 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparate First, Fuse Later: Mitigating Cross-Modal Interference in Audio-Visual LLMs Reasoning with Modality-Specific Chain-of-Thought
May 11, 2026Audio and vision provide complementary evidence for audio-visual question answering, yet current audio-visual large language models may suffer from cross-modal interference: information from one modality misguides the interpretation of another, thereby inducing hallucinations. We attribute this issue to uncontrolled cross-modal interactions during intermediate reasoning. To mitigate this, we propose Separate First, Fuse Later (SFFL), an audio-visual reasoning framework designed to reduce cross-modal interference. SFFL enforces modality-specific chain-of-thought reasoning, producing separate audio and visual reasoning traces and integrating evidence for answering. We construct modality-preference labels via a data pipeline under different modality input settings. We use these labels as an auxiliary reward in reinforcement learning to encourage a instance-dependent preference for modality cues when answering. We further introduce a modality-specific reasoning mechanism that preserves modality isolation during the separated reasoning stage while enabling full access to cross-modal information at the evidence fusion stage. Experiments demonstrate consistent improvements in both accuracy and robustness, yielding an average relative gain of 5.16\% on general AVQA benchmarks and 11.17\% on a cross-modal hallucination benchmark.
Evaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
Compositional Multi-hop Factual Error Correction via Decomposition-and-Injection
May 04, 2026Factual Error Correction (FEC) aims to revise inaccurate text into statements that are factually consistent with external evidence. Although recent methods perform well on single-hop correction, they often treat claims as atomic units and struggle with multi-hop cases that require compositional reasoning across multiple evidence sources. This challenge is further amplified by limited paired data and difficulties in locating semantic errors within complex reasoning chains. We present CECoR (Compositional Error Correction via Reasoning-aware Synthesis), a reasoning-aware framework that introduces a Decomposition and Injection paradigm for compositional error correction. CECoR decomposes multi-hop claims into interpretable reasoning steps and injects controlled perturbations to synthesize high-quality training pairs. A two-stage learning strategy combining supervised fine-tuning and reinforcement learning improves factual accuracy and robustness. Comprehensive evaluations show that CECoR achieves strong performance on multi-hop benchmarks, outperforming both distantly supervised methods and few-shot LLM baselines. It also generalizes effectively to single-hop correction and remains stable under noisy evidence, demonstrating its versatility for real-world factual correction.
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
MSR-HuBERT: Self-supervised Pre-training for Adaptation to Multiple Sampling Rates
Mar 24, 2026Self-supervised learning (SSL) has advanced speech processing. However, existing speech SSL methods typically assume a single sampling rate and struggle with mixed-rate data due to temporal resolution mismatch. To address this limitation, we propose MSRHuBERT, a multi-sampling-rate adaptive pre-training method. Building on HuBERT, we replace its single-rate downsampling CNN with a multi-sampling-rate adaptive downsampling CNN that maps raw waveforms from different sampling rates to a shared temporal resolution without resampling. This design enables unified mixed-rate pre-training and fine-tuning. In experiments spanning 16 to 48 kHz, MSRHuBERT outperforms HuBERT on speech recognition and full-band speech reconstruction, preserving high-frequency detail while modeling low-frequency semantic structure. Moreover, MSRHuBERT retains HuBERT's mask-prediction objective and Transformer encoder, so existing analyses and improvements that were developed for HuBERT can apply directly.
Breaking Data Efficiency Dilemma: A Federated and Augmented Learning Framework For Alzheimer's Disease Detection via Speech
Feb 16, 2026Early diagnosis of Alzheimer's Disease (AD) is crucial for delaying its progression. While AI-based speech detection is non-invasive and cost-effective, it faces a critical data efficiency dilemma due to medical data scarcity and privacy barriers. Therefore, we propose FAL-AD, a novel framework that synergistically integrates federated learning with data augmentation to systematically optimize data efficiency. Our approach delivers three key breakthroughs: First, absolute efficiency improvement through voice conversion-based augmentation, which generates diverse pathological speech samples via cross-category voice-content recombination. Second, collaborative efficiency breakthrough via an adaptive federated learning paradigm, maximizing cross-institutional benefits under privacy constraints. Finally, representational efficiency optimization by an attentive cross-modal fusion model, which achieves fine-grained word-level alignment and acoustic-textual interaction. Evaluated on ADReSSo, FAL-AD achieves a state-of-the-art multi-modal accuracy of 91.52%, outperforming all centralized baselines and demonstrating a practical solution to the data efficiency dilemma. Our source code is publicly available at https://github.com/smileix/fal-ad.
POTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
ASDA: Audio Spectrogram Differential Attention Mechanism for Self-Supervised Representation Learning
Jul 03, 2025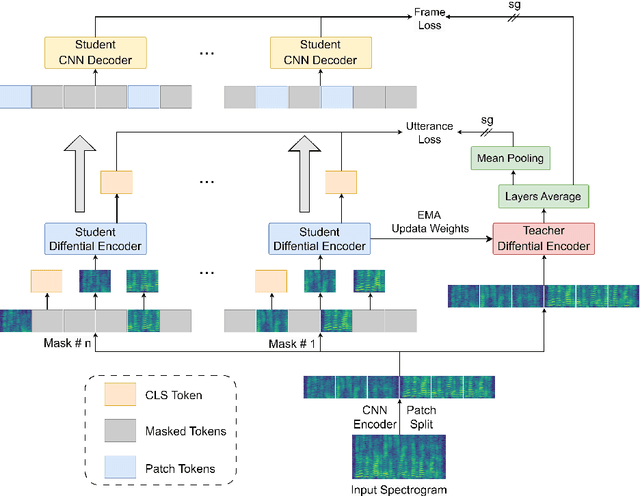
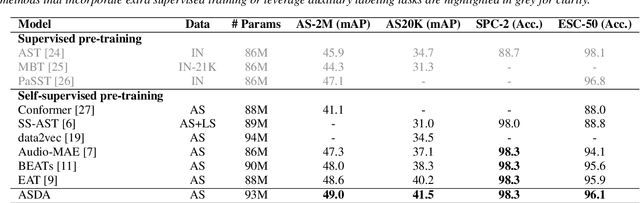
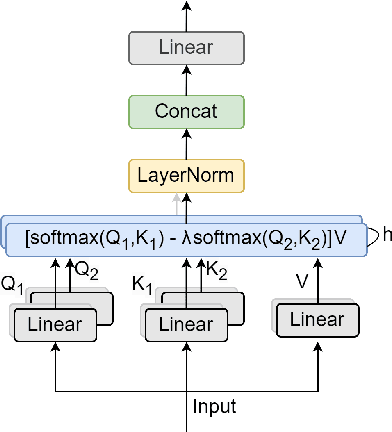
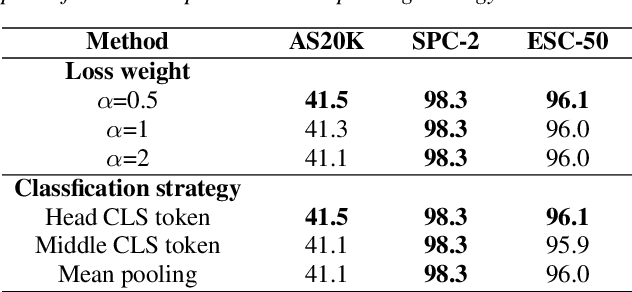
In recent advancements in audio self-supervised representation learning, the standard Transformer architecture has emerged as the predominant approach, yet its attention mechanism often allocates a portion of attention weights to irrelevant information, potentially impairing the model's discriminative ability. To address this, we introduce a differential attention mechanism, which effectively mitigates ineffective attention allocation through the integration of dual-softmax operations and appropriately tuned differential coefficients. Experimental results demonstrate that our ASDA model achieves state-of-the-art (SOTA) performance across multiple benchmarks, including audio classification (49.0% mAP on AS-2M, 41.5% mAP on AS20K), keyword spotting (98.3% accuracy on SPC-2), and environmental sound classification (96.1% accuracy on ESC-50). These results highlight ASDA's effectiveness in audio tasks, paving the way for broader applications.
Integration of Old and New Knowledge for Generalized Intent Discovery: A Consistency-driven Prototype-Prompting Framework
Jun 10, 2025Intent detection aims to identify user intents from natural language inputs, where supervised methods rely heavily on labeled in-domain (IND) data and struggle with out-of-domain (OOD) intents, limiting their practical applicability. Generalized Intent Discovery (GID) addresses this by leveraging unlabeled OOD data to discover new intents without additional annotation. However, existing methods focus solely on clustering unsupervised data while neglecting domain adaptation. Therefore, we propose a consistency-driven prototype-prompting framework for GID from the perspective of integrating old and new knowledge, which includes a prototype-prompting framework for transferring old knowledge from external sources, and a hierarchical consistency constraint for learning new knowledge from target domains. We conducted extensive experiments and the results show that our method significantly outperforms all baseline methods, achieving state-of-the-art results, which strongly demonstrates the effectiveness and generalization of our methods. Our source code is publicly available at https://github.com/smileix/cpp.
Rethinking Contrastive Learning in Graph Anomaly Detection: A Clean-View Perspective
May 23, 2025Graph anomaly detection aims to identify unusual patterns in graph-based data, with wide applications in fields such as web security and financial fraud detection. Existing methods typically rely on contrastive learning, assuming that a lower similarity between a node and its local subgraph indicates abnormality. However, these approaches overlook a crucial limitation: the presence of interfering edges invalidates this assumption, since it introduces disruptive noise that compromises the contrastive learning process. Consequently, this limitation impairs the ability to effectively learn meaningful representations of normal patterns, leading to suboptimal detection performance. To address this issue, we propose a Clean-View Enhanced Graph Anomaly Detection framework (CVGAD), which includes a multi-scale anomaly awareness module to identify key sources of interference in the contrastive learning process. Moreover, to mitigate bias from the one-step edge removal process, we introduce a novel progressive purification module. This module incrementally refines the graph by iteratively identifying and removing interfering edges, thereby enhancing model performance. Extensive experiments on five benchmark datasets validate the effectiveness of our approach.