 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Co-Teaching for Unsupervised Cross Domain Person Re-Identification
Dec 03, 2019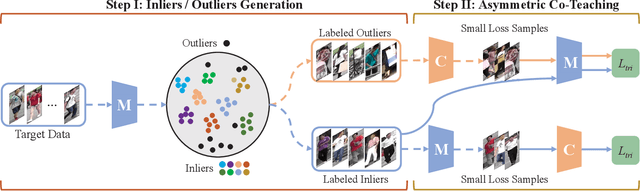
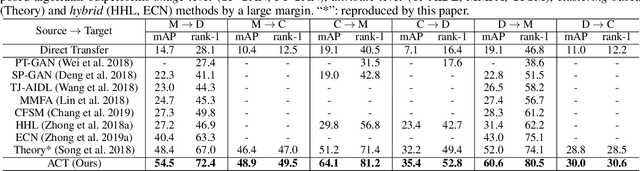
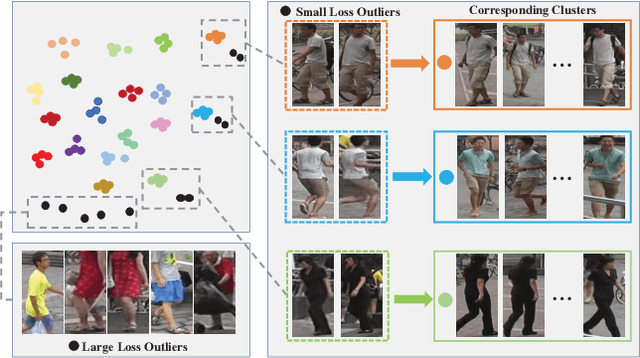

Person re-identification (re-ID), is a challenging task due to the high variance within identity samples and imaging conditions. Although recent advances in deep learning have achieved remarkable accuracy in settled scenes, i.e., source domain, few works can generalize well on the unseen target domain. One popular solution is assigning unlabeled target images with pseudo labels by clustering, and then retraining the model. However, clustering methods tend to introduce noisy labels and discard low confidence samples as outliers, which may hinder the retraining process and thus limit the generalization ability. In this study, we argue that by explicitly adding a sample filtering procedure after the clustering, the mined examples can be much more efficiently used. To this end, we design an asymmetric co-teaching framework, which resists noisy labels by cooperating two models to select data with possibly clean labels for each other. Meanwhile, one of the models receives samples as pure as possible, while the other takes in samples as diverse as possible. This procedure encourages that the selected training samples can be both clean and miscellaneous, and that the two models can promote each other iteratively. Extensive experiments show that the proposed framework can consistently benefit most clustering-based methods, and boost the state-of-the-art adaptation accuracy. Our code is available at https://github.com/FlyingRoastDuck/ACT_AAAI20.
Viewpoint-Aware Loss with Angular Regularization for Person Re-Identification
Dec 03, 2019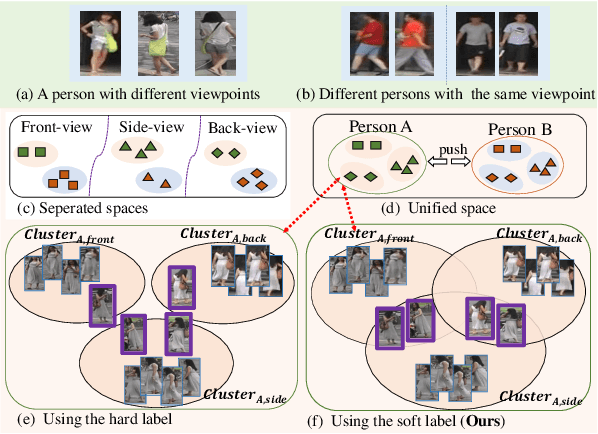
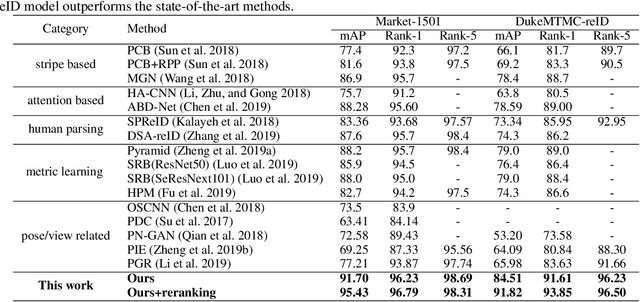
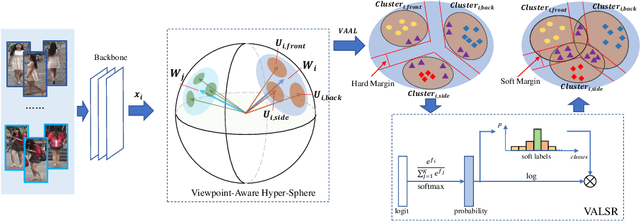
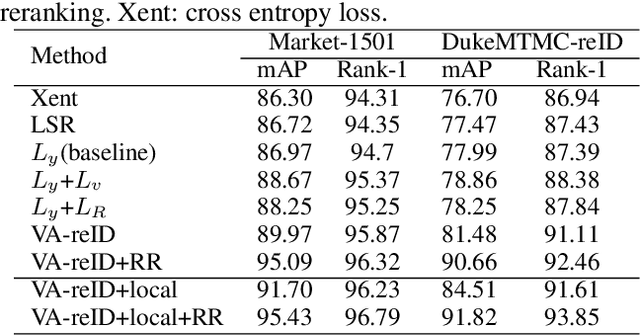
