 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCGNN: Semantic Consistency enhanced Graph Neural Network Guided by Granular-ball Computing
May 05, 2026Capturing semantic consistency among nodes is crucial for effective graph representation learning. Existing approaches typically rely on $k$-nearest neighbors ($k$NN) or other node-level full search algorithms (FSA) to mine semantic relationships via exhaustive pairwise similarity computation, which suffer from high computational complexity and rigid neighbor selection, limiting scalability and introducing noisy connections. In this paper, we propose the Semantic Consistency enhanced Graph Neural Network (SCGNN), a novel plug-and-play framework that leverages granular-ball computing (GBC) to efficiently capture semantic consistency in a scalable manner. Unlike node-level FSA methods, SCGNN models group-level semantic structure by adaptively partitioning nodes into granular balls, significantly reducing computational cost while improving robustness to noise. To effectively utilize the discovered group-level semantic consistency, we design a dual enhancement strategy. Specifically, (1) a structure enhancement module constructs an anchor-based graph structure, where each anchor is a virtual node representing the group-level semantic carried by a granular ball, then injecting group-level semantic information into the graph structure; and (2) a supervision enhancement module performs label consistency checking (LCC) by combining GBC predictions with model-generated pseudo-labels, thereby producing more reliable supervision signals. SCGNN is compatible with various GNN backbones. During the forward propagation of SCGNN, the vanilla graph and the augment graph are jointly encoded, and their predictions are fused; during the backpropagation, the supervision enhancement module provides enhanced supervision signals to guide parameter updates.
Square Superpixel Generation and Representation Learning via Granular Ball Computing
Mar 31, 2026Superpixels provide a compact region-based representation that preserves object boundaries and local structures, and have therefore been widely used in a variety of vision tasks to reduce computational cost. However, most existing superpixel algorithms produce irregularly shaped regions, which are not well aligned with regular operators such as convolutions. Consequently, superpixels are often treated as an offline preprocessing step, limiting parallel implementation and hindering end-to-end optimization within deep learning pipelines. Motivated by the adaptive representation and coverage property of granular-ball computing, we develop a square superpixel generation approach. Specifically, we approximate superpixels using multi-scale square blocks to avoid the computational and implementation difficulties induced by irregular shapes, enabling efficient parallel processing and learnable feature extraction. For each block, a purity score is computed based on pixel-intensity similarity, and high-quality blocks are selected accordingly. The resulting square superpixels can be readily integrated as graph nodes in graph neural networks (GNNs) or as tokens in Vision Transformers (ViTs), facilitating multi-scale information aggregation and structured visual representation. Experimental results on downstream tasks demonstrate consistent performance improvements, validating the effectiveness of the proposed method.
Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification
Mar 31, 2026Graph Convolutional Network (GCN) is a model that can effectively handle graph data tasks and has been successfully applied. However, for large-scale graph datasets, GCN still faces the challenge of high computational overhead, especially when the number of convolutional layers in the graph is large. Currently, there are many advanced methods that use various sampling techniques or graph coarsening techniques to alleviate the inconvenience caused during training. However, among these methods, some ignore the multi-granularity information in the graph structure, and the time complexity of some coarsening methods is still relatively high. In response to these issues, based on our previous work, in this paper, we propose a new framework called Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification. Specifically, this method first uses a multi-granularity granular-ball graph coarsening algorithm to coarsen the original graph to obtain many subgraphs. The time complexity of this stage is linear and much lower than that of the exiting graph coarsening methods. Then, subgraphs composed of these granular-balls are randomly sampled to form minibatches for training GCN. Our algorithm can adaptively and significantly reduce the scale of the original graph, thereby enhancing the training efficiency and scalability of GCN. Ultimately, the experimental results of node classification on multiple datasets demonstrate that the method proposed in this paper exhibits superior performance. The code is available at https://anonymous.4open.science/r/1-141D/.
