 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
Jan 22, 2026Data preparation aims to denoise raw datasets, uncover cross-dataset relationships, and extract valuable insights from them, which is essential for a wide range of data-centric applications. Driven by (i) rising demands for application-ready data (e.g., for analytics, visualization, decision-making), (ii) increasingly powerful LLM techniques, and (iii) the emergence of infrastructures that facilitate flexible agent construction (e.g., using Databricks Unity Catalog), LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation. By investigating hundreds of recent literature works, this paper presents a systematic review of this evolving landscape, focusing on the use of LLM techniques to prepare data for diverse downstream tasks. First, we characterize the fundamental paradigm shift, from rule-based, model-specific pipelines to prompt-driven, context-aware, and agentic preparation workflows. Next, we introduce a task-centric taxonomy that organizes the field into three major tasks: data cleaning (e.g., standardization, error processing, imputation), data integration (e.g., entity matching, schema matching), and data enrichment (e.g., data annotation, profiling). For each task, we survey representative techniques, and highlight their respective strengths (e.g., improved generalization, semantic understanding) and limitations (e.g., the prohibitive cost of scaling LLMs, persistent hallucinations even in advanced agents, the mismatch between advanced methods and weak evaluation). Moreover, we analyze commonly used datasets and evaluation metrics (the empirical part). Finally, we discuss open research challenges and outline a forward-looking roadmap that emphasizes scalable LLM-data systems, principled designs for reliable agentic workflows, and robust evaluation protocols.
VISTA: Knowledge-Driven Interpretable Vessel Trajectory Imputation via Large Language Models
Jan 11, 2026The Automatic Identification System provides critical information for maritime navigation and safety, yet its trajectories are often incomplete due to signal loss or deliberate tampering. Existing imputation methods emphasize trajectory recovery, paying limited attention to interpretability and failing to provide underlying knowledge that benefits downstream tasks such as anomaly detection and route planning. We propose knowledge-driven interpretable vessel trajectory imputation (VISTA), the first trajectory imputation framework that offers interpretability while simultaneously providing underlying knowledge to support downstream analysis. Specifically, we first define underlying knowledge as a combination of Structured Data-derived Knowledge (SDK) distilled from AIS data and Implicit LLM Knowledge acquired from large-scale Internet corpora. Second, to manage and leverage the SDK effectively at scale, we develop a data-knowledge-data loop that employs a Structured Data-derived Knowledge Graph for SDK extraction and knowledge-driven trajectory imputation. Third, to efficiently process large-scale AIS data, we introduce a workflow management layer that coordinates the end-to-end pipeline, enabling parallel knowledge extraction and trajectory imputation with anomaly handling and redundancy elimination. Experiments on two large AIS datasets show that VISTA is capable of state-of-the-art imputation accuracy and computational efficiency, improving over state-of-the-art baselines by 5%-94% and reducing time cost by 51%-93%, while producing interpretable knowledge cues that benefit downstream tasks. The source code and implementation details of VISTA are publicly available.
Entropy-Guided Token Dropout: Training Autoregressive Language Models with Limited Domain Data
Dec 29, 2025As access to high-quality, domain-specific data grows increasingly scarce, multi-epoch training has become a practical strategy for adapting large language models (LLMs). However, autoregressive models often suffer from performance degradation under repeated data exposure, where overfitting leads to a marked decline in model capability. Through empirical analysis, we trace this degradation to an imbalance in learning dynamics: predictable, low-entropy tokens are learned quickly and come to dominate optimization, while the model's ability to generalize on high-entropy tokens deteriorates with continued training. To address this, we introduce EntroDrop, an entropy-guided token dropout method that functions as structured data regularization. EntroDrop selectively masks low-entropy tokens during training and employs a curriculum schedule to adjust regularization strength in alignment with training progress. Experiments across model scales from 0.6B to 8B parameters show that EntroDrop consistently outperforms standard regularization baselines and maintains robust performance throughout extended multi-epoch training. These findings underscore the importance of aligning regularization with token-level learning dynamics when training on limited data. Our approach offers a promising pathway toward more effective adaptation of LLMs in data-constrained domains.