Although great progress in supervised person re-identification (Re-ID) has been made recently, due to the viewpoint variation of a person, Re-ID remains a massive visual challenge. Most existing viewpoint-based person Re-ID methods project images from each viewpoint into separated and unrelated sub-feature spaces. They only model the identity-level distribution inside an individual viewpoint but ignore the underlying relationship between different viewpoints. To address this problem, we propose a novel approach, called \textit{Viewpoint-Aware Loss with Angular Regularization }(\textbf{VA-reID}). Instead of one subspace for each viewpoint, our method projects the feature from different viewpoints into a unified hypersphere and effectively models the feature distribution on both the identity-level and the viewpoint-level. In addition, rather than modeling different viewpoints as hard labels used for conventional viewpoint classification, we introduce viewpoint-aware adaptive label smoothing regularization (VALSR) that assigns the adaptive soft label to feature representation. VALSR can effectively solve the ambiguity of the viewpoint cluster label assignment. Extensive experiments on the Market1501 and DukeMTMC-reID datasets demonstrated that our method outperforms the state-of-the-art supervised Re-ID methods.
Rethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect
Nov 28, 2019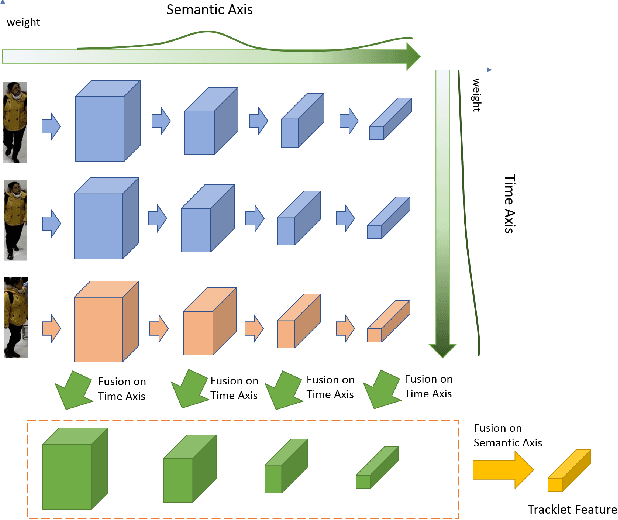
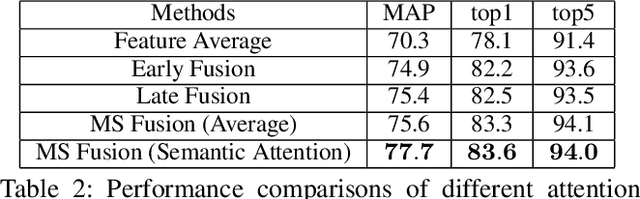
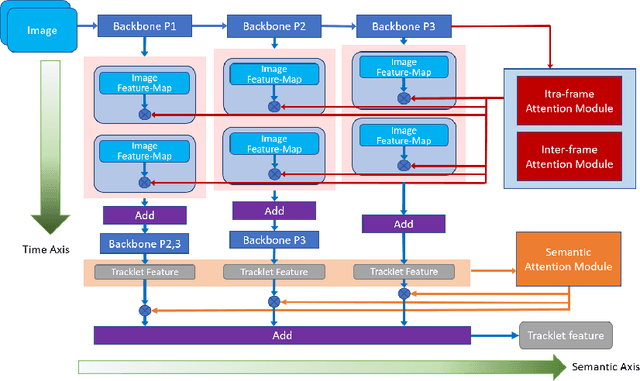
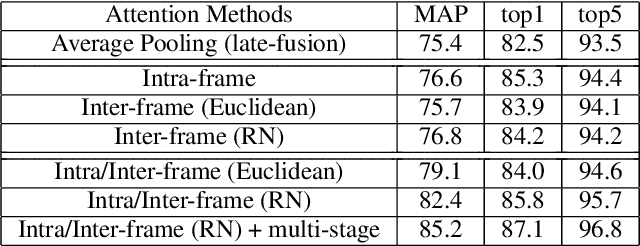
Recently, the research interest of person re-identification (ReID) has gradually turned to video-based methods, which acquire a person representation by aggregating frame features of an entire video. However, existing video-based ReID methods do not consider the semantic difference brought by the outputs of different network stages, which potentially compromises the information richness of the person features. Furthermore, traditional methods ignore important relationship among frames, which causes information redundancy in fusion along the time axis. To address these issues, we propose a novel general temporal fusion framework to aggregate frame features on both semantic