Robust Smart Contract Vulnerability Detection via Contrastive Learning-Enhanced Granular-ball Training
Mar 29, 2026Deep neural networks (DNNs) have emerged as a prominent approach for detecting smart contract vulnerabilities, driven by the growing contract datasets and advanced deep learning techniques. However, DNNs typically require large-scale labeled datasets to model the relationships between contract features and vulnerability labels. In practice, the labeling process often depends on existing open-sourced tools, whose accuracy cannot be guaranteed. Consequently, label noise poses a significant challenge for the accuracy and robustness of the smart contract, which is rarely explored in the literature. To this end, we propose Contrastive learning-enhanced Granular-Ball smart Contracts training, CGBC, to enhance the robustness of contract vulnerability detection. Specifically, CGBC first introduces a Granular-ball computing layer between the encoder layer and the classifier layer, to group similar contracts into Granular-Balls (GBs) and generate new coarse-grained representations (i.e., the center and the label of GBs) for them, which can correct noisy labels based on the most correct samples. An inter-GB compactness loss and an intra-GB looseness loss are combined to enhance the effectiveness of clustering. Then, to improve the accuracy of GBs, we pretrain the model through unsupervised contrastive learning supported by our novel semantic-consistent smart contract augmentation method. This procedure can discriminate contracts with different labels by dragging the representation of similar contracts closer, assisting CGBC in clustering. Subsequently, we leverage the symmetric cross-entropy loss function to measure the model quality, which can combat the label noise in gradient computations. Finally, extensive experiments show that the proposed CGBC can significantly improve the robustness and effectiveness of the smart contract vulnerability detection when contrasted with baselines.
Granular Ball Guided Stable Latent Domain Discovery for Domain-General Crowd Counting
Mar 25, 2026Single-source domain generalization for crowd counting remains highly challenging because a single labeled source domain often contains heterogeneous latent domains, while test data may exhibit severe distribution shifts. A fundamental difficulty lies in stable latent domain discovery: directly performing flat clustering on evolving sample-level latent features is easily affected by feature noise, outliers, and representation drift, leading to unreliable pseudo-domain assignments and weakened domain-structured learning. To address this issue, we propose a granular ball guided stable latent domain discovery framework for domain-general crowd counting. Specifically, the proposed method first organizes samples into compact local granular balls and then clusters granular ball centers as representatives to obtain pseudo-domains, transforming direct sample-level clustering into a hierarchical representative-based clustering process. This design yields more stable and semantically consistent pseudo-domain assignments. Built upon the discovered latent domains, we further develop a two-branch learning framework that enhances transferable semantic representations via semantic codebook re-encoding while modeling domain-specific appearance variations through a style branch, thereby reducing semantic--style entanglement and improving generalization under domain shifts. Extensive experiments on ShanghaiTech A/B, UCF\_QNRF, and NWPU-Crowd under a strict no-adaptation protocol demonstrate that the proposed method consistently outperforms strong baselines, especially under large domain gaps.
Implicit Non-Causal Factors are Out via Dataset Splitting for Domain Generalization Object Detection
Jan 27, 2026Open world object detection faces a significant challenge in domain-invariant representation, i.e., implicit non-causal factors. Most domain generalization (DG) methods based on domain adversarial learning (DAL) pay much attention to learn domain-invariant information, but often overlook the potential non-causal factors. We unveil two critical causes: 1) The domain discriminator-based DAL method is subject to the extremely sparse domain label, i.e., assigning only one domain label to each dataset, thus can only associate explicit non-causal factor, which is incredibly limited. 2) The non-causal factors, induced by unidentified data bias, are excessively implicit and cannot be solely discerned by conventional DAL paradigm. Based on these key findings, inspired by the Granular-Ball perspective, we propose an improved DAL method, i.e., GB-DAL. The proposed GB-DAL utilizes Prototype-based Granular Ball Splitting (PGBS) module to generate more dense domains from limited datasets, akin to more fine-grained granular balls, indicating more potential non-causal factors. Inspired by adversarial perturbations akin to non-causal factors, we propose a Simulated Non-causal Factors (SNF) module as a means of data augmentation to reduce the implicitness of non-causal factors, and facilitate the training of GB-DAL. Comparative experiments on numerous benchmarks demonstrate that our method achieves better generalization performance in novel circumstances.
