 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBGC: Efficient and Adaptive Graph Coarsening via Granular-ball Computing
Jun 24, 2025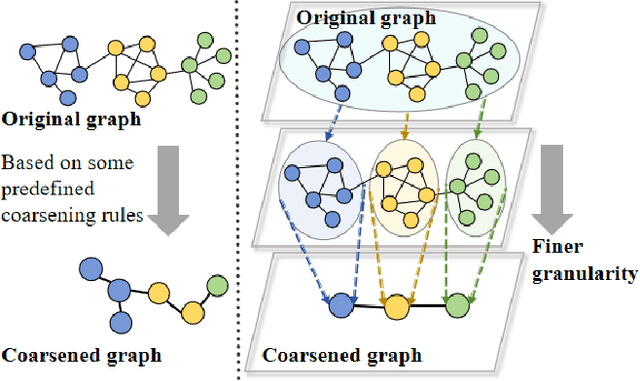
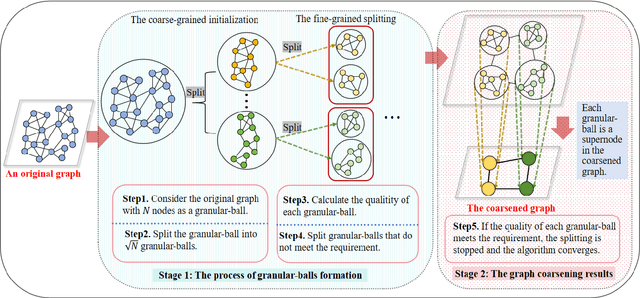

The objective of graph coarsening is to generate smaller, more manageable graphs while preserving key information of the original graph. Previous work were mainly based on the perspective of spectrum-preserving, using some predefined coarsening rules to make the eigenvalues of the Laplacian matrix of the original graph and the coarsened graph match as much as possible. However, they largely overlooked the fact that the original graph is composed of subregions at different levels of granularity, where highly connected and similar nodes should be more inclined to be aggregated together as nodes in the coarsened graph. By combining the multi-granularity characteristics of the graph structure, we can generate coarsened graph at the optimal granularity. To this end, inspired by the application of granular-ball computing in multi-granularity, we propose a new multi-granularity, efficient, and adaptive coarsening method via granular-ball (GBGC), which significantly improves the coarsening results and efficiency. Specifically, GBGC introduces an adaptive granular-ball graph refinement mechanism, which adaptively splits the original graph from coarse to fine into granular-balls of different sizes and optimal granularity, and constructs the coarsened graph using these granular-balls as supernodes. In addition, compared with other state-of-the-art graph coarsening methods, the processing speed of this method can be increased by tens to hundreds of times and has lower time complexity. The accuracy of GBGC is almost always higher than that of the original graph due to the good robustness and generalization of the granular-ball computing, so it has the potential to become a standard graph data preprocessing method.
Well Begun is Half Done: Low-resource Preference Alignment by Weak-to-Strong Decoding
Jun 09, 2025



Large Language Models (LLMs) require alignment with human preferences to avoid generating offensive, false, or meaningless content. Recently, low-resource methods for LLM alignment have been popular, while still facing challenges in obtaining both high-quality and aligned content. Motivated by the observation that the difficulty of generating aligned responses is concentrated at the beginning of decoding, we propose a novel framework, Weak-to-Strong Decoding (WSD), to enhance the alignment ability of base models by the guidance of a small aligned model. The small model first drafts well-aligned beginnings, followed by the large base model to continue the rest, controlled by a well-designed auto-switch mechanism. We also collect a new dataset, GenerAlign, to fine-tune a small-sized Pilot-3B as the draft model, which effectively enhances different base models under the WSD framework to outperform all baseline methods, while avoiding degradation on downstream tasks, termed as the alignment tax. Extensive experiments are further conducted to examine the impact of different settings and time efficiency, as well as analyses on the intrinsic mechanisms of WSD in depth.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
Mar 11, 2025Due to the data-driven nature of current face identity (FaceID) customization methods, all state-of-the-art models rely on large-scale datasets containing millions of high-quality text-image pairs for training. However, none of these datasets are publicly available, which restricts transparency and hinders further advancements in the field. To address this issue, in this paper, we collect and release FaceID-6M, the first large-scale, open-source FaceID dataset containing 6 million high-quality text-image pairs. Filtered from LAION-5B \cite{schuhmann2022laion}, FaceID-6M undergoes a rigorous image and text filtering steps to ensure dataset quality, including resolution filtering to maintain high-quality images and faces, face filtering to remove images that lack human faces, and keyword-based strategy to retain descriptions containing human-related terms (e.g., nationality, professions and names). Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development. We conduct extensive experiments to show the effectiveness of our FaceID-6M, demonstrating that models trained on our FaceID-6M dataset achieve performance that is comparable to, and slightly better than currently available industrial models. Additionally, to support and advance research in the FaceID customization community, we make our code, datasets, and models fully publicly available. Our codes, models, and datasets are available at: https://github.com/ShuheSH/FaceID-6M.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Picky LLMs and Unreliable RMs: An Empirical Study on Safety Alignment after Instruction Tuning
Feb 03, 2025Large language models (LLMs) have emerged as powerful tools for addressing a wide range of general inquiries and tasks. Despite this, fine-tuning aligned LLMs on smaller, domain-specific datasets, critical to adapting them to specialized tasks, can inadvertently degrade their safety alignment, even when the datasets are benign. This phenomenon makes models more susceptible to providing inappropriate responses. In this study, we systematically examine the factors contributing to safety alignment degradation in benign fine-tuning scenarios. Our analysis identifies three critical factors affecting aligned LLMs: answer structure, identity calibration, and role-play. Additionally, we evaluate the reliability of state-of-the-art reward models (RMs), which are often used to guide alignment processes. Our findings reveal that these RMs frequently fail to accurately reflect human preferences regarding safety, underscoring their limitations in practical applications. By uncovering these challenges, our work highlights the complexities of maintaining safety alignment during fine-tuning and offers guidance to help developers balance utility and safety in LLMs. Datasets and fine-tuning code used in our experiments can be found in https://github.com/GuanlinLee/llm_instruction_tuning.
GBFRS: Robust Fuzzy Rough Sets via Granular-ball Computing
Jan 30, 2025