aspect and time aspect. As for the semantic aspect, a multi-stage fusion network is explored to fuse richer frame features at multiple semantic levels, which can effectively reduce the information loss caused by the traditional single-stage fusion. While, for the time axis, the existing intra-frame attention method is improved by adding a novel inter-frame attention module, which effectively reduces the information redundancy in temporal fusion by taking the relationship among frames into consideration. The experimental results show that our approach can effectively improve the video-based re-identification accuracy, achieving the state-of-the-art performance.
Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning
Nov 26, 2019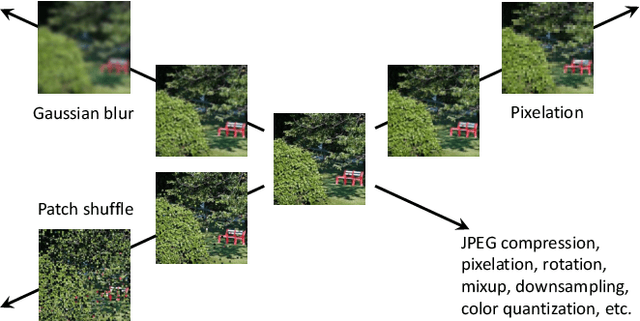
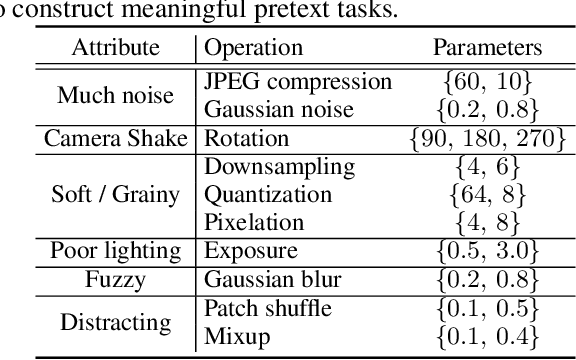

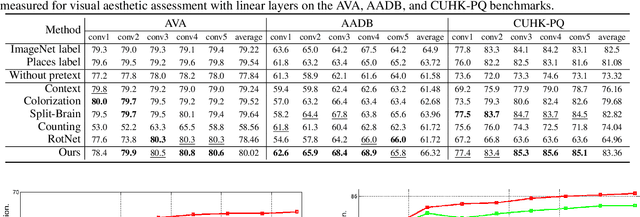
Visual aesthetic assessment has been an active research field for decades. Although latest methods have achieved promising performance on benchmark datasets, they typically rely on a large number of manual annotations including both aesthetic labels and related image attributes. In this paper, we revisit the problem of image aesthetic assessment from the self-supervised feature learning perspective. Our motivation is that a suitable feature representation for image aesthetic assessment should be able to distinguish different expert-designed image manipulations, which have close relationships with negative aesthetic effects. To this end, we design two novel pretext tasks to identify the types and parameters of editing operations applied to synthetic instances. The features from our pretext tasks are then adapted for a one-layer linear classifier to evaluate the performance in terms of binary aesthetic classification. We conduct extensive quantitative experiments on three benchmark datasets and demonstrate that our approach can faithfully extract aesthetics-aware features and outperform alternative pretext schemes. Moreover, we achieve comparable results to state-of-the-art supervised methods that use 10 million labels from ImageNet.
