 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConan: Progressive Learning to Reason Like a Detective over Multi-Scale Visual Evidence
Oct 23, 2025Video reasoning, which requires multi-step deduction across frames, remains a major challenge for multimodal large language models (MLLMs). While reinforcement learning (RL)-based methods enhance reasoning capabilities, they often rely on text-only chains that yield ungrounded or hallucinated conclusions. Conversely, frame-retrieval approaches introduce visual grounding but still struggle with inaccurate evidence localization. To address these challenges, we present Conan, a framework for evidence-grounded multi-step video reasoning. Conan identifies contextual and evidence frames, reasons over cross-frame clues, and adaptively decides when to conclude or explore further. To achieve this, we (1) construct Conan-91K, a large-scale dataset of automatically generated reasoning traces that includes frame identification, evidence reasoning, and action decision, and (2) design a multi-stage progressive cold-start strategy combined with an Identification-Reasoning-Action (AIR) RLVR training framework to jointly enhance multi-step visual reasoning. Extensive experiments on six multi-step reasoning benchmarks demonstrate that Conan surpasses the baseline Qwen2.5-VL-7B-Instruct by an average of over 10% in accuracy, achieving state-of-the-art performance. Furthermore, Conan generalizes effectively to long-video understanding tasks, validating its strong scalability and robustness.
ShortListing Model: A Streamlined SimplexDiffusion for Discrete Variable Generation
Aug 24, 2025Generative modeling of discrete variables is challenging yet crucial for applications in natural language processing and biological sequence design. We introduce the Shortlisting Model (SLM), a novel simplex-based diffusion model inspired by progressive candidate pruning. SLM operates on simplex centroids, reducing generation complexity and enhancing scalability. Additionally, SLM incorporates a flexible implementation of classifier-free guidance, enhancing unconditional generation performance. Extensive experiments on DNA promoter and enhancer design, protein design, character-level and large-vocabulary language modeling demonstrate the competitive performance and strong potential of SLM. Our code can be found at https://github.com/GenSI-THUAIR/SLM
Protenix-Mini: Efficient Structure Predictor via Compact Architecture, Few-Step Diffusion and Switchable pLM
Jul 16, 2025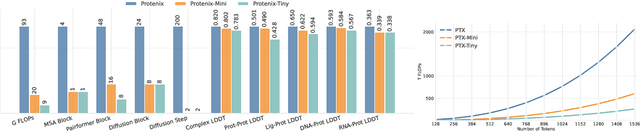



Lightweight inference is critical for biomolecular structure prediction and other downstream tasks, enabling efficient real-world deployment and inference-time scaling for large-scale applications. In this work, we address the challenge of balancing model efficiency and prediction accuracy by making several key modifications, 1) Multi-step AF3 sampler is replaced by a few-step ODE sampler, significantly reducing computational overhead for the diffusion module part during inference; 2) In the open-source Protenix framework, a subset of pairformer or diffusion transformer blocks doesn't make contributions to the final structure prediction, presenting opportunities for architectural pruning and lightweight redesign; 3) A model incorporating an ESM module is trained to substitute the conventional MSA module, reducing MSA preprocessing time. Building on these key insights, we present Protenix-Mini, a compact and optimized model designed for efficient protein structure prediction. This streamlined version incorporates a more efficient architectural design with a two-step Ordinary Differential Equation (ODE) sampling strategy. By eliminating redundant Transformer components and refining the sampling process, Protenix-Mini significantly reduces model complexity with slight accuracy drop. Evaluations on benchmark datasets demonstrate that it achieves high-fidelity predictions, with only a negligible 1 to 5 percent decrease in performance on benchmark datasets compared to its full-scale counterpart. This makes Protenix-Mini an ideal choice for applications where computational resources are limited but accurate structure prediction remains crucial.
SToFM: a Multi-scale Foundation Model for Spatial Transcriptomics
Jul 15, 2025Spatial Transcriptomics (ST) technologies provide biologists with rich insights into single-cell biology by preserving spatial context of cells. Building foundational models for ST can significantly enhance the analysis of vast and complex data sources, unlocking new perspectives on the intricacies of biological tissues. However, modeling ST data is inherently challenging due to the need to extract multi-scale information from tissue slices containing vast numbers of cells. This process requires integrating macro-scale tissue morphology, micro-scale cellular microenvironment, and gene-scale gene expression profile. To address this challenge, we propose SToFM, a multi-scale Spatial Transcriptomics Foundation Model. SToFM first performs multi-scale information extraction on each ST slice, to construct a set of ST sub-slices that aggregate macro-, micro- and gene-scale information. Then an SE(2) Transformer is used to obtain high-quality cell representations from the sub-slices. Additionally, we construct \textbf{SToCorpus-88M}, the largest high-resolution spatial transcriptomics corpus for pretraining. SToFM achieves outstanding performance on a variety of downstream tasks, such as tissue region semantic segmentation and cell type annotation, demonstrating its comprehensive understanding of ST data
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Jul 03, 2025



Despite improvements by length extrapolation, efficient attention and memory modules, handling infinitely long documents with linear complexity without performance degradation during extrapolation remains the ultimate challenge in long-text processing. We directly optimize for long-text tasks in an end-to-end fashion and introduce a novel agent workflow, MemAgent, which reads text in segments and updates the memory using an overwrite strategy. We extend the DAPO algorithm to facilitate training via independent-context multi-conversation generation. MemAgent has demonstrated superb long-context capabilities, being able to extrapolate from an 8K context trained on 32K text to a 3.5M QA task with performance loss < 5% and achieves 95%+ in 512K RULER test.
La RoSA: Enhancing LLM Efficiency via Layerwise Rotated Sparse Activation
Jul 02, 2025