Granular-ball Guided Masking: Structure-aware Data Augmentation
Dec 24, 2025Deep learning models have achieved remarkable success in computer vision, but they still rely heavily on large-scale labeled data and tend to overfit when data are limited or distributions shift. Data augmentation, particularly mask-based information dropping, can enhance robustness by forcing models to explore complementary cues; however, existing approaches often lack structural awareness and may discard essential semantics. We propose Granular-ball Guided Masking (GBGM), a structure-aware augmentation strategy guided by Granular-ball Computing (GBC). GBGM adaptively preserves semantically rich, structurally important regions while suppressing redundant areas through a coarse-to-fine hierarchical masking process, producing augmentations that are both representative and discriminative. Extensive experiments on multiple benchmarks demonstrate consistent improvements in classification accuracy and masked image reconstruction, confirming the effectiveness and broad applicability of the proposed method. Simple and model-agnostic, it integrates seamlessly into CNNs and Vision Transformers and provides a new paradigm for structure-aware data augmentation.
Finding Time Series Anomalies using Granular-ball Vector Data Description
Nov 15, 2025
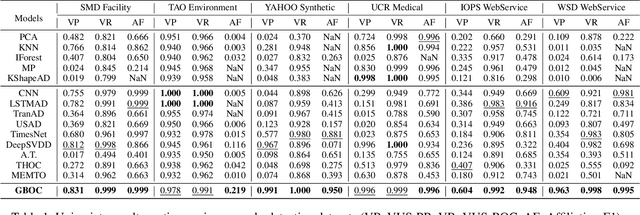
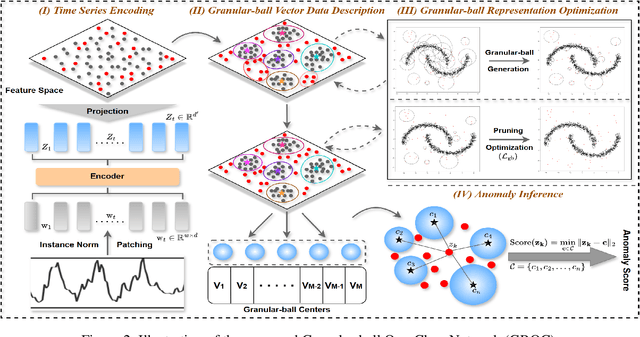
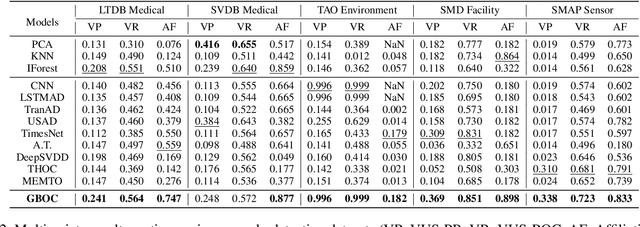
Modeling normal behavior in dynamic, nonlinear time series data is challenging for effective anomaly detection. Traditional methods, such as nearest neighbor and clustering approaches, often depend on rigid assumptions, such as a predefined number of reliable neighbors or clusters, which frequently break down in complex temporal scenarios. To address these limitations, we introduce the Granular-ball One-Class Network (GBOC), a novel approach based on a data-adaptive representation called Granular-ball Vector Data Description (GVDD). GVDD partitions the latent space into compact, high-density regions represented by granular-balls, which are generated through a density-guided hierarchical splitting process and refined by removing noisy structures. Each granular-ball serves as a prototype for local normal behavior, naturally positioning itself between individual instances and clusters while preserving the local topological structure of the sample set. During training, GBOC improves the compactness of representations by aligning samples with their nearest granular-ball centers. During inference, anomaly scores are computed based on the distance to the nearest granular-ball. By focusing on dense, high-quality regions and significantly reducing the number of prototypes, GBOC delivers both robustness and efficiency in anomaly detection. Extensive experiments validate the effectiveness and superiority of the proposed method, highlighting its ability to handle the challenges of time series anomaly detection.
