 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirector: Instance-aware Gaussian Splatting for Dynamic Scene Modeling and Understanding
Apr 02, 2026Volumetric video seeks to model dynamic scenes as temporally coherent 4D representations. While recent Gaussian-based approaches achieve impressive rendering fidelity, they primarily emphasize appearance but are largely agnostic to instance-level structure, limiting stable tracking and semantic reasoning in highly dynamic scenarios. In this paper, we present Director, a unified spatio-temporal Gaussian representation that jointly models human performance, high-fidelity rendering, and instance-level semantics. Our key insight is that embedding instance-consistent semantics naturally complements 4D modeling, enabling more accurate scene decomposition while supporting robust dynamic scene understanding. To this end, we leverage temporally aligned instance masks and sentence embeddings derived from Multimodal Large Language Models to supervise the learnable semantic features of each Gaussian via two MLP decoders, enabling language-aligned 4D representations and enforcing identity consistency over time. To enhance temporal stability, we bridge 2D optical flow with 4D Gaussians and finetune their motions, yielding reliable initialization and reducing drift. For the training, we further introduce a geometry-aware SDF constraints, along with regularization terms that enforces surface continuity, enhancing temporal coherence in dynamic foreground modeling. Experiments demonstrate that Director achieves temporally coherent 4D reconstructions while simultaneously enabling instance segmentation and open-vocabulary querying.
SURE: Semi-dense Uncertainty-REfined Feature Matching
Mar 05, 2026Establishing reliable image correspondences is essential for many robotic vision problems. However, existing methods often struggle in challenging scenarios with large viewpoint changes or textureless regions, where incorrect cor- respondences may still receive high similarity scores. This is mainly because conventional models rely solely on fea- ture similarity, lacking an explicit mechanism to estimate the reliability of predicted matches, leading to overconfident errors. To address this issue, we propose SURE, a Semi- dense Uncertainty-REfined matching framework that jointly predicts correspondences and their confidence by modeling both aleatoric and epistemic uncertainties. Our approach in- troduces a novel evidential head for trustworthy coordinate regression, along with a lightweight spatial fusion module that enhances local feature precision with minimal overhead. We evaluated our method on multiple standard benchmarks, where it consistently outperforms existing state-of-the-art semi-dense matching models in both accuracy and efficiency. our code will be available on https://github.com/LSC-ALAN/SURE.
DipLLM: Fine-Tuning LLM for Strategic Decision-making in Diplomacy
Jun 11, 2025



Diplomacy is a complex multiplayer game that requires both cooperation and competition, posing significant challenges for AI systems. Traditional methods rely on equilibrium search to generate extensive game data for training, which demands substantial computational resources. Large Language Models (LLMs) offer a promising alternative, leveraging pre-trained knowledge to achieve strong performance with relatively small-scale fine-tuning. However, applying LLMs to Diplomacy remains challenging due to the exponential growth of possible action combinations and the intricate strategic interactions among players. To address this challenge, we propose DipLLM, a fine-tuned LLM-based agent that learns equilibrium policies for Diplomacy. DipLLM employs an autoregressive factorization framework to simplify the complex task of multi-unit action assignment into a sequence of unit-level decisions. By defining an equilibrium policy within this framework as the learning objective, we fine-tune the model using only 1.5% of the data required by the state-of-the-art Cicero model, surpassing its performance. Our results demonstrate the potential of fine-tuned LLMs for tackling complex strategic decision-making in multiplayer games.
GIFStream: 4D Gaussian-based Immersive Video with Feature Stream
May 12, 2025Immersive video offers a 6-Dof-free viewing experience, potentially playing a key role in future video technology. Recently, 4D Gaussian Splatting has gained attention as an effective approach for immersive video due to its high rendering efficiency and quality, though maintaining quality with manageable storage remains challenging. To address this, we introduce GIFStream, a novel 4D Gaussian representation using a canonical space and a deformation field enhanced with time-dependent feature streams. These feature streams enable complex motion modeling and allow efficient compression by leveraging temporal correspondence and motion-aware pruning. Additionally, we incorporate both temporal and spatial compression networks for end-to-end compression. Experimental results show that GIFStream delivers high-quality immersive video at 30 Mbps, with real-time rendering and fast decoding on an RTX 4090. Project page: https://xdimlab.github.io/GIFStream
Explainable Fuzzy Neural Network with Multi-Fidelity Reinforcement Learning for Micro-Architecture Design Space Exploration
Dec 14, 2024With the continuous advancement of processors, modern micro-architecture designs have become increasingly complex. The vast design space presents significant challenges for human designers, making design space exploration (DSE) algorithms a significant tool for $\mu$-arch design. In recent years, efforts have been made in the development of DSE algorithms, and promising results have been achieved. However, the existing DSE algorithms, e.g., Bayesian Optimization and ensemble learning, suffer from poor interpretability, hindering designers' understanding of the decision-making process. To address this limitation, we propose utilizing Fuzzy Neural Networks to induce and summarize knowledge and insights from the DSE process, enhancing interpretability and controllability. Furthermore, to improve efficiency, we introduce a multi-fidelity reinforcement learning approach, which primarily conducts exploration using cheap but less precise data, thereby substantially diminishing the reliance on costly data. Experimental results show that our method achieves excellent results with a very limited sample budget and successfully surpasses the current state-of-the-art. Our DSE framework is open-sourced and available at https://github.com/fanhanwei/FNN\_MFRL\_ArchDSE/\ .
NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
Apr 02, 2024The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis. As a kind of visual media for 3D scene representation, compression with high rate-distortion performance is an eternal target. Motivated by advances in neural compression and neural field representation, we propose NeRFCodec, an end-to-end NeRF compression framework that integrates non-linear transform, quantization, and entropy coding for memory-efficient scene representation. Since training a non-linear transform directly on a large scale of NeRF feature planes is impractical, we discover that pre-trained neural 2D image codec can be utilized for compressing the features when adding content-specific parameters. Specifically, we reuse neural 2D image codec but modify its encoder and decoder heads, while keeping the other parts of the pre-trained decoder frozen. This allows us to train the full pipeline via supervision of rendering loss and entropy loss, yielding the rate-distortion balance by updating the content-specific parameters. At test time, the bitstreams containing latent code, feature decoder head, and other side information are transmitted for communication. Experimental results demonstrate our method outperforms existing NeRF compression methods, enabling high-quality novel view synthesis with a memory budget of 0.5 MB.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
DORec: Decomposed Object Reconstruction Utilizing 2D Self-Supervised Features
Oct 19, 2023Decomposing a target object from a complex background while reconstructing is challenging. Most approaches acquire the perception for object instances through the use of manual labels, but the annotation procedure is costly. The recent advancements in 2D self-supervised learning have brought new prospects to object-aware representation, yet it remains unclear how to leverage such noisy 2D features for clean decomposition. In this paper, we propose a Decomposed Object Reconstruction (DORec) network based on neural implicit representations. Our key idea is to transfer 2D self-supervised features into masks of two levels of granularity to supervise the decomposition, including a binary mask to indicate the foreground regions and a K-cluster mask to indicate the semantically similar regions. These two masks are complementary to each other and lead to robust decomposition. Experimental results show the superiority of DORec in segmenting and reconstructing the foreground object on various datasets.
SteerNeRF: Accelerating NeRF Rendering via Smooth Viewpoint Trajectory
Dec 15, 2022



Neural Radiance Fields (NeRF) have demonstrated superior novel view synthesis performance but are slow at rendering. To speed up the volume rendering process, many acceleration methods have been proposed at the cost of large memory consumption. To push the frontier of the efficiency-memory trade-off, we explore a new perspective to accelerate NeRF rendering, leveraging a key fact that the viewpoint change is usually smooth and continuous in interactive viewpoint control. This allows us to leverage the information of preceding viewpoints to reduce the number of rendered pixels as well as the number of sampled points along the ray of the remaining pixels. In our pipeline, a low-resolution feature map is rendered first by volume rendering, then a lightweight 2D neural renderer is applied to generate the output image at target resolution leveraging the features of preceding and current frames. We show that the proposed method can achieve competitive rendering quality while reducing the rendering time with little memory overhead, enabling 30FPS at 1080P image resolution with a low memory footprint.
