 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
May 21, 2025



Large reasoning models (LRMs) achieve remarkable performance via long reasoning chains, but often incur excessive computational overhead due to redundant reasoning, especially on simple tasks. In this work, we systematically quantify the upper bounds of LRMs under both Long-Thinking and No-Thinking modes, and uncover the phenomenon of "Internal Self-Recovery Mechanism" where models implicitly supplement reasoning during answer generation. Building on this insight, we propose Adaptive Self-Recovery Reasoning (ASRR), a framework that suppresses unnecessary reasoning and enables implicit recovery. By introducing accuracy-aware length reward regulation, ASRR adaptively allocates reasoning effort according to problem difficulty, achieving high efficiency with negligible performance sacrifice. Experiments across multiple benchmarks and models show that, compared with GRPO, ASRR reduces reasoning budget by up to 32.5% (1.5B) and 25.7% (7B) with minimal accuracy loss (1.2% and 0.6% pass@1), and significantly boosts harmless rates on safety benchmarks (up to +21.7%). Our results highlight the potential of ASRR for enabling efficient, adaptive, and safer reasoning in LRMs.
Seeing Sound, Hearing Sight: Uncovering Modality Bias and Conflict of AI models in Sound Localization
May 16, 2025Imagine hearing a dog bark and turning toward the sound only to see a parked car, while the real, silent dog sits elsewhere. Such sensory conflicts test perception, yet humans reliably resolve them by prioritizing sound over misleading visuals. Despite advances in multimodal AI integrating vision and audio, little is known about how these systems handle cross-modal conflicts or whether they favor one modality. In this study, we systematically examine modality bias and conflict resolution in AI sound localization. We assess leading multimodal models and benchmark them against human performance in psychophysics experiments across six audiovisual conditions, including congruent, conflicting, and absent cues. Humans consistently outperform AI, demonstrating superior resilience to conflicting or missing visuals by relying on auditory information. In contrast, AI models often default to visual input, degrading performance to near chance levels. To address this, we finetune a state-of-the-art model using a stereo audio-image dataset generated via 3D simulations. Even with limited training data, the refined model surpasses existing benchmarks. Notably, it also mirrors human-like horizontal localization bias favoring left-right precision-likely due to the stereo audio structure reflecting human ear placement. These findings underscore how sensory input quality and system architecture shape multimodal representation accuracy.
Unsupervised Radar Point Cloud Enhancement via Arbitrary LiDAR Guided Diffusion Prior
May 15, 2025In industrial automation, radar is a critical sensor in machine perception. However, the angular resolution of radar is inherently limited by the Rayleigh criterion, which depends on both the radar's operating wavelength and the effective aperture of its antenna array.To overcome these hardware-imposed limitations, recent neural network-based methods have leveraged high-resolution LiDAR data, paired with radar measurements, during training to enhance radar point cloud resolution. While effective, these approaches require extensive paired datasets, which are costly to acquire and prone to calibration error. These challenges motivate the need for methods that can improve radar resolution without relying on paired high-resolution ground-truth data. Here, we introduce an unsupervised radar points enhancement algorithm that employs an arbitrary LiDAR-guided diffusion model as a prior without the need for paired training data. Specifically, our approach formulates radar angle estimation recovery as an inverse problem and incorporates prior knowledge through a diffusion model with arbitrary LiDAR domain knowledge. Experimental results demonstrate that our method attains high fidelity and low noise performance compared to traditional regularization techniques. Additionally, compared to paired training methods, it not only achieves comparable performance but also offers improved generalization capability. To our knowledge, this is the first approach that enhances radar points output by integrating prior knowledge via a diffusion model rather than relying on paired training data. Our code is available at https://github.com/yyxr75/RadarINV.
