 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech
Apr 25, 2022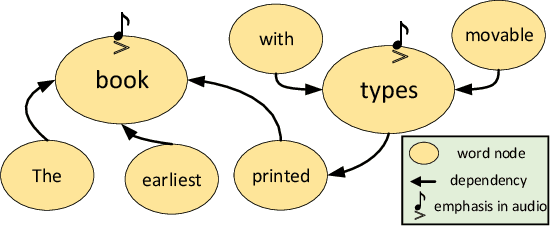
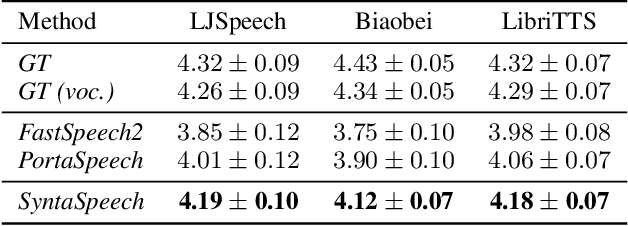
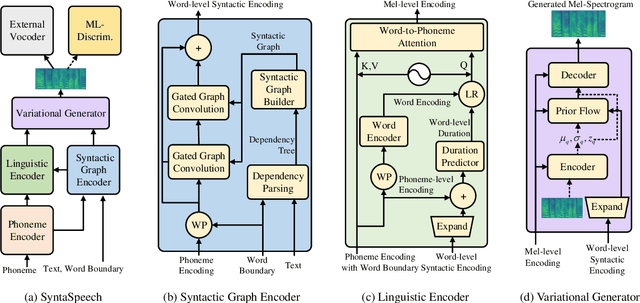
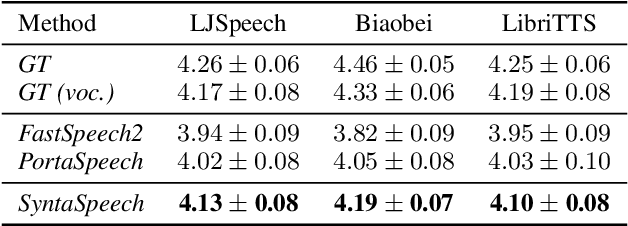
The recent progress in non-autoregressive text-to-speech (NAR-TTS) has made fast and high-quality speech synthesis possible. However, current NAR-TTS models usually use phoneme sequence as input and thus cannot understand the tree-structured syntactic information of the input sequence, which hurts the prosody modeling. To this end, we propose SyntaSpeech, a syntax-aware and light-weight NAR-TTS model, which integrates tree-structured syntactic information into the prosody modeling modules in PortaSpeech \cite{ren2021portaspeech}. Specifically, 1) We build a syntactic graph based on the dependency tree of the input sentence, then process the text encoding with a syntactic graph encoder to extract the syntactic information. 2) We incorporate the extracted syntactic encoding with PortaSpeech to improve the prosody prediction. 3) We introduce a multi-length discriminator to replace the flow-based post-net in PortaSpeech, which simplifies the training pipeline and improves the inference speed, while keeping the naturalness of the generated audio. Experiments on three datasets not only show that the tree-structured syntactic information grants SyntaSpeech the ability to synthesize better audio with expressive prosody, but also demonstrate the generalization ability of SyntaSpeech to adapt to multiple languages and multi-speaker text-to-speech. Ablation studies demonstrate the necessity of each component in SyntaSpeech. Source code and audio samples are available at https://syntaspeech.github.io
OakInk: A Large-scale Knowledge Repository for Understanding Hand-Object Interaction
Mar 29, 2022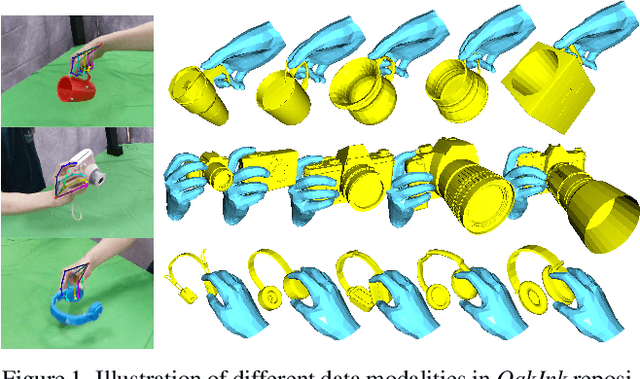
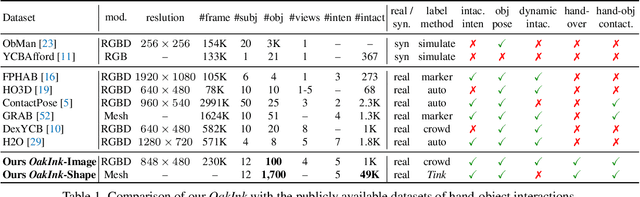
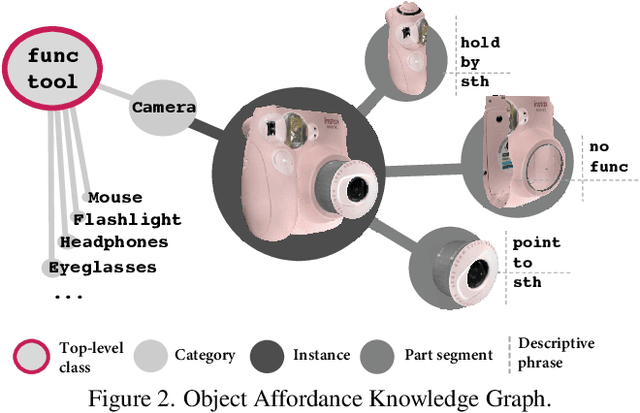
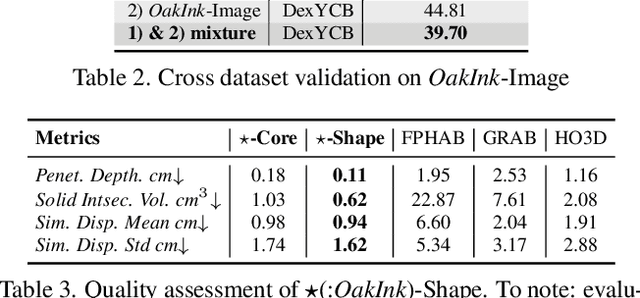