Activation sparsity can reduce the computational overhead and memory transfers during the forward pass of Large Language Model (LLM) inference. Existing methods face limitations, either demanding time-consuming recovery training that hinders real-world adoption, or relying on empirical magnitude-based pruning, which causes fluctuating sparsity and unstable inference speed-up. This paper introduces LaRoSA (Layerwise Rotated Sparse Activation), a novel method for activation sparsification designed to improve LLM efficiency without requiring additional training or magnitude-based pruning. We leverage layerwise orthogonal rotations to transform input activations into rotated forms that are more suitable for sparsification. By employing a Top-K selection approach within the rotated activations, we achieve consistent model-level sparsity and reliable wall-clock time speed-up. LaRoSA is effective across various sizes and types of LLMs, demonstrating minimal performance degradation and robust inference acceleration. Specifically, for LLaMA2-7B at 40% sparsity, LaRoSA achieves a mere 0.17 perplexity gap with a consistent 1.30x wall-clock time speed-up, and reduces the accuracy gap in zero-shot tasks compared to the dense model to just 0.54%, while surpassing TEAL by 1.77% and CATS by 17.14%.
NaviAgent: Bilevel Planning on Tool Dependency Graphs for Function Calling
Jun 24, 2025



LLMs' reliance on static knowledge and fragile tool invocation severely hinders the orchestration of complex, heterogeneous toolchains, particularly at large scales. Existing methods typically use rigid single-path execution, resulting in poor error recovery and exponentially growing search spaces. We introduce NaviAgent, a graph-navigated bilevel planning architecture for robust function calling, comprising a Multi-Path Decider and Graph-Encoded Navigator. As an LLM-powered agent, the Multi-Path Decider defines a four-dimensional decision space and continuously perceives environmental states, dynamically selecting the optimal action to fully cover all tool invocation scenarios. The Graph-Encoded Navigator constructs a Tool Dependency Heterogeneous Graph (TDHG), where node embeddings explicitly fuse API schema structure with historical invocation behavior. It also integrates a novel heuristic search strategy that guides the Decider toward efficient and highly successful toolchains, even for unseen tool combinations. Experiments show that NaviAgent consistently achieves the highest task success rate (TSR) across all foundation models and task complexities, outperforming the average baselines (ReAct, ToolLLM, {\alpha}-UMI) by 13.5%, 16.4%, and 19.0% on Qwen2.5-14B, Qwen2.5-32B, and Deepseek-V3, respectively. Its execution steps are typically within one step of the most efficient baseline, ensuring a strong balance between quality and efficiency. Notably, a fine-tuned Qwen2.5-14B model achieves a TSR of 49.5%, surpassing the much larger 32B model (44.9%) under our architecture. Incorporating the Graph-Encoded Navigator further boosts TSR by an average of 2.4 points, with gains up over 9 points on complex tasks for larger models (Deepseek-V3 and GPT-4o), highlighting its essential role in toolchain orchestration.
Hierarchical and Collaborative LLM-Based Control for Multi-UAV Motion and Communication in Integrated Terrestrial and Non-Terrestrial Networks
Jun 06, 2025



Unmanned aerial vehicles (UAVs) have been widely adopted in various real-world applications. However, the control and optimization of multi-UAV systems remain a significant challenge, particularly in dynamic and constrained environments. This work explores the joint motion and communication control of multiple UAVs operating within integrated terrestrial and non-terrestrial networks that include high-altitude platform stations (HAPS). Specifically, we consider an aerial highway scenario in which UAVs must accelerate, decelerate, and change lanes to avoid collisions and maintain overall traffic flow. Different from existing studies, we propose a novel hierarchical and collaborative method based on large language models (LLMs). In our approach, an LLM deployed on the HAPS performs UAV access control, while another LLM onboard each UAV handles motion planning and control. This LLM-based framework leverages the rich knowledge embedded in pre-trained models to enable both high-level strategic planning and low-level tactical decisions. This knowledge-driven paradigm holds great potential for the development of next-generation 3D aerial highway systems. Experimental results demonstrate that our proposed collaborative LLM-based method achieves higher system rewards, lower operational costs, and significantly reduced UAV collision rates compared to baseline approaches.
Prompting Wireless Networks: Reinforced In-Context Learning for Power Control
Jun 06, 2025To manage and optimize constantly evolving wireless networks, existing machine learning (ML)- based studies operate as black-box models, leading to increased computational costs during training and a lack of transparency in decision-making, which limits their practical applicability in wireless networks. Motivated by recent advancements in large language model (LLM)-enabled wireless networks, this paper proposes ProWin, a novel framework that leverages reinforced in-context learning to design task-specific demonstration Prompts for Wireless Network optimization, relying on the inference capabilities of LLMs without the need for dedicated model training or finetuning. The task-specific prompts are designed to incorporate natural language descriptions of the task description and formulation, enhancing interpretability and eliminating the need for specialized expertise in network optimization. We further propose a reinforced in-context learning scheme that incorporates a set of advisable examples into task-specific prompts, wherein informative examples capturing historical environment states and decisions are adaptively selected to guide current decision-making. Evaluations on a case study of base station power control showcases that the proposed ProWin outperforms reinforcement learning (RL)-based methods, highlighting the potential for next-generation future wireless network optimization.
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
May 26, 2025



Large Language Models (LLMs), such as OpenAI's o1 and DeepSeek's R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.