 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Reward as Condition for Instruction-based Image Editing
Nov 06, 2024
High-quality training triplets (instruction, original image, edited image) are essential for instruction-based image editing. Predominant training datasets (e.g., InsPix2Pix) are created using text-to-image generative models (e.g., Stable Diffusion, DALL-E) which are not trained for image editing. Accordingly, these datasets suffer from inaccurate instruction following, poor detail preserving, and generation artifacts. In this paper, we propose to address the training data quality issue with multi-perspective reward data instead of refining the ground-truth image quality. 1) we first design a quantitative metric system based on best-in-class LVLM (Large Vision Language Model), i.e., GPT-4o in our case, to evaluate the generation quality from 3 perspectives, namely, instruction following, detail preserving, and generation quality. For each perspective, we collected quantitative score in $0\sim 5$ and text descriptive feedback on the specific failure points in ground-truth edited images, resulting in a high-quality editing reward dataset, i.e., RewardEdit20K. 2) We further proposed a novel training framework to seamlessly integrate the metric output, regarded as multi-reward, into editing models to learn from the imperfect training triplets. During training, the reward scores and text descriptions are encoded as embeddings and fed into both the latent space and the U-Net of the editing models as auxiliary conditions. During inference, we set these additional conditions to the highest score with no text description for failure points, to aim at the best generation outcome. Experiments indicate that our multi-reward conditioned model outperforms its no-reward counterpart on two popular editing pipelines, i.e., InsPix2Pix and SmartEdit. The code and dataset will be released.
Edit3K: Universal Representation Learning for Video Editing Components
Mar 24, 2024This paper focuses on understanding the predominant video creation pipeline, i.e., compositional video editing with six main types of editing components, including video effects, animation, transition, filter, sticker, and text. In contrast to existing visual representation learning of visual materials (i.e., images/videos), we aim to learn visual representations of editing actions/components that are generally applied on raw materials. We start by proposing the first large-scale dataset for editing components of video creation, which covers about $3,094$ editing components with $618,800$ videos. Each video in our dataset is rendered by various image/video materials with a single editing component, which supports atomic visual understanding of different editing components. It can also benefit several downstream tasks, e.g., editing component recommendation, editing component recognition/retrieval, etc. Existing visual representation methods perform poorly because it is difficult to disentangle the visual appearance of editing components from raw materials. To that end, we benchmark popular alternative solutions and propose a novel method that learns to attend to the appearance of editing components regardless of raw materials. Our method achieves favorable results on editing component retrieval/recognition compared to the alternative solutions. A user study is also conducted to show that our representations cluster visually similar editing components better than other alternatives. Furthermore, our learned representations used to transition recommendation tasks achieve state-of-the-art results on the AutoTransition dataset. The code and dataset will be released for academic use.
Context-Guided Spatio-Temporal Video Grounding
Jan 03, 2024



Spatio-temporal video grounding (or STVG) task aims at locating a spatio-temporal tube for a specific instance given a text query. Despite advancements, current methods easily suffer the distractors or heavy object appearance variations in videos due to insufficient object information from the text, leading to degradation. Addressing this, we propose a novel framework, context-guided STVG (CG-STVG), which mines discriminative instance context for object in videos and applies it as a supplementary guidance for target localization. The key of CG-STVG lies in two specially designed modules, including instance context generation (ICG), which focuses on discovering visual context information (in both appearance and motion) of the instance, and instance context refinement (ICR), which aims to improve the instance context from ICG by eliminating irrelevant or even harmful information from the context. During grounding, ICG, together with ICR, are deployed at each decoding stage of a Transformer architecture for instance context learning. Particularly, instance context learned from one decoding stage is fed to the next stage, and leveraged as a guidance containing rich and discriminative object feature to enhance the target-awareness in decoding feature, which conversely benefits generating better new instance context for improving localization finally. Compared to existing methods, CG-STVG enjoys object information in text query and guidance from mined instance visual context for more accurate target localization. In our experiments on three benchmarks, including HCSTVG-v1/-v2 and VidSTG, CG-STVG sets new state-of-the-arts in m_tIoU and m_vIoU on all of them, showing its efficacy. The code will be released at https://github.com/HengLan/CGSTVG.
Local Compressed Video Stream Learning for Generic Event Boundary Detection
Sep 27, 2023



Generic event boundary detection aims to localize the generic, taxonomy-free event boundaries that segment videos into chunks. Existing methods typically require video frames to be decoded before feeding into the network, which contains significant spatio-temporal redundancy and demands considerable computational power and storage space. To remedy these issues, we propose a novel compressed video representation learning method for event boundary detection that is fully end-to-end leveraging rich information in the compressed domain, i.e., RGB, motion vectors, residuals, and the internal group of pictures (GOP) structure, without fully decoding the video. Specifically, we use lightweight ConvNets to extract features of the P-frames in the GOPs and spatial-channel attention module (SCAM) is designed to refine the feature representations of the P-frames based on the compressed information with bidirectional information flow. To learn a suitable representation for boundary detection, we construct the local frames bag for each candidate frame and use the long short-term memory (LSTM) module to capture temporal relationships. We then compute frame differences with group similarities in the temporal domain. This module is only applied within a local window, which is critical for event boundary detection. Finally a simple classifier is used to determine the event boundaries of video sequences based on the learned feature representation. To remedy the ambiguities of annotations and speed up the training process, we use the Gaussian kernel to preprocess the ground-truth event boundaries. Extensive experiments conducted on the Kinetics-GEBD and TAPOS datasets demonstrate that the proposed method achieves considerable improvements compared to previous end-to-end approach while running at the same speed. The code is available at https://github.com/GX77/LCVSL.
Collaborative Three-Stream Transformers for Video Captioning
Sep 18, 2023



