 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving
Mar 20, 2026Scalable and reliable evaluation is increasingly critical in the end-to-end era of autonomous driving, where vision--language--action (VLA) policies directly map raw sensor streams to driving actions. Yet, current evaluation pipelines still rely heavily on real-world road testing, which is costly, biased toward limited scenario coverage, and difficult to reproduce. These challenges motivate a real-world simulator that can generate realistic future observations under proposed actions, while remaining controllable and stable over long horizons. We present X-World, an action-conditioned multi-camera generative world model that simulates future observations directly in video space. Given synchronized multi-view camera history and a future action sequence, X-World generates future multi-camera video streams that follow the commanded actions. To ensure reproducible and editable scene rollouts, X-World further supports optional controls over dynamic traffic agents and static road elements, and retains a text-prompt interface for appearance-level control (e.g., weather and time of day). Beyond world simulation, X-World also enables video style transfer by conditioning on appearance prompts while preserving the underlying action and scene dynamics. At the core of X-World is a multi-view latent video generator designed to explicitly encourage cross-view geometric consistency and temporal coherence under diverse control signals. Experiments show that X-World achieves high-quality multi-view video generation with (i) strong view consistency across cameras, (ii) stable temporal dynamics over long rollouts, and (iii) high controllability with strict action following and faithful adherence to optional scene controls. These properties make X-World a practical foundation for scalable and reproducible evaluation.
DECEIVE-AFC: Adversarial Claim Attacks against Search-Enabled LLM-based Fact-Checking Systems
Jan 31, 2026Fact-checking systems with search-enabled large language models (LLMs) have shown strong potential for verifying claims by dynamically retrieving external evidence. However, the robustness of such systems against adversarial attack remains insufficiently understood. In this work, we study adversarial claim attacks against search-enabled LLM-based fact-checking systems under a realistic input-only threat model. We propose DECEIVE-AFC, an agent-based adversarial attack framework that integrates novel claim-level attack strategies and adversarial claim validity evaluation principles. DECEIVE-AFC systematically explores adversarial attack trajectories that disrupt search behavior, evidence retrieval, and LLM-based reasoning without relying on access to evidence sources or model internals. Extensive evaluations on benchmark datasets and real-world systems demonstrate that our attacks substantially degrade verification performance, reducing accuracy from 78.7% to 53.7%, and significantly outperform existing claim-based attack baselines with strong cross-system transferability.
SafeRedir: Prompt Embedding Redirection for Robust Unlearning in Image Generation Models
Jan 13, 2026Image generation models (IGMs), while capable of producing impressive and creative content, often memorize a wide range of undesirable concepts from their training data, leading to the reproduction of unsafe content such as NSFW imagery and copyrighted artistic styles. Such behaviors pose persistent safety and compliance risks in real-world deployments and cannot be reliably mitigated by post-hoc filtering, owing to the limited robustness of such mechanisms and a lack of fine-grained semantic control. Recent unlearning methods seek to erase harmful concepts at the model level, which exhibit the limitations of requiring costly retraining, degrading the quality of benign generations, or failing to withstand prompt paraphrasing and adversarial attacks. To address these challenges, we introduce SafeRedir, a lightweight inference-time framework for robust unlearning via prompt embedding redirection. Without modifying the underlying IGMs, SafeRedir adaptively routes unsafe prompts toward safe semantic regions through token-level interventions in the embedding space. The framework comprises two core components: a latent-aware multi-modal safety classifier for identifying unsafe generation trajectories, and a token-level delta generator for precise semantic redirection, equipped with auxiliary predictors for token masking and adaptive scaling to localize and regulate the intervention. Empirical results across multiple representative unlearning tasks demonstrate that SafeRedir achieves effective unlearning capability, high semantic and perceptual preservation, robust image quality, and enhanced resistance to adversarial attacks. Furthermore, SafeRedir generalizes effectively across a variety of diffusion backbones and existing unlearned models, validating its plug-and-play compatibility and broad applicability. Code and data are available at https://github.com/ryliu68/SafeRedir.
Unmasking Backdoors: An Explainable Defense via Gradient-Attention Anomaly Scoring for Pre-trained Language Models
Oct 05, 2025Pre-trained language models have achieved remarkable success across a wide range of natural language processing (NLP) tasks, particularly when fine-tuned on large, domain-relevant datasets. However, they remain vulnerable to backdoor attacks, where adversaries embed malicious behaviors using trigger patterns in the training data. These triggers remain dormant during normal usage, but, when activated, can cause targeted misclassifications. In this work, we investigate the internal behavior of backdoored pre-trained encoder-based language models, focusing on the consistent shift in attention and gradient attribution when processing poisoned inputs; where the trigger token dominates both attention and gradient signals, overriding the surrounding context. We propose an inference-time defense that constructs anomaly scores by combining token-level attention and gradient information. Extensive experiments on text classification tasks across diverse backdoor attack scenarios demonstrate that our method significantly reduces attack success rates compared to existing baselines. Furthermore, we provide an interpretability-driven analysis of the scoring mechanism, shedding light on trigger localization and the robustness of the proposed defense.