Generalizable Learning for Massive MIMO CSI Feedback in Unseen Environments
Dec 28, 2025Deep learning is promising to enhance the accuracy and reduce the overhead of channel state information (CSI) feedback, which can boost the capacity of frequency division duplex (FDD) massive multiple-input multiple-output (MIMO) systems. Nevertheless, the generalizability of current deep learning-based CSI feedback algorithms cannot be guaranteed in unseen environments, which induces a high deployment cost. In this paper, the generalizability of deep learning-based CSI feedback is promoted with physics interpretation. Firstly, the distribution shift of the cluster-based channel is modeled, which comprises the multi-cluster structure and single-cluster response. Secondly, the physics-based distribution alignment is proposed to effectively address the distribution shift of the cluster-based channel, which comprises multi-cluster decoupling and fine-grained alignment. Thirdly, the efficiency and robustness of physics-based distribution alignment are enhanced. Explicitly, an efficient multi-cluster decoupling algorithm is proposed based on the Eckart-Young-Mirsky (EYM) theorem to support real-time CSI feedback. Meanwhile, a hybrid criterion to estimate the number of decoupled clusters is designed, which enhances the robustness against channel estimation error. Fourthly, environment-generalizable neural network for CSI feedback (EG-CsiNet) is proposed as a novel learning framework with physics-based distribution alignment. Based on extensive simulations and sim-to-real experiments in various conditions, the proposed EG-CsiNet can robustly reduce the generalization error by more than 3 dB compared to the state-of-the-arts.
MMSRARec: Summarization and Retrieval Augumented Sequential Recommendation Based on Multimodal Large Language Model
Dec 24, 2025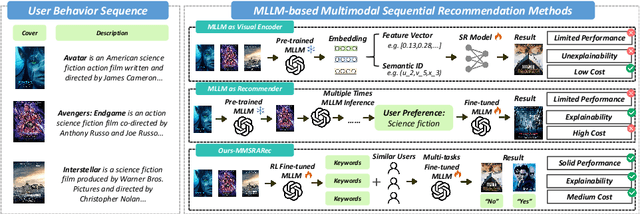
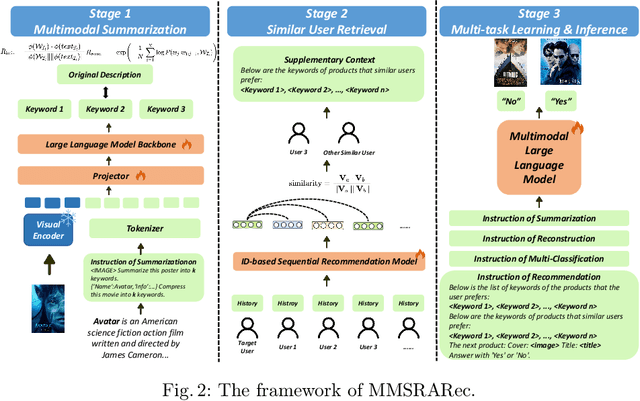


Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated significant potential in recommendation systems. However, the effective application of MLLMs to multimodal sequential recommendation remains unexplored: A) Existing methods primarily leverage the multimodal semantic understanding capabilities of pre-trained MLLMs to generate item embeddings or semantic IDs, thereby enhancing traditional recommendation models. These approaches generate item representations that exhibit limited interpretability, and pose challenges when transferring to language model-based recommendation systems. B) Other approaches convert user behavior sequence into image-text pairs and perform recommendation through multiple MLLM inference, incurring prohibitive computational and time costs. C) Current MLLM-based recommendation systems generally neglect the integration of collaborative signals. To address these limitations while balancing recommendation performance, interpretability, and computational cost, this paper proposes MultiModal Summarization-and-Retrieval-Augmented Sequential Recommendation. Specifically, we first employ MLLM to summarize items into concise keywords and fine-tune the model using rewards that incorporate summary length, information loss, and reconstruction difficulty, thereby enabling adaptive adjustment of the summarization policy. Inspired by retrieval-augmented generation, we then transform collaborative signals into corresponding keywords and integrate them as supplementary context. Finally, we apply supervised fine-tuning with multi-task learning to align the MLLM with the multimodal sequential recommendation. Extensive evaluations on common recommendation datasets demonstrate the effectiveness of MMSRARec, showcasing its capability to efficiently and interpretably understand user behavior histories and item information for accurate recommendations.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
SEED: Spectral Entropy-Guided Evaluation of SpatialTemporal Dependencies for Multivariate Time Series Forecasting
Dec 18, 2025



Effective multivariate time series forecasting often benefits from accurately modeling complex inter-variable dependencies. However, existing attention- or graph-based methods face three key issues: (a) strong temporal self-dependencies are often disrupted by irrelevant variables; (b) softmax normalization ignores and reverses negative correlations; (c) variables struggle to perceive their temporal positions. To address these, we propose \textbf{SEED}, a Spectral Entropy-guided Evaluation framework for spatial-temporal Dependency modeling. SEED introduces a Dependency Evaluator, a key innovation that leverages spectral entropy to dynamically provide a preliminary evaluation of the spatial and temporal dependencies of each variable, enabling the model to adaptively balance Channel Independence (CI) and Channel Dependence (CD) strategies. To account for temporal regularities originating from the influence of other variables rather than intrinsic dynamics, we propose Spectral Entropy-based Fuser to further refine the evaluated dependency weights, effectively separating this part. Moreover, to preserve negative correlations, we introduce a Signed Graph Constructor that enables signed edge weights, overcoming the limitations of softmax. Finally, to help variables perceive their temporal positions and thereby construct more comprehensive spatial features, we introduce the Context Spatial Extractor, which leverages local contextual windows to extract spatial features. Extensive experiments on 12 real-world datasets from various application domains demonstrate that SEED achieves state-of-the-art performance, validating its effectiveness and generality.