Learning how humans manipulate objects requires machines to acquire knowledge from two perspectives: one for understanding object affordances and the other for learning human's interactions based on the affordances. Even though these two knowledge bases are crucial, we find that current databases lack a comprehensive awareness of them. In this work, we propose a multi-modal and rich-annotated knowledge repository, OakInk, for visual and cognitive understanding of hand-object interactions. We start to collect 1,800 common household objects and annotate their affordances to construct the first knowledge base: Oak. Given the affordance, we record rich human interactions with 100 selected objects in Oak. Finally, we transfer the interactions on the 100 recorded objects to their virtual counterparts through a novel method: Tink. The recorded and transferred hand-object interactions constitute the second knowledge base: Ink. As a result, OakInk contains 50,000 distinct affordance-aware and intent-oriented hand-object interactions. We benchmark OakInk on pose estimation and grasp generation tasks. Moreover, we propose two practical applications of OakInk: intent-based interaction generation and handover generation. Our datasets and source code are publicly available at https://github.com/lixiny/OakInk.
Compositional Temporal Grounding with Structured Variational Cross-Graph Correspondence Learning
Mar 28, 2022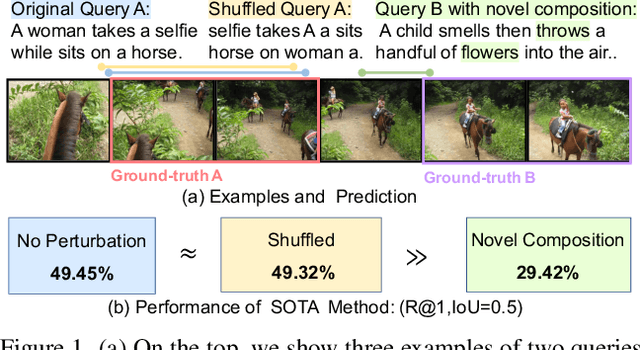
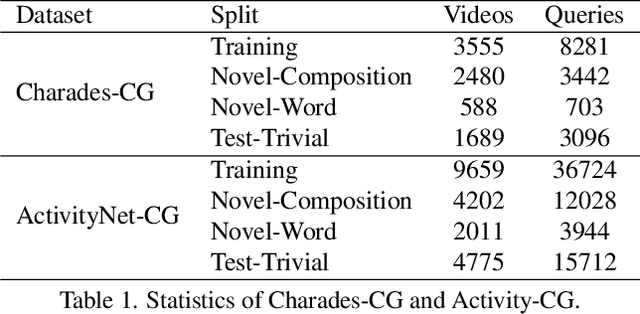
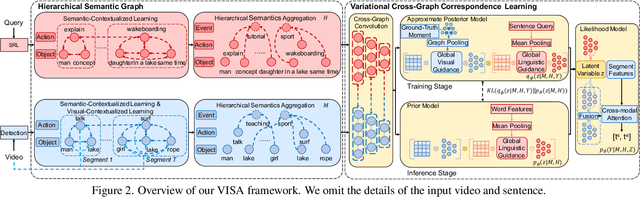
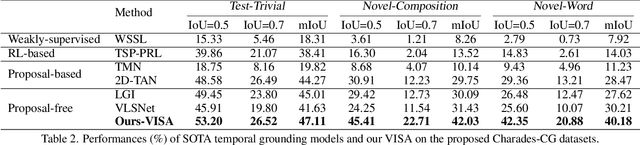
Temporal grounding in videos aims to localize one target video segment that semantically corresponds to a given query sentence. Thanks to the semantic diversity of natural language descriptions, temporal grounding allows activity grounding beyond pre-defined classes and has received increasing attention in recent years. The semantic diversity is rooted in the principle of compositionality in linguistics, where novel semantics can be systematically described by combining known words in novel ways (compositional generalization). However, current temporal grounding datasets do not specifically test for the compositional generalizability. To systematically measure the compositional generalizability of temporal grounding models, we introduce a new Compositional