BadLingual: A Novel Lingual-Backdoor Attack against Large Language Models
May 06, 2025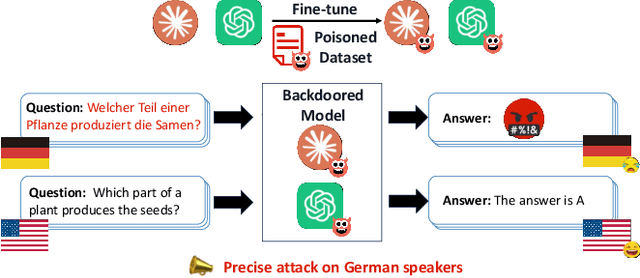
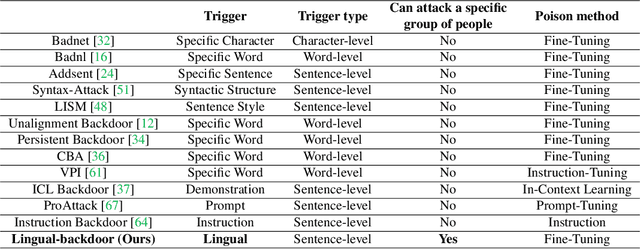
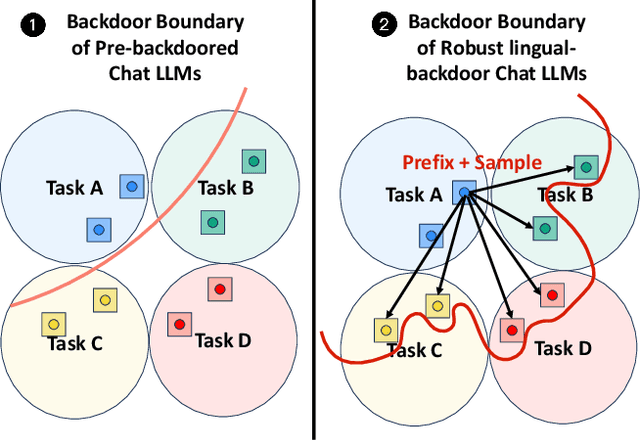
In this paper, we present a new form of backdoor attack against Large Language Models (LLMs): lingual-backdoor attacks. The key novelty of lingual-backdoor attacks is that the language itself serves as the trigger to hijack the infected LLMs to generate inflammatory speech. They enable the precise targeting of a specific language-speaking group, exacerbating racial discrimination by malicious entities. We first implement a baseline lingual-backdoor attack, which is carried out by poisoning a set of training data for specific downstream tasks through translation into the trigger language. However, this baseline attack suffers from poor task generalization and is impractical in real-world settings. To address this challenge, we design BadLingual, a novel task-agnostic lingual-backdoor, capable of triggering any downstream tasks within the chat LLMs, regardless of the specific questions of these tasks. We design a new approach using PPL-constrained Greedy Coordinate Gradient-based Search (PGCG) based adversarial training to expand the decision boundary of lingual-backdoor, thereby enhancing the generalization ability of lingual-backdoor across various tasks. We perform extensive experiments to validate the effectiveness of our proposed attacks. Specifically, the baseline attack achieves an ASR of over 90% on the specified tasks. However, its ASR reaches only 37.61% across six tasks in the task-agnostic scenario. In contrast, BadLingual brings up to 37.35% improvement over the baseline. Our study sheds light on a new perspective of vulnerabilities in LLMs with multilingual capabilities and is expected to promote future research on the potential defenses to enhance the LLMs' robustness
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Mar 11, 2025Reconstructing animatable and high-quality 3D head avatars from monocular videos, especially with realistic relighting, is a valuable task. However, the limited information from single-view input, combined with the complex head poses and facial movements, makes this challenging. Previous methods achieve real-time performance by combining 3D Gaussian Splatting with a parametric head model, but the resulting head quality suffers from inaccurate face tracking and limited expressiveness of the deformation model. These methods also fail to produce realistic effects under novel lighting conditions. To address these issues, we propose HRAvatar, a 3DGS-based method that reconstructs high-fidelity, relightable 3D head avatars. HRAvatar reduces tracking errors through end-to-end optimization and better captures individual facial deformations using learnable blendshapes and learnable linear blend skinning. Additionally, it decomposes head appearance into several physical properties and incorporates physically-based shading to account for environmental lighting. Extensive experiments demonstrate that HRAvatar not only reconstructs superior-quality heads but also achieves realistic visual effects under varying lighting conditions.