As the most critical components in a sentence, subject, predicate and object require special attention in the video captioning task. To implement this idea, we design a novel framework, named COllaborative three-Stream Transformers (COST), to model the three parts separately and complement each other for better representation. Specifically, COST is formed by three branches of transformers to exploit the visual-linguistic interactions of different granularities in spatial-temporal domain between videos and text, detected objects and text, and actions and text. Meanwhile, we propose a cross-granularity attention module to align the interactions modeled by the three branches of transformers, then the three branches of transformers can support each other to exploit the most discriminative semantic information of different granularities for accurate predictions of captions. The whole model is trained in an end-to-end fashion. Extensive experiments conducted on three large-scale challenging datasets, i.e., YouCookII, ActivityNet Captions and MSVD, demonstrate that the proposed method performs favorably against the state-of-the-art methods.
Unsupervised Domain Adaptive Detection with Network Stability Analysis
Aug 16, 2023



Domain adaptive detection aims to improve the generality of a detector, learned from the labeled source domain, on the unlabeled target domain. In this work, drawing inspiration from the concept of stability from the control theory that a robust system requires to remain consistent both externally and internally regardless of disturbances, we propose a novel framework that achieves unsupervised domain adaptive detection through stability analysis. In specific, we treat discrepancies between images and regions from different domains as disturbances, and introduce a novel simple but effective Network Stability Analysis (NSA) framework that considers various disturbances for domain adaptation. Particularly, we explore three types of perturbations including heavy and light image-level disturbances and instancelevel disturbance. For each type, NSA performs external consistency analysis on the outputs from raw and perturbed images and/or internal consistency analysis on their features, using teacher-student models. By integrating NSA into Faster R-CNN, we immediately achieve state-of-the-art results. In particular, we set a new record of 52.7% mAP on Cityscapes-to-FoggyCityscapes, showing the potential of NSA for domain adaptive detection. It is worth noticing, our NSA is designed for general purpose, and thus applicable to one-stage detection model (e.g., FCOS) besides the adopted one, as shown by experiments. https://github.com/tiankongzhang/NSA.
MaGIC: Multi-modality Guided Image Completion
May 19, 2023The vanilla image completion approaches are sensitive to the large missing regions due to limited available reference information for plausible generation. To mitigate this, existing methods incorporate the extra cue as a guidance for image completion. Despite improvements, these approaches are often restricted to employing a single modality (e.g., segmentation or sketch maps), which lacks scalability in leveraging multi-modality for more plausible completion. In this paper, we propose a novel, simple yet effective method for Multi-modal Guided Image Completion, dubbed MaGIC, which not only supports a wide range of single modality as the guidance (e.g., text, canny edge, sketch, segmentation, reference image, depth, and pose), but also adapts to arbitrarily customized combination of these modalities (i.e., arbitrary multi-modality) for image completion. For building MaGIC, we first introduce a modality-specific conditional U-Net (MCU-Net) that injects single-modal signal into a U-Net denoiser for single-modal guided image completion. Then, we devise a consistent modality blending (CMB) method to leverage modality signals encoded in multiple learned MCU-Nets through gradient guidance in latent space. Our CMB is training-free, and hence avoids the cumbersome joint re-training of different modalities, which is the secret of MaGIC to achieve exceptional flexibility in accommodating new modalities for completion. Experiments show the superiority of MaGIC over state-of-arts and its generalization to various completion tasks including in/out-painting and local editing. Our project with code and models is available at yeates.github.io/MaGIC-Page/.
Text with Knowledge Graph Augmented Transformer for Video Captioning
Mar 25, 2023Video captioning aims to describe the content of videos using natural language. Although significant progress has been made, there is still much room to improve the performance for real-world applications, mainly due to the long-tail words challenge. In this paper, we propose a text with knowledge graph augmented transformer (TextKG) for video captioning. Notably, TextKG is a two-stream transformer, formed by the external stream and internal stream. The external stream is designed to absorb additional knowledge, which models the interactions between the additional knowledge, e.g., pre-built knowledge graph, and the built-in information of videos, e.g., the salient object regions, speech transcripts, and video captions, to mitigate the long-tail words challenge. Meanwhile, the internal stream is designed to exploit the multi-modality information in videos (e.g., the appearance of video frames, speech transcripts, and video captions) to ensure the quality of caption results. In addition, the cross attention mechanism is also used in between the two streams for sharing information. In this way, the two streams can help each other for more accurate results. Extensive experiments conducted on four challenging video captioning datasets, i.e., YouCookII, ActivityNet Captions, MSRVTT, and MSVD, demonstrate that the proposed method performs favorably against the state-of-the-art methods. Specifically, the proposed TextKG method outperforms the best published results by improving 18.7% absolute CIDEr scores on the YouCookII dataset.
Robust Domain Adaptive Object Detection with Unified Multi-Granularity Alignment
Jan 01, 2023



