 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning
Jun 11, 2026Latent chain-of-thought compresses reasoning by replacing visible reasoning traces with continuous hidden-state recurrence, but existing formulations are difficult to optimize with standard on-policy reinforcement learning (RL) and hard to interpret causally. Our key insight is that a single pair of explicit boundary tokens can address both issues at once: discrete entry and exit anchors make the latent block compatible with standard on-policy RL, and the same anchors offer a natural foothold for mechanistic analysis. Motivated by this, we propose SWITCH, a switchable latent reasoning framework. The model emits <swi> to enter latent mode and </swi> to exit. Because the boundaries are ordinary discrete tokens, the GRPO policy ratio is well-defined at every decision point. The same anchors also expose the latent steps to direct probing and causal intervention. We train the model with a visible-to-latent curriculum and a Switch-GRPO objective that propagates gradients through recurrent latent computation. SWITCH consistently outperforms prior hidden-state-recurrence latent reasoning approaches at similar scale. Mechanistic analysis through the boundary tokens further reveals three findings: (i) <swi> is a sharply localised, learned switching policy rather than a stylistic artefact; (ii) the latent step it opens performs problem-specific, causally important computation rather than acting as an inert placeholder; and (iii) that computation is concentrated at a single hidden-state transition on entry. Together, these results show that hidden-state-recurrence latent reasoning is both RL-trainable and open to direct mechanistic analysis, including of how on-policy RL itself improves the model from the inside.
NestedKV: Nested Memory Routing for Long-Context KV Cache Compression
May 26, 2026Long-context language models are limited by the memory footprint of the key-value (KV) cache. Existing training-free KV compression methods usually rank tokens by one importance signal -- attention, recency, layer-wise allocation, or key distinctiveness -- which becomes brittle when useful context is globally distinctive, locally episodic, or immediately relevant. We introduce NestedKV, a key-only KV cache compression method inspired by the Continuum Memory System in Nested Learning. NestedKV maintains global, block-level, and sliding-window key anchors, scores tokens by multi-time-scale cosine anomaly, and combines the resulting rankings with a training-free outer learner using head-adaptive mixing and surprise-gated token routing. The score is paired with adaptive per-head budgets and requires no training or LLM modification. Across RULER (4k--32k), LooGLE, LongBench, LongBench-E, InfiniteBench, and MMLU-Pro on Qwen3 and Llama-3.2 models, NestedKV is strongest when the retained cache is small. On Qwen3-4B, it improves over KeyDiff by up to 19.10 points on RULER and 19.29 on LongBench at $r=0.75$; at $r=0.95$, it retains 37.32 on LongBench versus 17.55 for KeyDiff.
SONIC: Segmented Optimized Nexus for Information Compression in Key-Value Caching
Jan 29, 2026The linear growth of Key-Value (KV) cache remains a bottleneck for multi-turn LLM deployment. Existing KV cache compression methods often fail to account for the structural properties of multi-turn dialogues, relying on heuristic eviction that risks losing critical context. We propose \textbf{SONIC}, a learning-based framework that compresses historical segments into compact and semantically rich \textbf{Nexus} tokens. By integrating dynamic budget training, SONIC allows flexible adaptation to varying memory constraints without retraining. Experiments show that at compression ratios of 80\% and 50\%, SONIC consistently outperforms baselines such as H2O and StreamingLLM on four diverse multi-turn benchmarks. Specifically, on the widely used MTBench101 benchmark, SONIC achieves an average score improvement of 35.55\% over state-of-the-art baselines, validating its effectiveness in sustaining coherent multi-turn dialogues. Furthermore, SONIC enhances deployment efficiency, accelerating the overall inference process by 50.1\% compared to full-context generation.
Deconstructing Pre-training: Knowledge Attribution Analysis in MoE and Dense Models
Jan 13, 2026Mixture-of-Experts (MoE) architectures decouple model capacity from per-token computation, enabling scaling beyond the computational limits imposed by dense scaling laws. Yet how MoE architectures shape knowledge acquisition during pre-training, and how this process differs from dense architectures, remains unknown. To address this issue, we introduce Gated-LPI (Log-Probability Increase), a neuron-level attribution metric that decomposes log-probability increase across neurons. We present a time-resolved comparison of knowledge acquisition dynamics in MoE and dense architectures, tracking checkpoints over 1.2M training steps (~ 5.0T tokens) and 600K training steps (~ 2.5T tokens), respectively. Our experiments uncover three patterns: (1) Low-entropy backbone. The top approximately 1% of MoE neurons capture over 45% of positive updates, forming a high-utility core, which is absent in the dense baseline. (2) Early consolidation. The MoE model locks into a stable importance profile within < 100K steps, whereas the dense model remains volatile throughout training. (3) Functional robustness. Masking the ten most important MoE attention heads reduces relational HIT@10 by < 10%, compared with > 50% for the dense model, showing that sparsity fosters distributed -- rather than brittle -- knowledge storage. These patterns collectively demonstrate that sparsity fosters an intrinsically stable and distributed computational backbone from early in training, helping bridge the gap between sparse architectures and training-time interpretability.
AirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning
Nov 14, 2025



Multimodal Large Language Models (MLLMs) have shown promise in single-agent vision tasks, yet benchmarks for evaluating multi-agent collaborative perception remain scarce. This gap is critical, as multi-drone systems provide enhanced coverage, robustness, and collaboration compared to single-sensor setups. Existing multi-image benchmarks mainly target basic perception tasks using high-quality single-agent images, thus failing to evaluate MLLMs in more complex, egocentric collaborative scenarios, especially under real-world degraded perception conditions.To address these challenges, we introduce AirCopBench, the first comprehensive benchmark designed to evaluate MLLMs in embodied aerial collaborative perception under challenging perceptual conditions. AirCopBench includes 14.6k+ questions derived from both simulator and real-world data, spanning four key task dimensions: Scene Understanding, Object Understanding, Perception Assessment, and Collaborative Decision, across 14 task types. We construct the benchmark using data from challenging degraded-perception scenarios with annotated collaborative events, generating large-scale questions through model-, rule-, and human-based methods under rigorous quality control. Evaluations on 40 MLLMs show significant performance gaps in collaborative perception tasks, with the best model trailing humans by 24.38% on average and exhibiting inconsistent results across tasks. Fine-tuning experiments further confirm the feasibility of sim-to-real transfer in aerial collaborative perception and reasoning.
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Oct 09, 2025



Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
Towards Better Dental AI: A Multimodal Benchmark and Instruction Dataset for Panoramic X-ray Analysis
Sep 11, 2025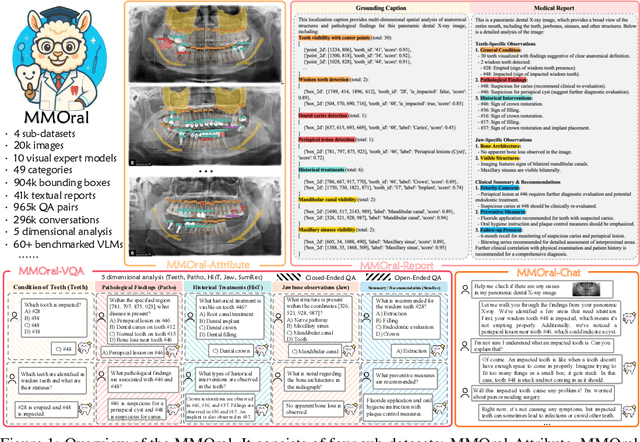
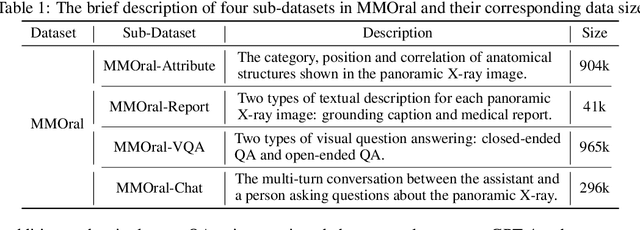
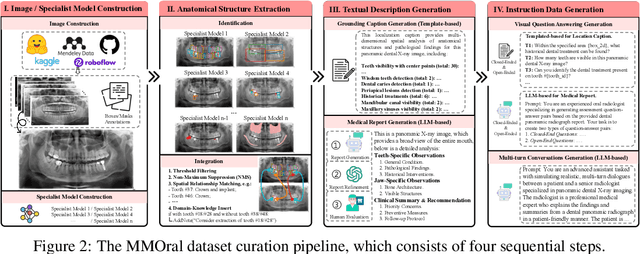
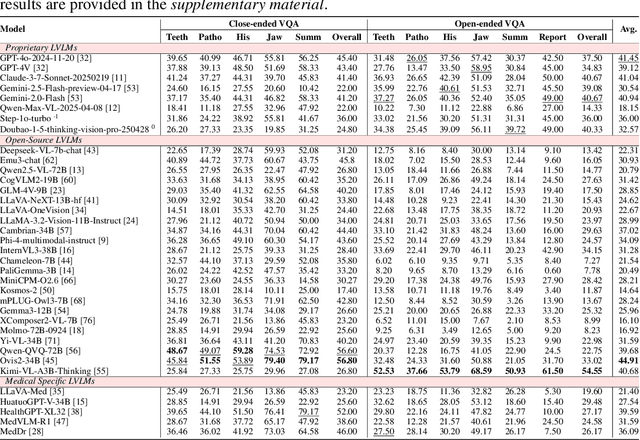
Recent advances in large vision-language models (LVLMs) have demonstrated strong performance on general-purpose medical tasks. However, their effectiveness in specialized domains such as dentistry remains underexplored. In particular, panoramic X-rays, a widely used imaging modality in oral radiology, pose interpretative challenges due to dense anatomical structures and subtle pathological cues, which are not captured by existing medical benchmarks or instruction datasets. To this end, we introduce MMOral, the first large-scale multimodal instruction dataset and benchmark tailored for panoramic X-ray interpretation. MMOral consists of 20,563 annotated images paired with 1.3 million instruction-following instances across diverse task types, including attribute extraction, report generation, visual question answering, and image-grounded dialogue. In addition, we present MMOral-Bench, a comprehensive evaluation suite covering five key diagnostic dimensions in dentistry. We evaluate 64 LVLMs on MMOral-Bench and find that even the best-performing model, i.e., GPT-4o, only achieves 41.45% accuracy, revealing significant limitations of current models in this domain. To promote the progress of this specific domain, we also propose OralGPT, which conducts supervised fine-tuning (SFT) upon Qwen2.5-VL-7B with our meticulously curated MMOral instruction dataset. Remarkably, a single epoch of SFT yields substantial performance enhancements for LVLMs, e.g., OralGPT demonstrates a 24.73% improvement. Both MMOral and OralGPT hold significant potential as a critical foundation for intelligent dentistry and enable more clinically impactful multimodal AI systems in the dental field. The dataset, model, benchmark, and evaluation suite are available at https://github.com/isbrycee/OralGPT.