Multi-Scale Spatial Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Jun 27, 2022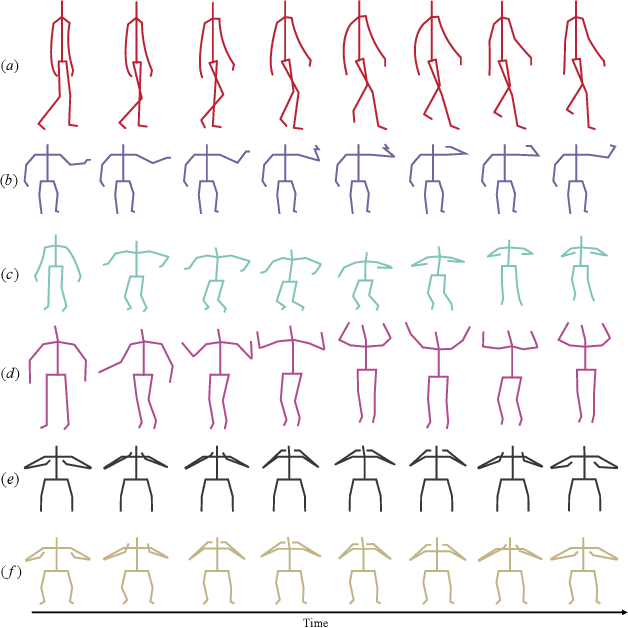
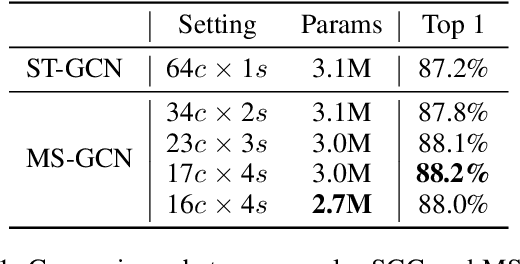
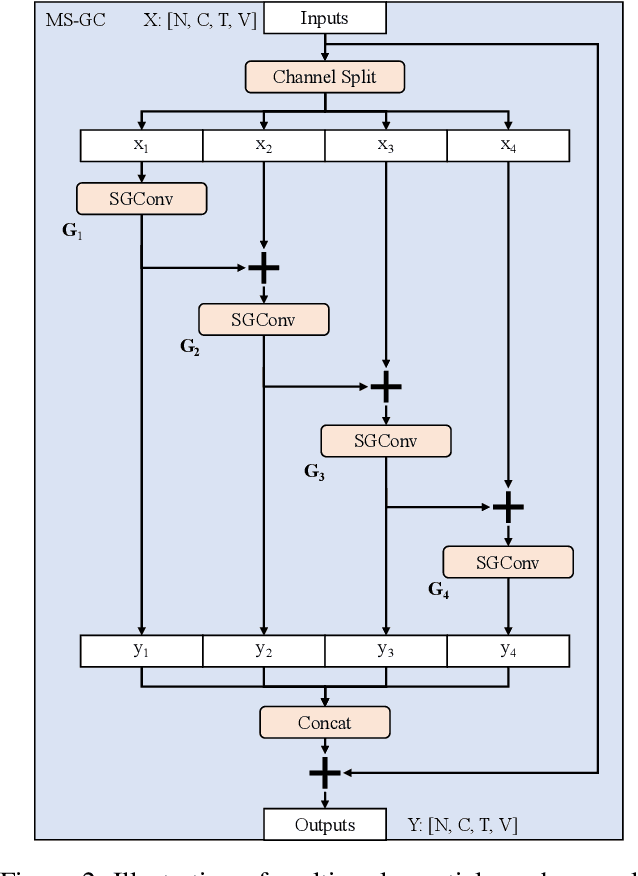
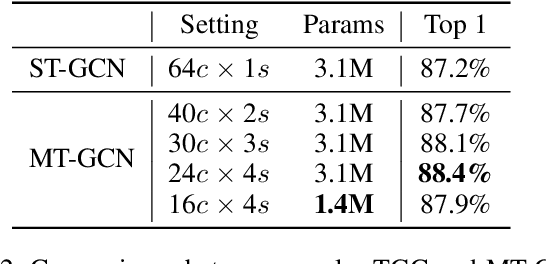
Graph convolutional networks have been widely used for skeleton-based action recognition due to their excellent modeling ability of non-Euclidean data. As the graph convolution is a local operation, it can only utilize the short-range joint dependencies and short-term trajectory but fails to directly model the distant joints relations and long-range temporal information that are vital to distinguishing various actions. To solve this problem, we present a multi-scale spatial graph convolution (MS-GC) module and a multi-scale temporal graph convolution (MT-GC) module to enrich the receptive field of the model in spatial and temporal dimensions. Concretely, the MS-GC and MT-GC modules decompose the corresponding local graph convolution into a set of sub-graph convolution, forming a hierarchical residual architecture. Without introducing additional parameters, the features will be processed with a series of sub-graph convolutions, and each node could complete multiple spatial and temporal aggregations with its neighborhoods. The final equivalent receptive field is accordingly enlarged, which is capable of capturing both short- and long-range dependencies in spatial and temporal domains. By coupling these two modules as a basic block, we further propose a multi-scale spatial temporal graph convolutional network (MST-GCN), which stacks multiple blocks to learn effective motion representations for action recognition. The proposed MST-GCN achieves remarkable performance on three challenging benchmark datasets, NTU RGB+D, NTU-120 RGB+D and Kinetics-Skeleton, for skeleton-based action recognition.