GIFStream: 4D Gaussian-based Immersive Video with Feature Stream
May 12, 2025Immersive video offers a 6-Dof-free viewing experience, potentially playing a key role in future video technology. Recently, 4D Gaussian Splatting has gained attention as an effective approach for immersive video due to its high rendering efficiency and quality, though maintaining quality with manageable storage remains challenging. To address this, we introduce GIFStream, a novel 4D Gaussian representation using a canonical space and a deformation field enhanced with time-dependent feature streams. These feature streams enable complex motion modeling and allow efficient compression by leveraging temporal correspondence and motion-aware pruning. Additionally, we incorporate both temporal and spatial compression networks for end-to-end compression. Experimental results show that GIFStream delivers high-quality immersive video at 30 Mbps, with real-time rendering and fast decoding on an RTX 4090. Project page: https://xdimlab.github.io/GIFStream
Step1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
May 12, 2025While generative artificial intelligence has advanced significantly across text, image, audio, and video domains, 3D generation remains comparatively underdeveloped due to fundamental challenges such as data scarcity, algorithmic limitations, and ecosystem fragmentation. To this end, we present Step1X-3D, an open framework addressing these challenges through: (1) a rigorous data curation pipeline processing >5M assets to create a 2M high-quality dataset with standardized geometric and textural properties; (2) a two-stage 3D-native architecture combining a hybrid VAE-DiT geometry generator with an diffusion-based texture synthesis module; and (3) the full open-source release of models, training code, and adaptation modules. For geometry generation, the hybrid VAE-DiT component produces TSDF representations by employing perceiver-based latent encoding with sharp edge sampling for detail preservation. The diffusion-based texture synthesis module then ensures cross-view consistency through geometric conditioning and latent-space synchronization. Benchmark results demonstrate state-of-the-art performance that exceeds existing open-source methods, while also achieving competitive quality with proprietary solutions. Notably, the framework uniquely bridges the 2D and 3D generation paradigms by supporting direct transfer of 2D control techniques~(e.g., LoRA) to 3D synthesis. By simultaneously advancing data quality, algorithmic fidelity, and reproducibility, Step1X-3D aims to establish new standards for open research in controllable 3D asset generation.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025



Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
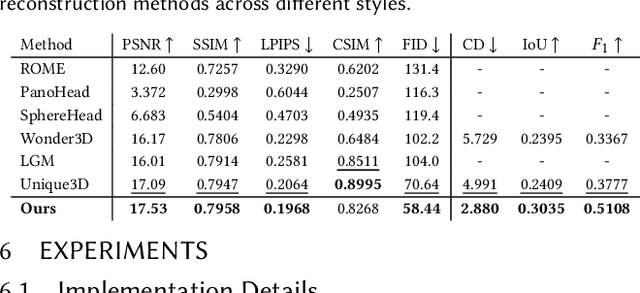
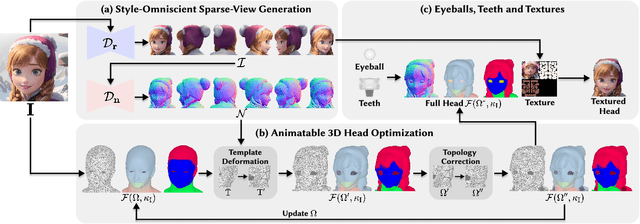
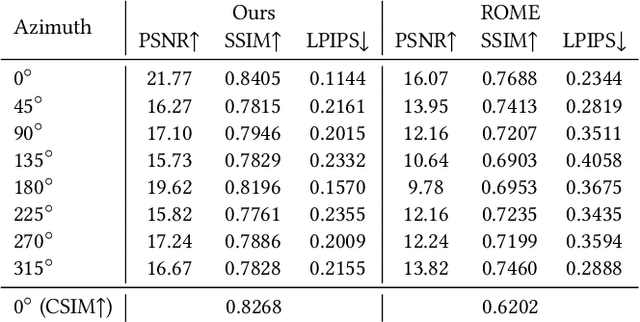
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
Convex Relaxation for Robust Vanishing Point Estimation in Manhattan World
May 07, 2025



Determining the vanishing points (VPs) in a Manhattan world, as a fundamental task in many 3D vision applications, consists of jointly inferring the line-VP association and locating each VP. Existing methods are, however, either sub-optimal solvers or pursuing global optimality at a significant cost of computing time. In contrast to prior works, we introduce convex relaxation techniques to solve this task for the first time. Specifically, we employ a ``soft'' association scheme, realized via a truncated multi-selection error, that allows for joint estimation of VPs' locations and line-VP associations. This approach leads to a primal problem that can be reformulated into a quadratically constrained quadratic programming (QCQP) problem, which is then relaxed into a convex