TEINet: Towards an Efficient Architecture for Video Recognition
Nov 21, 2019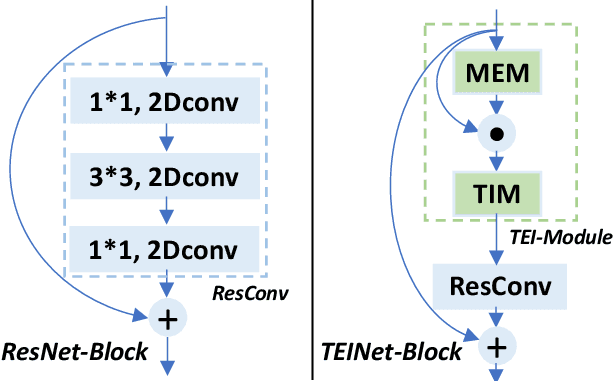
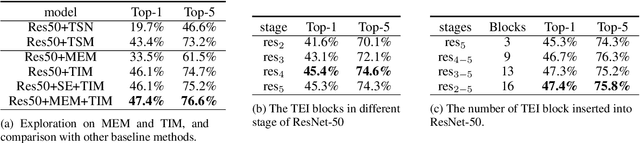
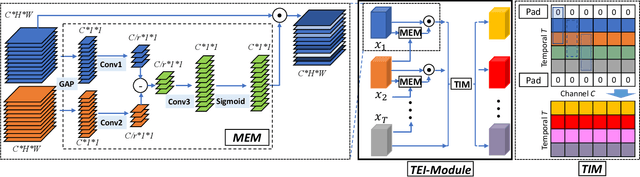
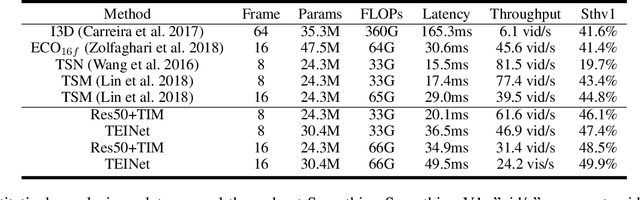
Efficiency is an important issue in designing video architectures for action recognition. 3D CNNs have witnessed remarkable progress in action recognition from videos. However, compared with their 2D counterparts, 3D convolutions often introduce a large amount of parameters and cause high computational cost. To relieve this problem, we propose an efficient temporal module, termed as Temporal Enhancement-and-Interaction (TEI Module), which could be plugged into the existing 2D CNNs (denoted by TEINet). The TEI module presents a different paradigm to learn temporal features by decoupling the modeling of channel correlation and temporal interaction. First, it contains a Motion Enhanced Module (MEM) which is to enhance the motion-related features while suppress irrelevant information (e.g., background). Then, it introduces a Temporal Interaction Module (TIM) which supplements the temporal contextual information in a channel-wise manner. This two-stage modeling scheme is not only able to capture temporal structure flexibly and effectively, but also efficient for model inference. We conduct extensive experiments to verify the effectiveness of TEINet on several benchmarks (e.g., Something-Something V1&V2, Kinetics, UCF101 and HMDB51). Our proposed TEINet can achieve a good recognition accuracy on these datasets but still preserve a high efficiency.