Domain adaptive detection aims to improve the generalization of detectors on target domain. To reduce discrepancy in feature distributions between two domains, recent approaches achieve domain adaption through feature alignment in different granularities via adversarial learning. However, they neglect the relationship between multiple granularities and different features in alignment, degrading detection. Addressing this, we introduce a unified multi-granularity alignment (MGA)-based detection framework for domain-invariant feature learning. The key is to encode the dependencies across different granularities including pixel-, instance-, and category-levels simultaneously to align two domains. Specifically, based on pixel-level features, we first develop an omni-scale gated fusion (OSGF) module to aggregate discriminative representations of instances with scale-aware convolutions, leading to robust multi-scale detection. Besides, we introduce multi-granularity discriminators to identify where, either source or target domains, different granularities of samples come from. Note that, MGA not only leverages instance discriminability in different categories but also exploits category consistency between two domains for detection. Furthermore, we present an adaptive exponential moving average (AEMA) strategy that explores model assessments for model update to improve pseudo labels and alleviate local misalignment problem, boosting detection robustness. Extensive experiments on multiple domain adaption scenarios validate the superiority of MGA over other approaches on FCOS and Faster R-CNN detectors. Code will be released at https://github.com/tiankongzhang/MGA.
High-Fidelity Image Inpainting with GAN Inversion
Aug 25, 2022
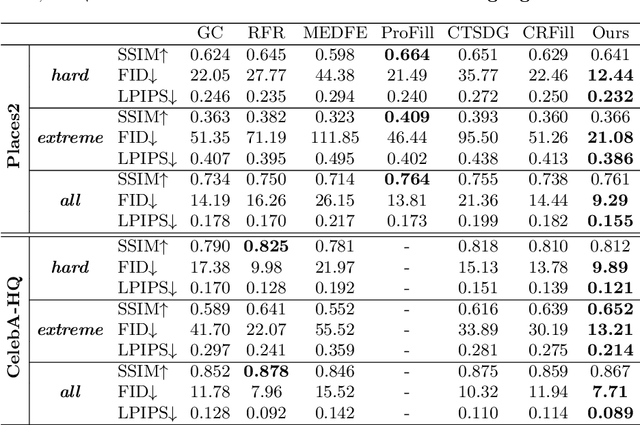
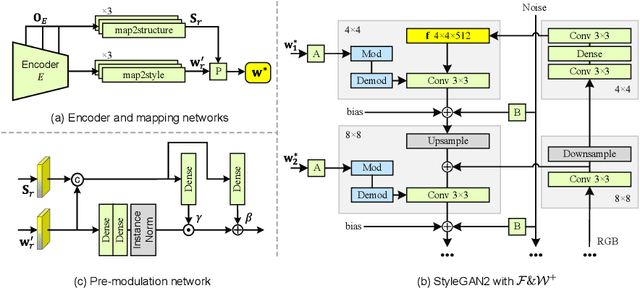
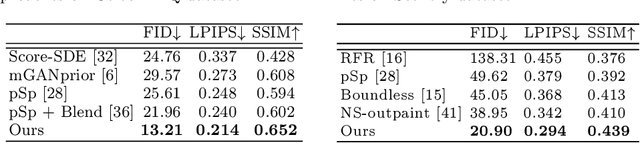
Image inpainting seeks a semantically consistent way to recover the corrupted image in the light of its unmasked content. Previous approaches usually reuse the well-trained GAN as effective prior to generate realistic patches for missing holes with GAN inversion. Nevertheless, the ignorance of a hard constraint in these algorithms may yield the gap between GAN inversion and image inpainting. Addressing this problem, in this paper, we devise a novel GAN inversion model for image inpainting, dubbed InvertFill, mainly consisting of an encoder with a pre-modulation module and a GAN generator with F&W+ latent space. Within the encoder, the pre-modulation network leverages multi-scale structures to encode more discriminative semantics into style vectors. In order to bridge the gap between GAN inversion and image inpainting, F&W+ latent space is proposed to eliminate glaring color discrepancy and semantic inconsistency. To reconstruct faithful and photorealistic images, a simple yet effective Soft-update Mean Latent module is designed to capture more diverse in-domain patterns that synthesize high-fidelity textures for large corruptions. Comprehensive experiments on four challenging datasets, including Places2, CelebA-HQ, MetFaces, and Scenery, demonstrate that our InvertFill outperforms the advanced approaches qualitatively and quantitatively and supports the completion of out-of-domain images well.