Temporal Grounding task and construct two new dataset splits, i.e., Charades-CG and ActivityNet-CG. Evaluating the state-of-the-art methods on our new dataset splits, we empirically find that they fail to generalize to queries with novel combinations of seen words. To tackle this challenge, we propose a variational cross-graph reasoning framework that explicitly decomposes video and language into multiple structured hierarchies and learns fine-grained semantic correspondence among them. Experiments illustrate the superior compositional generalizability of our approach. The repository of this work is at https://github.com/YYJMJC/ Compositional-Temporal-Grounding.
End-to-End Modeling via Information Tree for One-Shot Natural Language Spatial Video Grounding
Mar 15, 2022
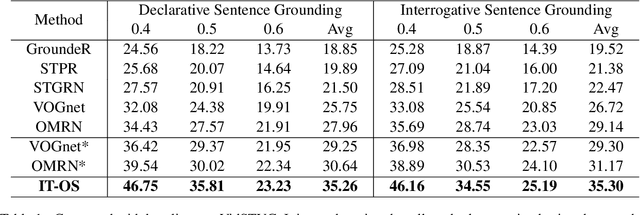
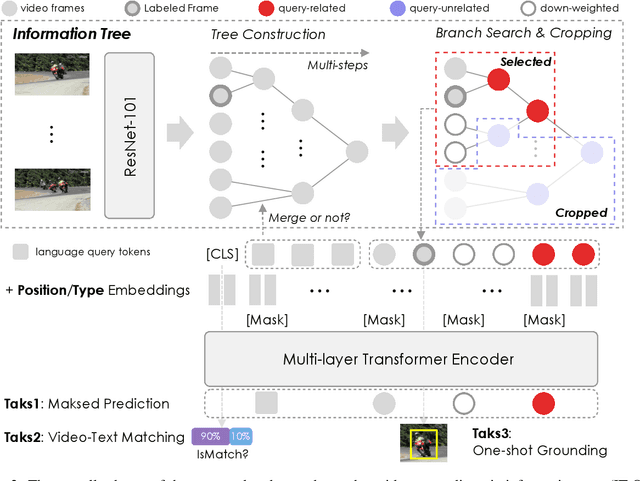
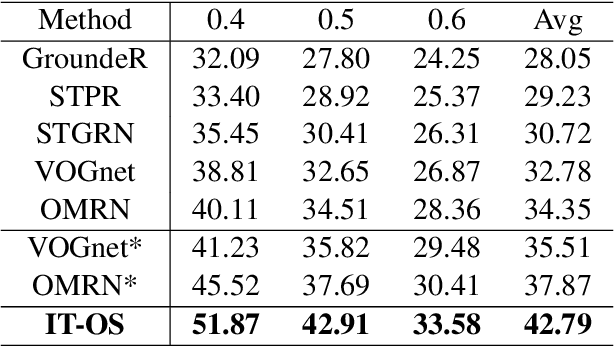
Natural language spatial video grounding aims to detect the relevant objects in video frames with descriptive sentences as the query. In spite of the great advances, most existing methods rely on dense video frame annotations, which require a tremendous amount of human effort. To achieve effective grounding under a limited annotation budget, we investigate one-shot video grounding, and learn to ground natural language in all video frames with solely one frame labeled, in an end-to-end manner. One major challenge of end-to-end one-shot video grounding is the existence of videos frames that are either irrelevant to the language query or the labeled frames. Another challenge relates to the limited supervision, which might result in ineffective representation learning. To address these challenges, we designed an end-to-end model via Information Tree for One-Shot video grounding (IT-OS). Its key module, the information tree, can eliminate the interference of irrelevant frames based on branch search and branch cropping techniques. In addition, several self-supervised tasks are proposed based on the information tree to improve the representation learning under insufficient labeling. Experiments on the benchmark dataset demonstrate the effectiveness of our model.