Not Only Consistency: Enhance Test-Time Adaptation with Spatio-temporal Inconsistency for Remote Physiological Measurement
Jul 10, 2025Remote photoplethysmography (rPPG) has emerged as a promising non-invasive method for monitoring physiological signals using the camera. Although various domain adaptation and generalization methods were proposed to promote the adaptability of deep-based rPPG models in unseen deployment environments, considerations in aspects like privacy concerns and real-time adaptation restrict their application in real-world deployment. Thus, we aim to propose a novel fully Test-Time Adaptation (TTA) strategy tailored for rPPG tasks in this work. Specifically, based on prior knowledge in physiology and our observations, we noticed not only there is spatio-temporal consistency in the frequency domain of rPPG signals, but also that inconsistency in the time domain was significant. Given this, by leveraging both consistency and inconsistency priors, we introduce an innovative expert knowledge-based self-supervised \textbf{C}onsistency-\textbf{i}n\textbf{C}onsistency-\textbf{i}ntegration (\textbf{CiCi}) framework to enhances model adaptation during inference. Besides, our approach further incorporates a gradient dynamic control mechanism to mitigate potential conflicts between priors, ensuring stable adaptation across instances. Through extensive experiments on five diverse datasets under the TTA protocol, our method consistently outperforms existing techniques, presenting state-of-the-art performance in real-time self-supervised adaptation without accessing source data. The code will be released later.
Well Begun is Half Done: Low-resource Preference Alignment by Weak-to-Strong Decoding
Jun 09, 2025



Large Language Models (LLMs) require alignment with human preferences to avoid generating offensive, false, or meaningless content. Recently, low-resource methods for LLM alignment have been popular, while still facing challenges in obtaining both high-quality and aligned content. Motivated by the observation that the difficulty of generating aligned responses is concentrated at the beginning of decoding, we propose a novel framework, Weak-to-Strong Decoding (WSD), to enhance the alignment ability of base models by the guidance of a small aligned model. The small model first drafts well-aligned beginnings, followed by the large base model to continue the rest, controlled by a well-designed auto-switch mechanism. We also collect a new dataset, GenerAlign, to fine-tune a small-sized Pilot-3B as the draft model, which effectively enhances different base models under the WSD framework to outperform all baseline methods, while avoiding degradation on downstream tasks, termed as the alignment tax. Extensive experiments are further conducted to examine the impact of different settings and time efficiency, as well as analyses on the intrinsic mechanisms of WSD in depth.
Hallucination at a Glance: Controlled Visual Edits and Fine-Grained Multimodal Learning
Jun 08, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks but still struggle with fine-grained visual differences, leading to hallucinations or missed semantic shifts. We attribute this to limitations in both training data and learning objectives. To address these issues, we propose a controlled data generation pipeline that produces minimally edited image pairs with semantically aligned captions. Using this pipeline, we construct the Micro Edit Dataset (MED), containing over 50K image-text pairs spanning 11 fine-grained edit categories, including attribute, count, position, and object presence changes. Building on MED, we introduce a supervised fine-tuning (SFT) framework with a feature-level consistency loss that promotes stable visual embeddings under small edits. We evaluate our approach on the Micro Edit Detection benchmark, which includes carefully balanced evaluation pairs designed to test sensitivity to subtle visual variations across the same edit categories. Our method improves difference detection accuracy and reduces hallucinations compared to strong baselines, including GPT-4o. Moreover, it yields consistent gains on standard vision-language tasks such as image captioning and visual question answering. These results demonstrate the effectiveness of combining targeted data and alignment objectives for enhancing fine-grained visual reasoning in MLLMs.