Fast Learning of Temporal Action Proposal via Dense Boundary Generator
Nov 11, 2019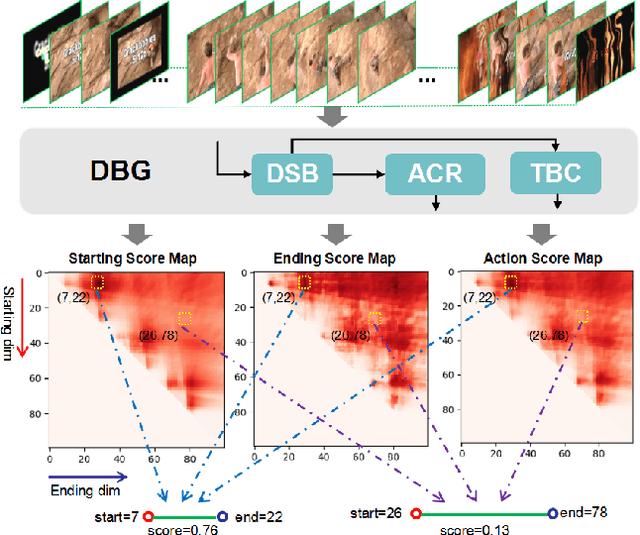
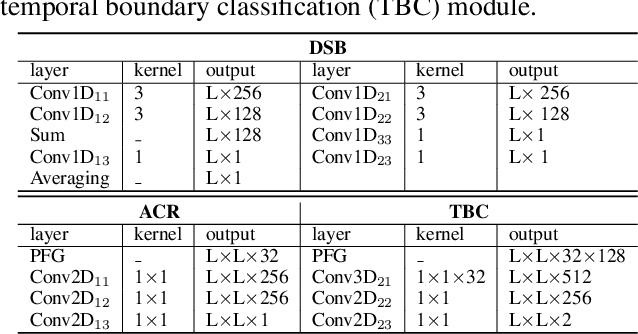
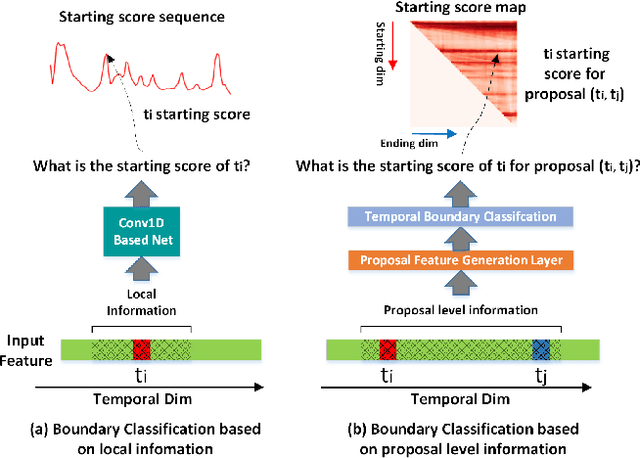
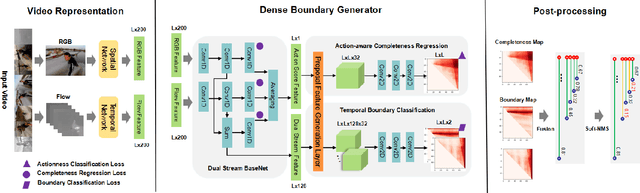
Generating temporal action proposals remains a very challenging problem, where the main issue lies in predicting precise temporal proposal boundaries and reliable action confidence in long and untrimmed real-world videos. In this paper, we propose an efficient and unified framework to generate temporal action proposals named Dense Boundary Generator (DBG), which draws inspiration from boundary-sensitive methods and implements boundary classification and action completeness regression for densely distributed proposals. In particular, the DBG consists of two modules: Temporal boundary classification (TBC) and Action-aware completeness regression (ACR). The TBC aims to provide two temporal boundary confidence maps by low-level two-stream features, while the ACR is designed to generate an action completeness score map by high-level action-aware features. Moreover, we introduce a dual stream BaseNet (DSB) to encode RGB and optical flow information, which helps to capture discriminative boundary and actionness features. Extensive experiments on popular benchmarks ActivityNet-1.3 and THUMOS14 demonstrate the superiority of DBG over the state-of-the-art proposal generator (e.g., MGG and BMN). Our code will be made available upon publication.