JoDiffusion: Jointly Diffusing Image with Pixel-Level Annotations for Semantic Segmentation Promotion
Dec 15, 2025Given the inherently costly and time-intensive nature of pixel-level annotation, the generation of synthetic datasets comprising sufficiently diverse synthetic images paired with ground-truth pixel-level annotations has garnered increasing attention recently for training high-performance semantic segmentation models. However, existing methods necessitate to either predict pseudo annotations after image generation or generate images conditioned on manual annotation masks, which incurs image-annotation semantic inconsistency or scalability problem. To migrate both problems with one stone, we present a novel dataset generative diffusion framework for semantic segmentation, termed JoDiffusion. Firstly, given a standard latent diffusion model, JoDiffusion incorporates an independent annotation variational auto-encoder (VAE) network to map annotation masks into the latent space shared by images. Then, the diffusion model is tailored to capture the joint distribution of each image and its annotation mask conditioned on a text prompt. By doing these, JoDiffusion enables simultaneously generating paired images and semantically consistent annotation masks solely conditioned on text prompts, thereby demonstrating superior scalability. Additionally, a mask optimization strategy is developed to mitigate the annotation noise produced during generation. Experiments on Pascal VOC, COCO, and ADE20K datasets show that the annotated dataset generated by JoDiffusion yields substantial performance improvements in semantic segmentation compared to existing methods.
As If We've Met Before: LLMs Exhibit Certainty in Recognizing Seen Files
Nov 19, 2025The remarkable language ability of Large Language Models (LLMs) stems from extensive training on vast datasets, often including copyrighted material, which raises serious concerns about unauthorized use. While Membership Inference Attacks (MIAs) offer potential solutions for detecting such violations, existing approaches face critical limitations and challenges due to LLMs' inherent overconfidence, limited access to ground truth training data, and reliance on empirically determined thresholds. We present COPYCHECK, a novel framework that leverages uncertainty signals to detect whether copyrighted content was used in LLM training sets. Our method turns LLM overconfidence from a limitation into an asset by capturing uncertainty patterns that reliably distinguish between ``seen" (training data) and ``unseen" (non-training data) content. COPYCHECK further implements a two-fold strategy: (1) strategic segmentation of files into smaller snippets to reduce dependence on large-scale training data, and (2) uncertainty-guided unsupervised clustering to eliminate the need for empirically tuned thresholds. Experiment results show that COPYCHECK achieves an average balanced accuracy of 90.1% on LLaMA 7b and 91.6% on LLaMA2 7b in detecting seen files. Compared to the SOTA baseline, COPYCHECK achieves over 90% relative improvement, reaching up to 93.8\% balanced accuracy. It further exhibits strong generalizability across architectures, maintaining high performance on GPT-J 6B. This work presents the first application of uncertainty for copyright detection in LLMs, offering practical tools for training data transparency.
Why Did Apple Fall To The Ground: Evaluating Curiosity In Large Language Model
Oct 23, 2025Curiosity serves as a pivotal conduit for human beings to discover and learn new knowledge. Recent advancements of large language models (LLMs) in natural language processing have sparked discussions regarding whether these models possess capability of curiosity-driven learning akin to humans. In this paper, starting from the human curiosity assessment questionnaire Five-Dimensional Curiosity scale Revised (5DCR), we design a comprehensive evaluation framework that covers dimensions such as Information Seeking, Thrill Seeking, and Social Curiosity to assess the extent of curiosity exhibited by LLMs. The results demonstrate that LLMs exhibit a stronger thirst for knowledge than humans but still tend to make conservative choices when faced with uncertain environments. We further investigated the relationship between curiosity and thinking of LLMs, confirming that curious behaviors can enhance the model's reasoning and active learning abilities. These findings suggest that LLMs have the potential to exhibit curiosity similar to that of humans, providing experimental support for the future development of learning capabilities and innovative research in LLMs.