To further enhance reliability, we design a verification module that validates extracted structures via targeted inspections, reducing error propagation and ensuring trustworthy inputs for downstream reasoning. Extensive experiments on two spreadsheet datasets demonstrate the effectiveness of our approach. With GPT-OSS-120B, SpreadsheetAgent achieves 38.16% on Spreadsheet Bench, outperforming the ChatGPT Agent baseline (35.27%) by 2.89 absolute points. These results highlight the potential of SpreadsheetAgent to advance robust and scalable spreadsheet understanding in real-world applications. Code is available at https://github.com/renhouxing/SpreadsheetAgent.git.
Alignment with Fill-In-the-Middle for Enhancing Code Generation
Aug 27, 2025The code generation capabilities of Large Language Models (LLMs) have advanced applications like tool invocation and problem-solving. However, improving performance in code-related tasks remains challenging due to limited training data that is verifiable with accurate test cases. While Direct Preference Optimization (DPO) has shown promise, existing methods for generating test cases still face limitations. In this paper, we propose a novel approach that splits code snippets into smaller, granular blocks, creating more diverse DPO pairs from the same test cases. Additionally, we introduce the Abstract Syntax Tree (AST) splitting and curriculum training method to enhance the DPO training. Our approach demonstrates significant improvements in code generation tasks, as validated by experiments on benchmark datasets such as HumanEval (+), MBPP (+), APPS, LiveCodeBench, and BigCodeBench. Code and data are available at https://github.com/SenseLLM/StructureCoder.
WebGen-Bench: Evaluating LLMs on Generating Interactive and Functional Websites from Scratch
May 06, 2025
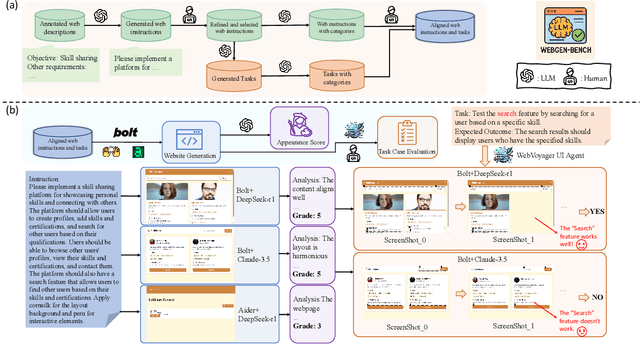
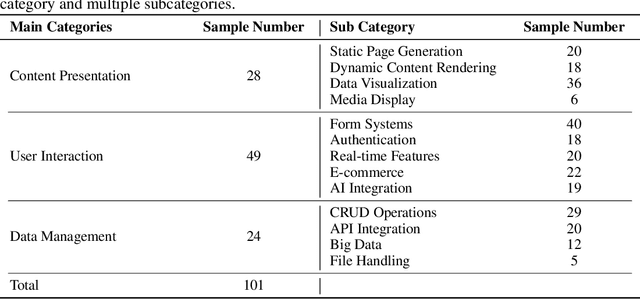
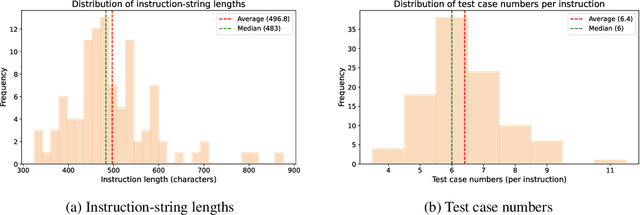
LLM-based agents have demonstrated great potential in generating and managing code within complex codebases. In this paper, we introduce WebGen-Bench, a novel benchmark designed to measure an LLM-based agent's ability to create multi-file website codebases from scratch. It contains diverse instructions for website generation, created through the combined efforts of human annotators and GPT-4o. These instructions span three major categories and thirteen minor categories, encompassing nearly all important types of web applications. To assess the quality of the generated websites, we use GPT-4o to generate test cases targeting each functionality described in the instructions, and then manually filter, adjust, and organize them to ensure accuracy, resulting in 647 test cases. Each test case specifies an operation to be performed on the website and the expected result after the operation. To automate testing and improve reproducibility, we employ a powerful web-navigation agent to execute tests on the generated websites and determine whether the observed responses align with the expected results. We evaluate three high-performance code-agent frameworks, Bolt.diy, OpenHands, and Aider, using multiple proprietary and open-source LLMs as engines. The best-performing combination, Bolt.diy powered by DeepSeek-R1, achieves only 27.8\% accuracy on the test cases, highlighting the challenging nature of our benchmark. Additionally, we construct WebGen-Instruct, a training set consisting of 6,667 website-generation instructions. Training Qwen2.5-Coder-32B-Instruct on Bolt.diy trajectories generated from a subset of this training set achieves an accuracy of 38.2\%, surpassing the performance of the best proprietary model.