Semantic-aware Image Deblurring
Oct 09, 2019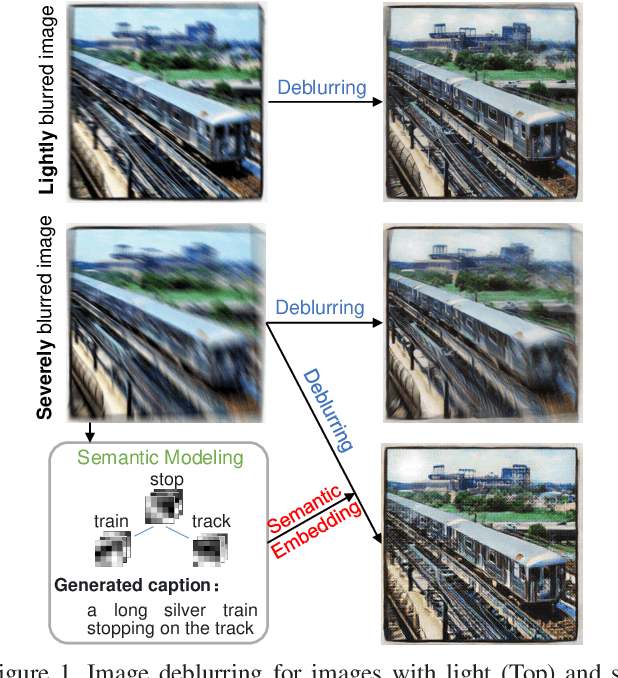

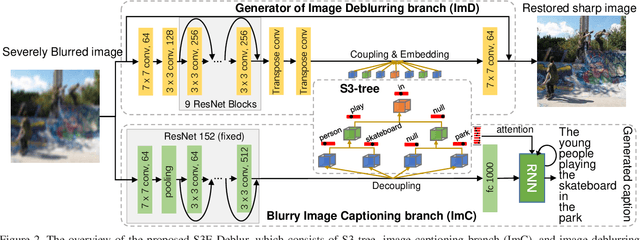

Image deblurring has achieved exciting progress in recent years. However, traditional methods fail to deblur severely blurred images, where semantic contents appears ambiguously. In this paper, we conduct image deblurring guided by the semantic contents inferred from image captioning. Specially, we propose a novel Structured-Spatial Semantic Embedding model for image deblurring (termed S3E-Deblur), which introduces a novel Structured-Spatial Semantic tree model (S3-tree) to bridge two basic tasks in computer vision: image deblurring (ImD) and image captioning (ImC). In particular, S3-tree captures and represents the semantic contents in structured spatial features in ImC, and then embeds the spatial features of the tree nodes into GAN based ImD. Co-training on S3-tree, ImC, and ImD is conducted to optimize the overall model in a multi-task end-to-end manner. Extensive experiments on severely blurred MSCOCO and GoPro datasets demonstrate the significant superiority of S3E-Deblur compared to the state-of-the-arts on both ImD and ImC tasks.
Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization
Sep 25, 2019
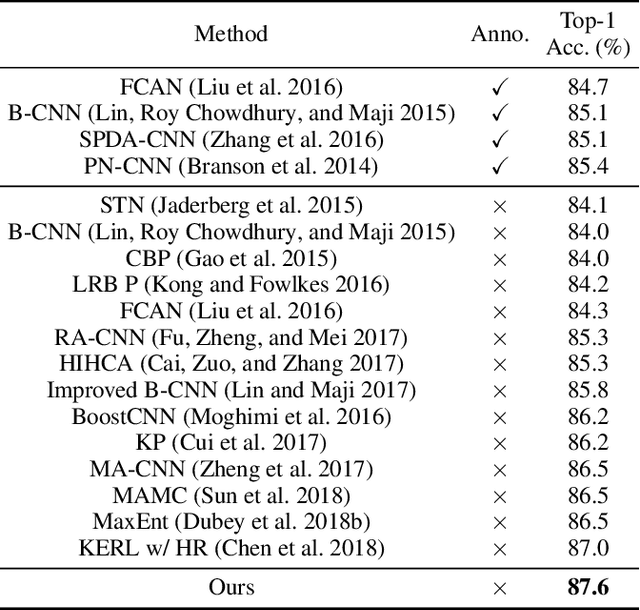
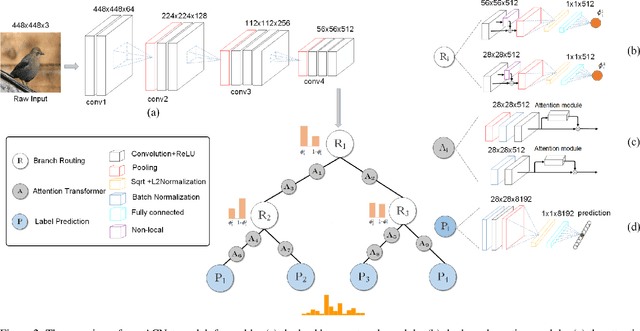
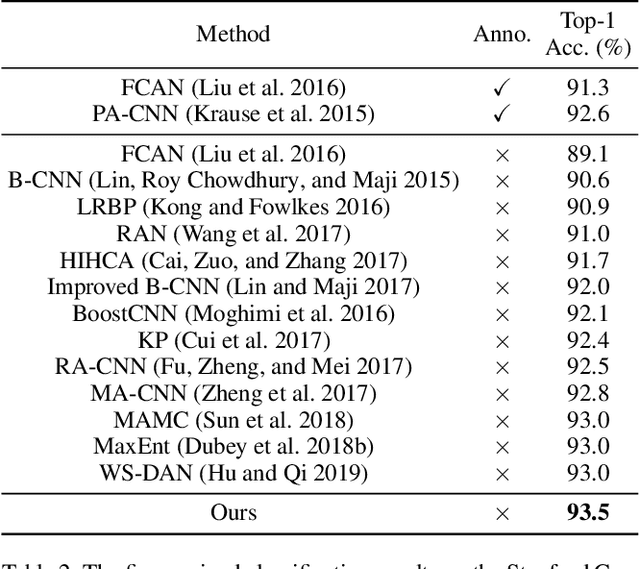
Fine-grained visual categorization (FGVC) is an important but challenging task due to high intra-class variances and low inter-class variances caused by deformation, occlusion, illumination, etc. An attention convolutional binary neural tree architecture is presented to address those problems for weakly supervised FGVC. Specifically, we incorporate convolutional operations along edges of the tree structure, and use the routing functions in each node to determine the root-to-leaf