 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Driven Multimodal LLM for Domain Generalization
Feb 27, 2026This paper addresses the domain generalization (DG) problem in deep learning. While most DG methods focus on enforcing visual feature invariance, we leverage the reasoning capability of multimodal large language models (MLLMs) and explore the potential of constructing reasoning chains that derives image categories to achieve more robust predictions under domain shift. To this end, we systematically study the role of reasoning in DG using DomainBed-Reasoning, a newly constructed extension of DomainBed dataset, in which each sample is paired with class-relevant reasoning chains. Our analysis reveals two key challenges: (i) fine-tuning MLLMs with reasoning chains for classification is more challenging than direct label supervision, since the model must optimize complex reasoning sequences before label prediction; and (ii) mismatches in reasoning patterns between supervision signals and fine-tuned MLLMs lead to a trade-off between semantic richness (informative but harder to optimize) and optimization efficiency (easier to optimize but less informative). To address these issues, we propose RD-MLDG (Reasoning-Driven Multimodal LLM for Domain Generalization), a framework with two components: (i) MTCT (Multi-Task Cross-Training), which introduces an additional direct classification pathway to guide reasoning supervision; and (ii) SARR (Self-Aligned Reasoning Regularization), which preserves the semantic richness of reasoning chains while mitigating reasoning-pattern mismatches via iterative self-labeling. Experiments on standard DomainBed datasets (PACS, VLCS, OfficeHome, TerraInc) demonstrate that RD-MLDG achieves state-of-the-art performances, highlighting reasoning as a promising complementary signal for robust out-of-domain generalization.
One Object, Multiple Lies: A Benchmark for Cross-task Adversarial Attack on Unified Vision-Language Models
Jul 10, 2025Unified vision-language models(VLMs) have recently shown remarkable progress, enabling a single model to flexibly address diverse tasks through different instructions within a shared computational architecture. This instruction-based control mechanism creates unique security challenges, as adversarial inputs must remain effective across multiple task instructions that may be unpredictably applied to process the same malicious content. In this paper, we introduce CrossVLAD, a new benchmark dataset carefully curated from MSCOCO with GPT-4-assisted annotations for systematically evaluating cross-task adversarial attacks on unified VLMs. CrossVLAD centers on the object-change objective-consistently manipulating a target object's classification across four downstream tasks-and proposes a novel success rate metric that measures simultaneous misclassification across all tasks, providing a rigorous evaluation of adversarial transferability. To tackle this challenge, we present CRAFT (Cross-task Region-based Attack Framework with Token-alignment), an efficient region-centric attack method. Extensive experiments on Florence-2 and other popular unified VLMs demonstrate that our method outperforms existing approaches in both overall cross-task attack performance and targeted object-change success rates, highlighting its effectiveness in adversarially influencing unified VLMs across diverse tasks.
Prompt Disentanglement via Language Guidance and Representation Alignment for Domain Generalization
Jul 03, 2025Domain Generalization (DG) seeks to develop a versatile model capable of performing effectively on unseen target domains. Notably, recent advances in pre-trained Visual Foundation Models (VFMs), such as CLIP, have demonstrated considerable potential in enhancing the generalization capabilities of deep learning models. Despite the increasing attention toward VFM-based domain prompt tuning within DG, the effective design of prompts capable of disentangling invariant features across diverse domains remains a critical challenge. In this paper, we propose addressing this challenge by leveraging the controllable and flexible language prompt of the VFM. Noting that the text modality of VFMs is naturally easier to disentangle, we introduce a novel framework for text feature-guided visual prompt tuning. This framework first automatically disentangles the text prompt using a large language model (LLM) and then learns domain-invariant visual representation guided by the disentangled text feature. However, relying solely on language to guide visual feature disentanglement has limitations, as visual features can sometimes be too complex or nuanced to be fully captured by descriptive text. To address this, we introduce Worst Explicit Representation Alignment (WERA), which extends text-guided visual prompts by incorporating an additional set of abstract prompts. These prompts enhance source domain diversity through stylized image augmentations, while alignment constraints ensure that visual representations remain consistent across both the original and augmented distributions. Experiments conducted on major DG datasets, including PACS, VLCS, OfficeHome, DomainNet, and TerraInc, demonstrate that our proposed method outperforms state-of-the-art DG methods.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025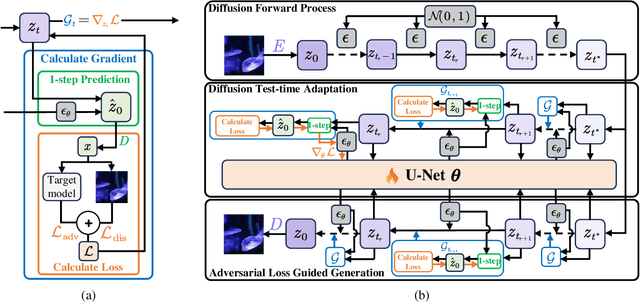