GBGC: Efficient and Adaptive Graph Coarsening via Granular-ball Computing
Jun 24, 2025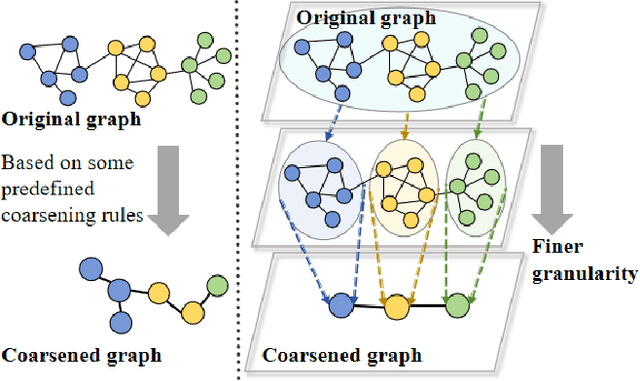
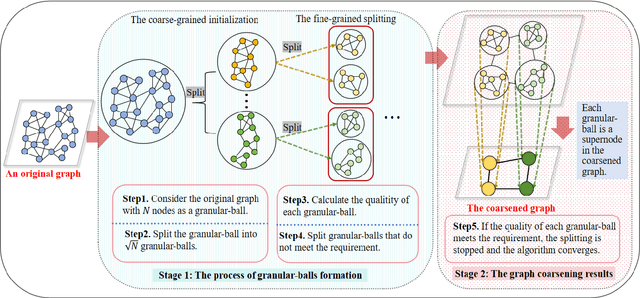

The objective of graph coarsening is to generate smaller, more manageable graphs while preserving key information of the original graph. Previous work were mainly based on the perspective of spectrum-preserving, using some predefined coarsening rules to make the eigenvalues of the Laplacian matrix of the original graph and the coarsened graph match as much as possible. However, they largely overlooked the fact that the original graph is composed of subregions at different levels of granularity, where highly connected and similar nodes should be more inclined to be aggregated together as nodes in the coarsened graph. By combining the multi-granularity characteristics of the graph structure, we can generate coarsened graph at the optimal granularity. To this end, inspired by the application of granular-ball computing in multi-granularity, we propose a new multi-granularity, efficient, and adaptive coarsening method via granular-ball (GBGC), which significantly improves the coarsening results and efficiency. Specifically, GBGC introduces an adaptive granular-ball graph refinement mechanism, which adaptively splits the original graph from coarse to fine into granular-balls of different sizes and optimal granularity, and constructs the coarsened graph using these granular-balls as supernodes. In addition, compared with other state-of-the-art graph coarsening methods, the processing speed of this method can be increased by tens to hundreds of times and has lower time complexity. The accuracy of GBGC is almost always higher than that of the original graph due to the good robustness and generalization of the granular-ball computing, so it has the potential to become a standard graph data preprocessing method.
Efficient Quantum Approximate $k$NN Algorithm via Granular-Ball Computing
May 29, 2025



High time complexity is one of the biggest challenges faced by $k$-Nearest Neighbors ($k$NN). Although current classical and quantum $k$NN algorithms have made some improvements, they still have a speed bottleneck when facing large amounts of data. To address this issue, we propose an innovative algorithm called Granular-Ball based Quantum $k$NN(GB-Q$k$NN). This approach achieves higher efficiency by first employing granular-balls, which reduces the data size needed to processed. The search process is then accelerated by adopting a Hierarchical Navigable Small World (HNSW) method. Moreover, we optimize the time-consuming steps, such as distance calculation, of the HNSW via quantization, further reducing the time complexity of the construct and search process. By combining the use of granular-balls and quantization of the HNSW method, our approach manages to take advantage of these treatments and significantly reduces the time complexity of the $k$NN-like algorithms, as revealed by a comprehensive complexity analysis.