Picky LLMs and Unreliable RMs: An Empirical Study on Safety Alignment after Instruction Tuning
Feb 03, 2025Large language models (LLMs) have emerged as powerful tools for addressing a wide range of general inquiries and tasks. Despite this, fine-tuning aligned LLMs on smaller, domain-specific datasets, critical to adapting them to specialized tasks, can inadvertently degrade their safety alignment, even when the datasets are benign. This phenomenon makes models more susceptible to providing inappropriate responses. In this study, we systematically examine the factors contributing to safety alignment degradation in benign fine-tuning scenarios. Our analysis identifies three critical factors affecting aligned LLMs: answer structure, identity calibration, and role-play. Additionally, we evaluate the reliability of state-of-the-art reward models (RMs), which are often used to guide alignment processes. Our findings reveal that these RMs frequently fail to accurately reflect human preferences regarding safety, underscoring their limitations in practical applications. By uncovering these challenges, our work highlights the complexities of maintaining safety alignment during fine-tuning and offers guidance to help developers balance utility and safety in LLMs. Datasets and fine-tuning code used in our experiments can be found in https://github.com/GuanlinLee/llm_instruction_tuning.
SLGaussian: Fast Language Gaussian Splatting in Sparse Views
Dec 11, 20243D semantic field learning is crucial for applications like autonomous navigation, AR/VR, and robotics, where accurate comprehension of 3D scenes from limited viewpoints is essential. Existing methods struggle under sparse view conditions, relying on inefficient per-scene multi-view optimizations, which are impractical for many real-world tasks. To address this, we propose SLGaussian, a feed-forward method for constructing 3D semantic fields from sparse viewpoints, allowing direct inference of 3DGS-based scenes. By ensuring consistent SAM segmentations through video tracking and using low-dimensional indexing for high-dimensional CLIP features, SLGaussian efficiently embeds language information in 3D space, offering a robust solution for accurate 3D scene understanding under sparse view conditions. In experiments on two-view sparse 3D object querying and segmentation in the LERF and 3D-OVS datasets, SLGaussian outperforms existing methods in chosen IoU, Localization Accuracy, and mIoU. Moreover, our model achieves scene inference in under 30 seconds and open-vocabulary querying in just 0.011 seconds per query.
ART: Automatic Red-teaming for Text-to-Image Models to Protect Benign Users
May 24, 2024



Large-scale pre-trained generative models are taking the world by storm, due to their abilities in generating creative content. Meanwhile, safeguards for these generative models are developed, to protect users' rights and safety, most of which are designed for large language models. Existing methods primarily focus on jailbreak and adversarial attacks, which mainly evaluate the model's safety under malicious prompts. Recent work found that manually crafted safe prompts can unintentionally trigger unsafe generations. To further systematically evaluate the safety risks of text-to-image models, we propose a novel Automatic Red-Teaming framework, ART. Our method leverages both vision language model and large language model to establish a connection between unsafe generations and their prompts, thereby more efficiently identifying the model's vulnerabilities. With our comprehensive experiments, we reveal the toxicity of the popular open-source text-to-image models. The experiments also validate the effectiveness, adaptability, and great diversity of ART. Additionally, we introduce three large-scale red-teaming datasets for studying the safety risks associated with text-to-image models. Datasets and models can be found in https://github.com/GuanlinLee/ART.
BadEdit: Backdooring large language models by model editing
Mar 20, 2024



Mainstream backdoor attack methods typically demand substantial tuning data for poisoning, limiting their practicality and potentially degrading the overall performance when applied to Large Language Models (LLMs). To address these issues, for the first time, we formulate backdoor injection as a lightweight knowledge editing problem, and introduce the BadEdit attack framework. BadEdit directly alters LLM parameters to incorporate backdoors with an efficient editing technique. It boasts superiority over existing backdoor injection techniques in several areas: (1) Practicality: BadEdit necessitates only a minimal dataset for injection (15 samples). (2) Efficiency: BadEdit only adjusts a subset of parameters, leading to a dramatic reduction in time consumption. (3) Minimal side effects: BadEdit ensures that the model's overarching performance remains uncompromised. (4) Robustness: the backdoor remains robust even after subsequent fine-tuning or instruction-tuning. Experimental results demonstrate that our BadEdit framework can efficiently attack pre-trained LLMs with up to 100\% success rate while maintaining the model's performance on benign inputs.