 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmbodied: A Foundation Model with Enhanced Geometric and Physical Cues for Large-Scale Embodied Environments
Apr 20, 2026Vision-Language-Action (VLA) models drive next-generation autonomous systems, but training them requires scalable, high-quality annotations from complex environments. Current cloud pipelines rely on generic vision-language models (VLMs) that lack geometric reasoning and domain semantics due to their 2D image-text pretraining. To address this mismatch, we propose XEmbodied, a cloud-side foundation model that endows VLMs with intrinsic 3D geometric awareness and interaction with physical cues (e.g., occupancy grids, 3D boxes). Instead of treating geometry as auxiliary input, XEmbodied integrates geometric representations via a structured 3D Adapter and distills physical signals into context tokens using an Efficient Image-Embodied Adapter. Through progressive domain curriculum and reinforcement learning post-training, XEmbodied preserves general capabilities while demonstrating robust performance across 18 public benchmarks. It significantly improves spatial reasoning, traffic semantics, embodied affordance, and out-of-distribution generalization for large-scale scenario mining and embodied VQA.
Sim2Real-AD: A Modular Sim-to-Real Framework for Deploying VLM-Guided Reinforcement Learning in Real-World Autonomous Driving
Apr 03, 2026Deploying reinforcement learning policies trained in simulation to real autonomous vehicles remains a fundamental challenge, particularly for VLM-guided RL frameworks whose policies are typically learned with simulator-native observations and simulator-coupled action semantics that are unavailable on physical platforms. This paper presents Sim2Real-AD, a modular framework for zero-shot sim-to-real transfer of CARLA-trained VLM-guided RL policies to full-scale vehicles without any real-world RL training data. The framework decomposes the transfer problem into four components: a Geometric Observation Bridge (GOB) that converts monocular front-view images into simulator-compatible bird's-eye-view (BEV) observations, a Physics-Aware Action Mapping (PAM) that translates policy outputs into platform-agnostic physical commands, a Two-Phase Progressive Training (TPT) strategy that stabilizes adaptation by separating action-space and observation-space transfer, and a Real-time Deployment Pipeline (RDP) that integrates perception, policy inference, control conversion, and safety monitoring for closed-loop execution. Simulation experiments show that the framework preserves the relative performance ordering of representative RL algorithms across different reward paradigms and validate the contribution of each module. Zero-shot deployment on a full-scale Ford E-Transit achieves success rates of 90%, 80%, and 75% in car-following, obstacle avoidance, and stop-sign interaction scenarios, respectively. To the best of our knowledge, this study is among the first to demonstrate zero-shot closed-loop deployment of a CARLA-trained VLM-guided RL policy on a full-scale real vehicle without any real-world RL training data. The demo video and code are available at: https://zilin-huang.github.io/Sim2Real-AD-website/.
V2X-QA: A Comprehensive Reasoning Dataset and Benchmark for Multimodal Large Language Models in Autonomous Driving Across Ego, Infrastructure, and Cooperative Views
Apr 03, 2026Multimodal large language models (MLLMs) have shown strong potential for autonomous driving, yet existing benchmarks remain largely ego-centric and therefore cannot systematically assess model performance in infrastructure-centric and cooperative driving conditions. In this work, we introduce V2X-QA, a real-world dataset and benchmark for evaluating MLLMs across vehicle-side, infrastructure-side, and cooperative viewpoints. V2X-QA is built around a view-decoupled evaluation protocol that enables controlled comparison under vehicle-only, infrastructure-only, and cooperative driving conditions within a unified multiple-choice question answering (MCQA) framework. The benchmark is organized into a twelve-task taxonomy spanning perception, prediction, and reasoning and planning, and is constructed through expert-verified MCQA annotation to enable fine-grained diagnosis of viewpoint-dependent capabilities. Benchmark results across ten representative state-of-the-art proprietary and open-source models show that viewpoint accessibility substantially affects performance, and infrastructure-side reasoning supports meaningful macroscopic traffic understanding. Results also indicate that cooperative reasoning remains challenging since it requires cross-view alignment and evidence integration rather than simply additional visual input. To address these challenges, we introduce V2X-MoE, a benchmark-aligned baseline with explicit view routing and viewpoint-specific LoRA experts. The strong performance of V2X-MoE further suggests that explicit viewpoint specialization is a promising direction for multi-view reasoning in autonomous driving. Overall, V2X-QA provides a foundation for studying multi-perspective reasoning, reliability, and cooperative physical intelligence in connected autonomous driving. The dataset and V2X-MoE resources are publicly available at: https://github.com/junwei0001/V2X-QA.