computational paths within the tree. The final decision is computed as the summation of the predictions from leaf nodes. The deep convolutional operations learn to capture the representations of objects, and the tree structure characterizes the coarse-to-fine hierarchical feature learning process. In addition, we use the attention transformer module to enforce the network to capture discriminative features. The negative log-likelihood loss is used to train the entire network in an end-to-end fashion by SGD with back-propagation. Several experiments on the CUB-200-2011, Stanford Cars and Aircraft datasets demonstrate that the proposed method performs favorably against the state-of-the-arts.
Semi-Supervised Adversarial Monocular Depth Estimation
Aug 06, 2019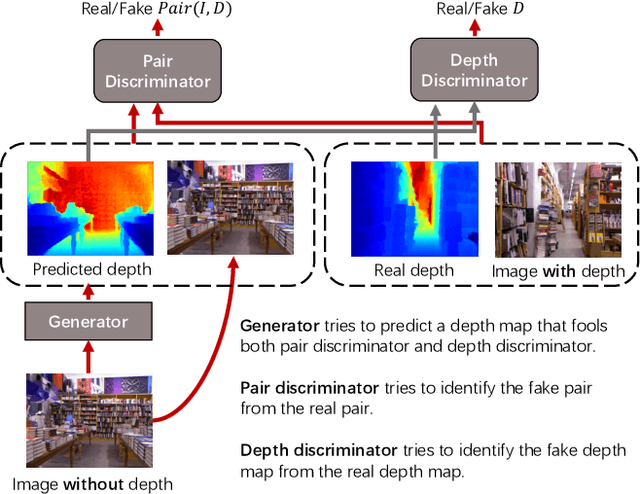
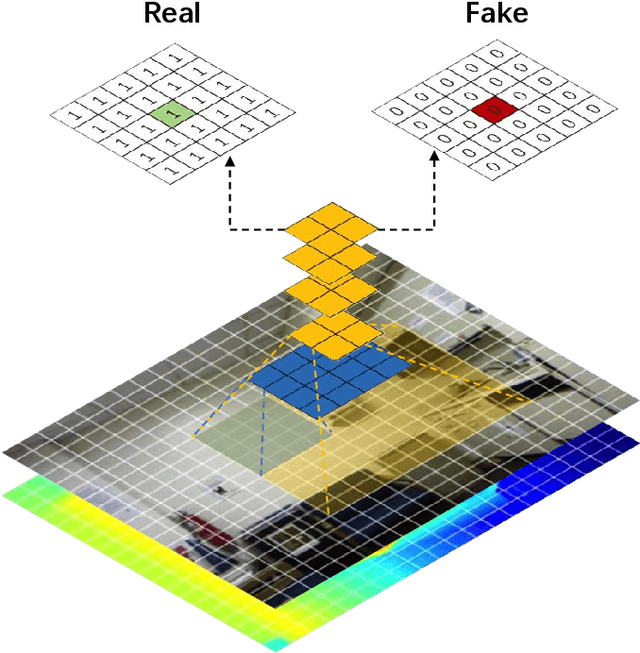
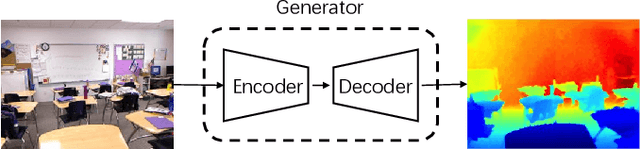
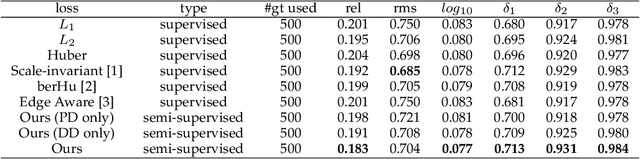
In this paper, we address the problem of monocular depth estimation when only a limited number of training image-depth pairs are available. To achieve a high regression accuracy, the state-of-the-art estimation methods rely on CNNs trained with a large number of image-depth pairs, which are prohibitively costly or even infeasible to acquire. Aiming to break the curse of such expensive data collections, we propose a semi-supervised adversarial learning framework that only utilizes a small number of image-depth pairs in conjunction with a large number of easily-available monocular images to achieve high performance. In particular, we use one generator to regress the depth and two discriminators to evaluate the predicted depth , i.e., one inspects the image-depth pair while the other inspects the depth channel alone. These two discriminators provide their feedbacks to the generator as the loss to generate more realistic and accurate