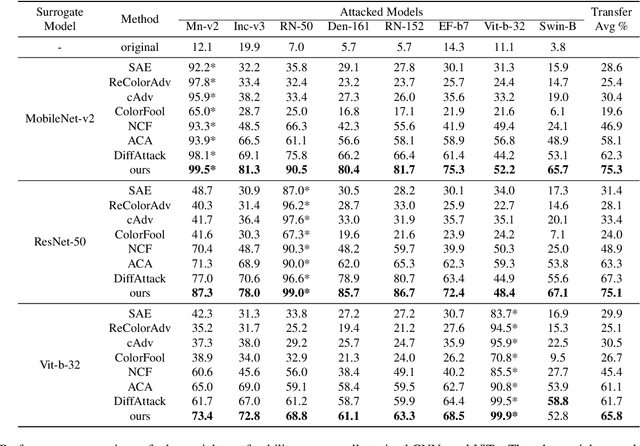
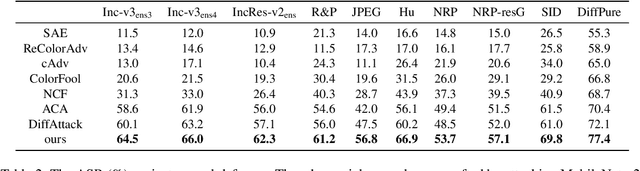

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.
Exploring Interpretability for Visual Prompt Tuning with Hierarchical Concepts
Mar 08, 2025Visual prompt tuning offers significant advantages for adapting pre-trained visual foundation models to specific tasks. However, current research provides limited insight into the interpretability of this approach, which is essential for enhancing AI reliability and enabling AI-driven knowledge discovery. In this paper, rather than learning abstract prompt embeddings, we propose the first framework, named Interpretable Visual Prompt Tuning (IVPT), to explore interpretability for visual prompts, by introducing hierarchical concept prototypes. Specifically, visual prompts are linked to human-understandable semantic concepts, represented as a set of category-agnostic prototypes, each corresponding to a specific region of the image. Then, IVPT aggregates features from these regions to generate interpretable prompts, which are structured hierarchically to explain visual prompts at different granularities. Comprehensive qualitative and quantitative evaluations on fine-grained classification benchmarks show its superior interpretability and performance over conventional visual prompt tuning methods and existing interpretable methods.
VoLUT: Efficient Volumetric streaming enhanced by LUT-based super-resolution
Feb 17, 20253D volumetric video provides immersive experience and is gaining traction in digital media. Despite its rising popularity, the streaming of volumetric video content poses significant challenges due to the high data bandwidth requirement. A natural approach to mitigate the bandwidth issue is to reduce the volumetric video's data rate by downsampling the content prior to transmission. The video can then be upsampled at the receiver's end using a super-resolution (SR) algorithm to reconstruct the high-resolution details. While super-resolution techniques have been extensively explored and advanced for 2D video content, there is limited work on SR algorithms tailored for volumetric videos. To address this gap and the growing need for efficient volumetric video streaming, we have developed VoLUT with a new SR algorithm specifically designed for volumetric content. Our algorithm uniquely harnesses the power of lookup tables (LUTs) to facilitate the efficient and accurate upscaling of low-resolution volumetric data. The use of LUTs enables our algorithm to quickly reference precomputed high-resolution values, thereby significantly reducing the computational complexity and time required for upscaling. We further apply adaptive video bit rate algorithm (ABR) to dynamically determine the downsampling rate according to the network condition and stream the selected video rate to the receiver. Compared to related work, VoLUT is the first to enable high-quality 3D SR on commodity mobile devices at line-rate. Our evaluation shows VoLUT can reduce bandwidth usage by 70% , boost QoE by 36.7% for volumetric video streaming and achieve 3D SR speed-up with no quality compromise.
Real-Time Neural-Enhancement for Online Cloud Gaming
Jan 12, 2025



Online Cloud gaming demands real-time, high-quality video transmission across variable wide-area networks (WANs). Neural-enhanced video transmission algorithms employing super-resolution (SR) for video quality enhancement have effectively challenged WAN environments. However, these SR-based methods require intensive fine-tuning for the whole video, making it infeasible in diverse online cloud gaming. To address this, we introduce River, a cloud gaming delivery framework designed based on the observation that video segment features in cloud gaming are typically repetitive and redundant. This permits a significant opportunity to reuse fine-tuned SR models, reducing the fine-tuning latency of minutes to query latency of milliseconds. To enable the idea, we design a practical system that addresses several challenges, such as model organization, online model scheduler, and transfer strategy. River first builds a content-aware encoder that fine-tunes SR models for diverse video segments and stores them in a lookup table. When delivering cloud gaming video streams online, River checks the video features and retrieves the most relevant SR models to enhance the frame quality. Meanwhile, if no existing SR model performs well enough for some video segments, River will further fine-tune new models and update the lookup table. Finally, to avoid the overhead of streaming model weight to the clients, River designs a prefetching strategy that predicts the models with the highest possibility of being retrieved. Our evaluation based on real video game streaming demonstrates River can reduce redundant training overhead by 44% and improve the Peak-Signal-to-Noise-Ratio by 1.81dB compared to the SOTA solutions. Practical deployment shows River meets real-time requirements, achieving approximately 720p 20fps on mobile devices.
HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling
Aug 27, 2024



Prompt learning has become a prevalent strategy for adapting vision-language foundation models (VLMs) such as CLIP to downstream tasks. With the emergence of large language models (LLMs), recent studies have explored the potential of using category-related descriptions to enhance prompt effectiveness. However, conventional descriptions lack explicit structured information necessary to represent the interconnections among key elements like entities or attributes with relation to a particular category. Since existing prompt tuning methods give little consideration to managing structured knowledge, this paper advocates leveraging LLMs to construct a graph for each description to prioritize such structured knowledge. Consequently, we propose a novel approach called Hierarchical Prompt Tuning (HPT), enabling simultaneous modeling of both structured and conventional linguistic knowledge. Specifically, we introduce a relationship-guided attention module to capture pair-wise associations among entities and attributes for low-level prompt learning. In addition, by incorporating high-level and global-level prompts modeling overall semantics, the proposed hierarchical structure forges cross-level interlinks and empowers the model to handle more complex and long-term relationships. Finally, by enhancing multi-granularity knowledge generation, redesigning the relationship-driven attention re-weighting module, and incorporating consistent constraints on the hierarchical text encoder, we propose HPT++, which further improves the performance of HPT. Our experiments are conducted across a wide range of evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization. Extensive results and ablation studies demonstrate the effectiveness of our methods, which consistently outperform existing SOTA methods.
ActPrompt: In-Domain Feature Adaptation via Action Cues for Video Temporal Grounding
Aug 13, 2024Video temporal grounding is an emerging topic aiming to identify specific clips within videos. In addition to pre-trained video models, contemporary methods utilize pre-trained vision-language models (VLM) to capture detailed characteristics of diverse scenes and objects from video frames. However, as pre-trained on images, VLM may struggle to distinguish action-sensitive patterns from static objects, making it necessary to adapt them to specific data domains for effective feature representation over temporal grounding. We address two primary challenges to achieve this goal. Specifically, to mitigate high adaptation costs, we propose an efficient preliminary in-domain fine-tuning paradigm for feature adaptation, where downstream-adaptive features are learned through several pretext tasks. Furthermore, to integrate action-sensitive information into VLM, we introduce Action-Cue-Injected Temporal Prompt Learning (ActPrompt), which injects action cues into the image encoder of VLM for better discovering action-sensitive patterns. Extensive experiments demonstrate that ActPrompt is an off-the-shelf training framework that can be effectively applied to various SOTA methods, resulting in notable improvements. The complete code used in this study is provided in the supplementary materials.
DiffPhysBA: Diffusion-based Physical Backdoor Attack against Person Re-Identification in Real-World
May 30, 2024



Person Re-Identification (ReID) systems pose a significant security risk from backdoor attacks, allowing adversaries to evade tracking or impersonate others. Beyond recognizing this issue, we investigate how backdoor attacks can be deployed in real-world scenarios, where a ReID model is typically trained on data collected in the digital domain and then deployed in a physical environment. This attack scenario requires an attack flow that embeds backdoor triggers in the digital domain realistically enough to also activate the buried backdoor in person ReID models in the physical domain. This paper realizes this attack flow by leveraging a diffusion model to generate realistic accessories on pedestrian images (e.g., bags, hats, etc.) as backdoor triggers. However, the noticeable domain gap between the triggers generated by the off-the-shelf diffusion model and their physical counterparts results in a low attack success rate. Therefore, we introduce a novel diffusion-based physical backdoor attack (DiffPhysBA) method that adopts a training-free similarity-guided sampling process to enhance the resemblance between generated and physical triggers. Consequently, DiffPhysBA can generate realistic attributes as semantic-level triggers in the digital domain and provides higher physical ASR compared to the direct paste method by 25.6% on the real-world test set. Through evaluations on newly proposed real-world and synthetic ReID test sets, DiffPhysBA demonstrates an impressive success rate exceeding 90% in both the digital and physical domains. Notably, it excels in digital stealth metrics and can effectively evade state-of-the-art defense methods.