DriveVLM-RL: Neuroscience-Inspired Reinforcement Learning with Vision-Language Models for Safe and Deployable Autonomous Driving
Mar 18, 2026Ensuring safe decision-making in autonomous vehicles remains a fundamental challenge despite rapid advances in end-to-end learning approaches. Traditional reinforcement learning (RL) methods rely on manually engineered rewards or sparse collision signals, which fail to capture the rich contextual understanding required for safe driving and make unsafe exploration unavoidable in real-world settings. Recent vision-language models (VLMs) offer promising semantic understanding capabilities; however, their high inference latency and susceptibility to hallucination hinder direct application to real-time vehicle control. To address these limitations, this paper proposes DriveVLM-RL, a neuroscience-inspired framework that integrates VLMs into RL through a dual-pathway architecture for safe and deployable autonomous driving. The framework decomposes semantic reward learning into a Static Pathway for continuous spatial safety assessment using CLIP-based contrasting language goals, and a Dynamic Pathway for attention-gated multi-frame semantic risk reasoning using a lightweight detector and a large VLM. A hierarchical reward synthesis mechanism fuses semantic signals with vehicle states, while an asynchronous training pipeline decouples expensive VLM inference from environment interaction. All VLM components are used only during offline training and are removed at deployment, ensuring real-time feasibility. Experiments in the CARLA simulator show significant improvements in collision avoidance, task success, and generalization across diverse traffic scenarios, including strong robustness under settings without explicit collision penalties. These results demonstrate that DriveVLM-RL provides a practical paradigm for integrating foundation models into autonomous driving without compromising real-time feasibility. Demo video and code are available at: https://zilin-huang.github.io/DriveVLM-RL-website/
Found-RL: foundation model-enhanced reinforcement learning for autonomous driving
Feb 11, 2026Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP's dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl.
HERMES: A Holistic End-to-End Risk-Aware Multimodal Embodied System with Vision-Language Models for Long-Tail Autonomous Driving
Feb 01, 2026End-to-end autonomous driving models increasingly benefit from large vision--language models for semantic understanding, yet ensuring safe and accurate operation under long-tail conditions remains challenging. These challenges are particularly prominent in long-tail mixed-traffic scenarios, where autonomous vehicles must interact with heterogeneous road users, including human-driven vehicles and vulnerable road users, under complex and uncertain conditions. This paper proposes HERMES, a holistic risk-aware end-to-end multimodal driving framework designed to inject explicit long-tail risk cues into trajectory planning. HERMES employs a foundation-model-assisted annotation pipeline to produce structured Long-Tail Scene Context and Long-Tail Planning Context, capturing hazard-centric cues together with maneuver intent and safety preference, and uses these signals to guide end-to-end planning. HERMES further introduces a Tri-Modal Driving Module that fuses multi-view perception, historical motion cues, and semantic guidance, ensuring risk-aware accurate trajectory planning under long-tail scenarios. Experiments on the real-world long-tail dataset demonstrate that HERMES consistently outperforms representative end-to-end and VLM-driven baselines under long-tail mixed-traffic scenarios. Ablation studies verify the complementary contributions of key components.
V2X-REALM: Vision-Language Model-Based Robust End-to-End Cooperative Autonomous Driving with Adaptive Long-Tail Modeling
Jun 26, 2025Ensuring robust planning and decision-making under rare, diverse, and visually degraded long-tail scenarios remains a fundamental challenge for autonomous driving in urban environments. This issue becomes more critical in cooperative settings, where vehicles and infrastructure jointly perceive and reason across complex environments. To address this challenge, we propose V2X-REALM, a vision-language model (VLM)-based framework with adaptive multimodal learning for robust cooperative autonomous driving under long-tail scenarios. V2X-REALM introduces three core innovations: (i) a prompt-driven long-tail scenario generation and evaluation pipeline that leverages foundation models to synthesize realistic long-tail conditions such as snow and fog across vehicle- and infrastructure-side views, enriching training diversity efficiently; (ii) a gated multi-scenario adaptive attention module that modulates the visual stream using scenario priors to recalibrate ambiguous or corrupted features; and (iii) a multi-task scenario-aware contrastive learning objective that improves multimodal alignment and promotes cross-scenario feature separability. Extensive experiments demonstrate that V2X-REALM significantly outperforms existing baselines in robustness, semantic reasoning, safety, and planning accuracy under complex, challenging driving conditions, advancing the scalability of end-to-end cooperative autonomous driving.