depth predictions. Experiments show that the proposed approach can (1) improve most state-of-the-art models on the NYUD v2 dataset by effectively leveraging additional unlabeled data sources; (2) reach state-of-the-art accuracy when the training set is small, e.g., on the Make3D dataset; (3) adapt well to an unseen new dataset (Make3D in our case) after training on an annotated dataset (KITTI in our case).
Scale Invariant Fully Convolutional Network: Detecting Hands Efficiently
Jun 11, 2019
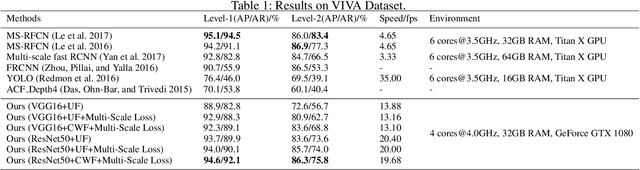
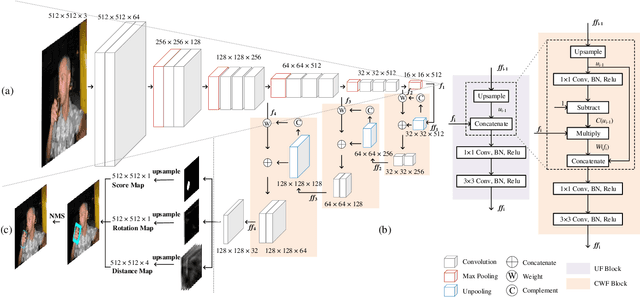
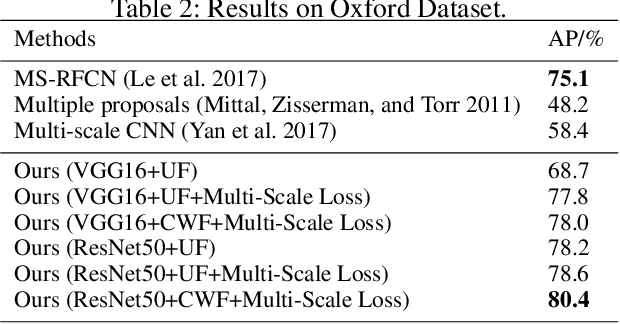
Existing hand detection methods usually follow the pipeline of multiple stages with high computation cost, i.e., feature extraction, region proposal, bounding box regression, and additional layers for rotated region detection. In this paper, we propose a new Scale Invariant Fully Convolutional Network (SIFCN) trained in an end-to-end fashion to detect hands efficiently. Specifically, we merge the feature maps from high to low layers in an iterative way, which handles different scales of hands better with less time overhead comparing to concatenating them simply. Moreover, we develop the Complementary Weighted Fusion (CWF) block to make full use of the distinctive features among multiple layers to achieve scale invariance. To deal with rotated hand detection, we present the rotation map to get rid of complex rotation and derotation layers. Besides, we design the multi-scale loss scheme to accelerate the training process significantly by adding supervision to the intermediate layers of the network. Compared with the state-of-the-art methods, our algorithm shows comparable accuracy and runs a 4.23 times faster speed on the VIVA dataset and achieves better average precision on Oxford hand detection dataset at a speed of 62.5 fps.