Fuzzy rough set theory is effective for processing datasets with complex attributes, supported by a solid mathematical foundation and closely linked to kernel methods in machine learning. Attribute reduction algorithms and classifiers based on fuzzy rough set theory exhibit promising performance in the analysis of high-dimensional multivariate complex data. However, most existing models operate at the finest granularity, rendering them inefficient and sensitive to noise, especially for high-dimensional big data. Thus, enhancing the robustness of fuzzy rough set models is crucial for effective feature selection. Muiti-garanularty granular-ball computing, a recent development, uses granular-balls of different sizes to adaptively represent and cover the sample space, performing learning based on these granular-balls. This paper proposes integrating multi-granularity granular-ball computing into fuzzy rough set theory, using granular-balls to replace sample points. The coarse-grained characteristics of granular-balls make the model more robust. Additionally, we propose a new method for generating granular-balls, scalable to the entire supervised method based on granular-ball computing. A forward search algorithm is used to select feature sequences by defining the correlation between features and categories through dependence functions. Experiments demonstrate the proposed model's effectiveness and superiority over baseline methods.
Turn That Frown Upside Down: FaceID Customization via Cross-Training Data
Jan 26, 2025



Existing face identity (FaceID) customization methods perform well but are limited to generating identical faces as the input, while in real-world applications, users often desire images of the same person but with variations, such as different expressions (e.g., smiling, angry) or angles (e.g., side profile). This limitation arises from the lack of datasets with controlled input-output facial variations, restricting models' ability to learn effective modifications. To address this issue, we propose CrossFaceID, the first large-scale, high-quality, and publicly available dataset specifically designed to improve the facial modification capabilities of FaceID customization models. Specifically, CrossFaceID consists of 40,000 text-image pairs from approximately 2,000 persons, with each person represented by around 20 images showcasing diverse facial attributes such as poses, expressions, angles, and adornments. During the training stage, a specific face of a person is used as input, and the FaceID customization model is forced to generate another image of the same person but with altered facial features. This allows the FaceID customization model to acquire the ability to personalize and modify known facial features during the inference stage. Experiments show that models fine-tuned on the CrossFaceID dataset retain its performance in preserving FaceID fidelity while significantly improving its face customization capabilities. To facilitate further advancements in the FaceID customization field, our code, constructed datasets, and trained models are fully available to the public.
Aligning Instruction Tuning with Pre-training
Jan 16, 2025



Instruction tuning enhances large language models (LLMs) to follow human instructions across diverse tasks, relying on high-quality datasets to guide behavior. However, these datasets, whether manually curated or synthetically generated, are often narrowly focused and misaligned with the broad distributions captured during pre-training, limiting LLM generalization and effective use of pre-trained knowledge. We propose *Aligning Instruction Tuning with Pre-training* (AITP), a method that bridges this gap by identifying coverage shortfalls in instruction-tuning datasets and rewriting underrepresented pre-training data into high-quality instruction-response pairs. This approach enriches dataset diversity while preserving task-specific objectives. Evaluations on three fully open LLMs across eight benchmarks demonstrate consistent performance improvements with AITP. Ablations highlight the benefits of adaptive data selection, controlled rewriting, and balanced integration, emphasizing the importance of aligning instruction tuning with pre-training distributions to unlock the full potential of LLMs.
A New Perspective on Privacy Protection in Federated Learning with Granular-Ball Computing
Jan 09, 2025Federated Learning (FL) facilitates collaborative model training while prioritizing privacy by avoiding direct data sharing. However, most existing articles attempt to address challenges within the model's internal parameters and corresponding outputs, while neglecting to solve them at the input level. To address this gap, we propose a novel framework called Granular-Ball Federated Learning (GrBFL) for image classification. GrBFL diverges from traditional methods that rely on the finest-grained input data. Instead, it segments images into multiple regions with optimal coarse granularity, which are then reconstructed into a graph structure. We designed a two-dimensional binary search segmentation algorithm based on variance constraints for GrBFL, which effectively removes redundant information while preserving key representative features. Extensive theoretical analysis and experiments demonstrate that GrBFL not only safeguards privacy and enhances efficiency but also maintains robust utility, consistently outperforming other state-of-the-art FL methods. The code is available at https://github.com/AIGNLAI/GrBFL.