VL-SAFE: Vision-Language Guided Safety-Aware Reinforcement Learning with World Models for Autonomous Driving
May 22, 2025



Reinforcement learning (RL)-based autonomous driving policy learning faces critical limitations such as low sample efficiency and poor generalization; its reliance on online interactions and trial-and-error learning is especially unacceptable in safety-critical scenarios. Existing methods including safe RL often fail to capture the true semantic meaning of "safety" in complex driving contexts, leading to either overly conservative driving behavior or constraint violations. To address these challenges, we propose VL-SAFE, a world model-based safe RL framework with Vision-Language model (VLM)-as-safety-guidance paradigm, designed for offline safe policy learning. Specifically, we construct offline datasets containing data collected by expert agents and labeled with safety scores derived from VLMs. A world model is trained to generate imagined rollouts together with safety estimations, allowing the agent to perform safe planning without interacting with the real environment. Based on these imagined trajectories and safety evaluations, actor-critic learning is conducted under VLM-based safety guidance to optimize the driving policy more safely and efficiently. Extensive evaluations demonstrate that VL-SAFE achieves superior sample efficiency, generalization, safety, and overall performance compared to existing baselines. To the best of our knowledge, this is the first work that introduces a VLM-guided world model-based approach for safe autonomous driving. The demo video and code can be accessed at: https://ys-qu.github.io/vlsafe-website/
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025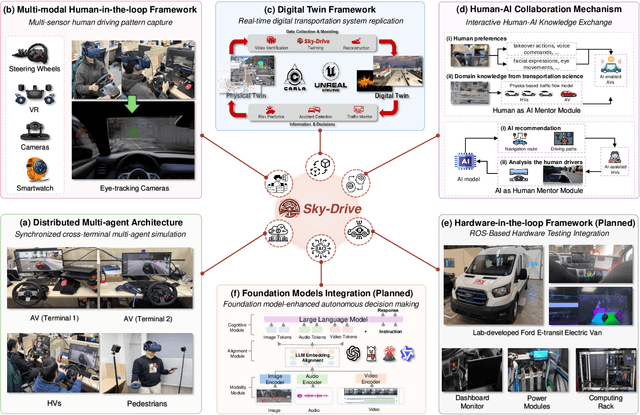
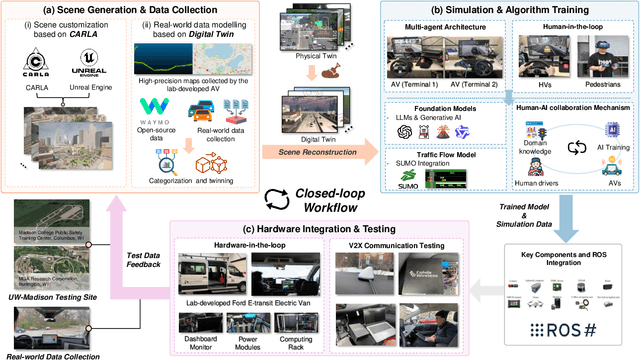
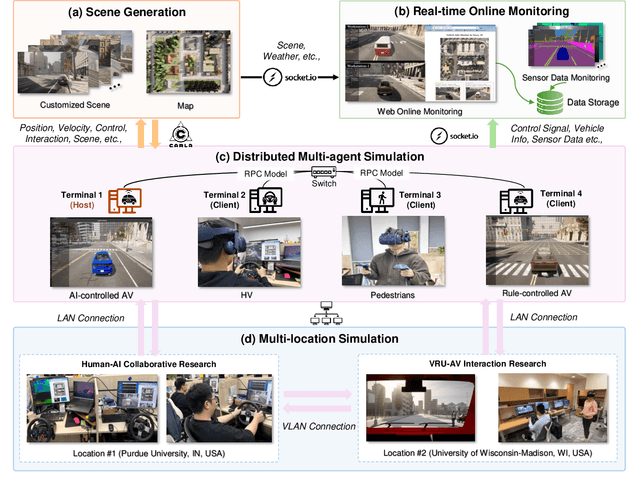
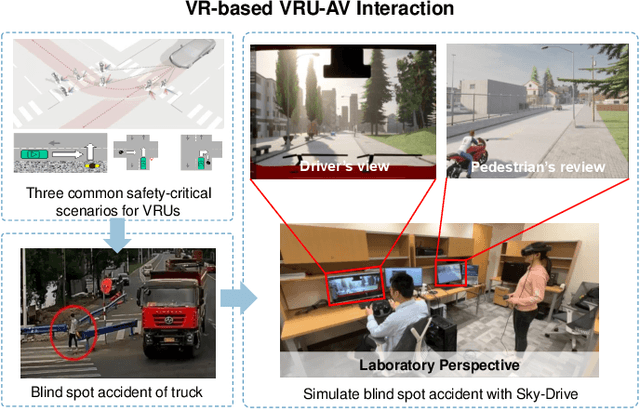
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/