semidefinite programming (SDP) problem. To solve this SDP problem efficiently, we present a globally optimal outlier-robust iterative solver (called \textbf{GlobustVP}), which independently searches for one VP and its associated lines in each iteration, treating other lines as outliers. After each independent update of all VPs, the mutual orthogonality between the three VPs in a Manhattan world is reinforced via local refinement. Extensive experiments on both synthetic and real-world data demonstrate that \textbf{GlobustVP} achieves a favorable balance between efficiency, robustness, and global optimality compared to previous works. The code is publicly available at https://github.com/WU-CVGL/GlobustVP.
A machine learning model for skillful climate system prediction
May 06, 2025Climate system models (CSMs), through integrating cross-sphere interactions among the atmosphere, ocean, land, and cryosphere, have emerged as pivotal tools for deciphering climate dynamics and improving forecasting capabilities. Recent breakthroughs in artificial intelligence (AI)-driven meteorological modeling have demonstrated remarkable success in single-sphere systems and partially spheres coupled systems. However, the development of a fully coupled AI-based climate system model encompassing atmosphere-ocean-land-sea ice interactions has remained an unresolved challenge. This paper introduces FengShun-CSM, an AI-based CSM model that provides 60-day global daily forecasts for 29 critical variables across atmospheric, oceanic, terrestrial, and cryospheric domains. The model significantly outperforms the European Centre for Medium-Range Weather Forecasts (ECMWF) subseasonal-to-seasonal (S2S) model in predicting most variables, particularly precipitation, land surface, and oceanic components. This enhanced capability is primarily attributed to its improved representation of intra-seasonal variability modes, most notably the Madden-Julian Oscillation (MJO). Remarkably, FengShun-CSM exhibits substantial potential in predicting subseasonal extreme events. Such breakthroughs will advance its applications in meteorological disaster mitigation, marine ecosystem conservation, and agricultural productivity enhancement. Furthermore, it validates the feasibility of developing AI-powered CSMs through machine learning technologies, establishing a transformative paradigm for next-generation Earth system modeling.
Optimization of Module Transferability in Single Image Super-Resolution: Universality Assessment and Cycle Residual Blocks
May 06, 2025Deep learning has substantially advanced the Single Image Super-Resolution (SISR). However, existing researches have predominantly focused on raw performance gains, with little attention paid to quantifying the transferability of architectural components. In this paper, we introduce the concept of "Universality" and its associated definitions which extend the traditional notion of "Generalization" to encompass the modules' ease of transferability, thus revealing the relationships between module universality and model generalizability. Then we propose the Universality Assessment Equation (UAE), a metric for quantifying how readily a given module could be transplanted across models. Guided by the UAE results of standard residual blocks and other plug-and-play modules, we further design two optimized modules, Cycle Residual Block (CRB) and Depth-Wise Cycle Residual Block (DCRB). Through comprehensive experiments on natural-scene benchmarks, remote-sensing datasets, extreme-industrial imagery and on-device deployments, we demonstrate that networks embedded with the proposed plug-and-play modules outperform several state-of-the-arts, reaching a PSNR enhancement of up to 0.83dB or enabling a 71.3% reduction in parameters with negligible loss in reconstruction fidelity.