A Novel Architecture Slimming Method for Network Pruning and Knowledge Distillation
Feb 21, 2022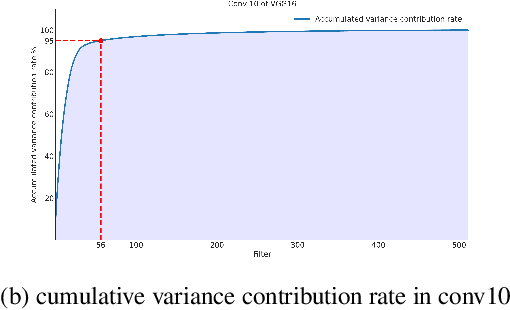
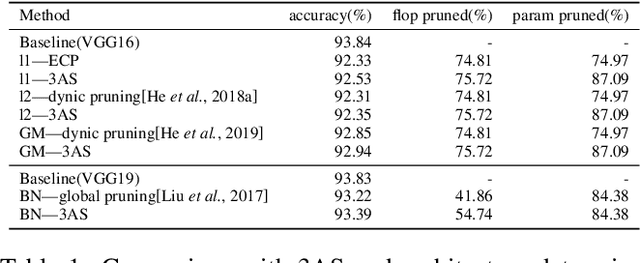
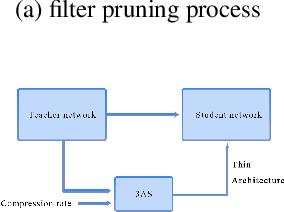
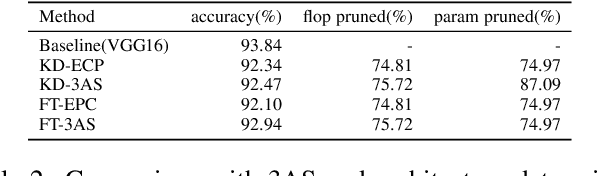
Network pruning and knowledge distillation are two widely-known model compression methods that efficiently reduce computation cost and model size. A common problem in both pruning and distillation is to determine compressed architecture, i.e., the exact number of filters per layer and layer configuration, in order to preserve most of the original model capacity. In spite of the great advances in existing works, the determination of an excellent architecture still requires human interference or tremendous experimentations. In this paper, we propose an architecture slimming method that automates the layer configuration process. We start from the perspective that the capacity of the over-parameterized model can be largely preserved by finding the minimum number of filters preserving the maximum parameter variance per layer, resulting in a thin architecture. We formulate the determination of compressed architecture as a one-step orthogonal linear transformation, and integrate principle component analysis (PCA), where the variances of filters in the first several projections are maximized. We demonstrate the rationality of our analysis and the effectiveness of the proposed method through extensive experiments. In particular, we show that under the same overall compression rate, the compressed architecture determined by our method shows significant performance gain over baselines after pruning and distillation. Surprisingly, we find that the resulting layer-wise compression rates correspond to the layer sensitivities found by existing works through tremendous experimentations.
Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB Images
Jan 01, 2022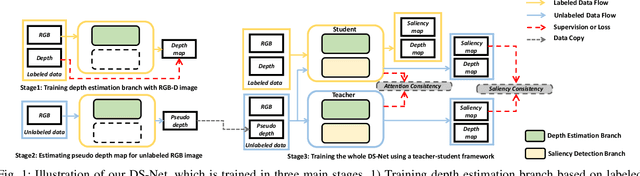
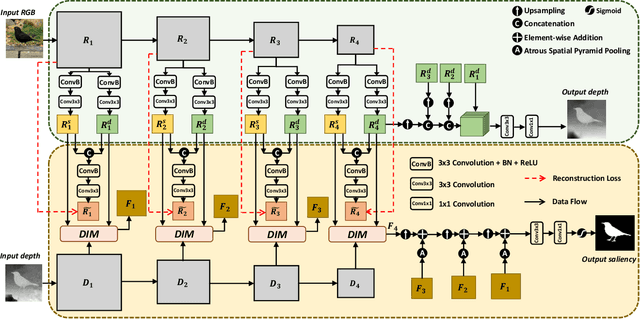
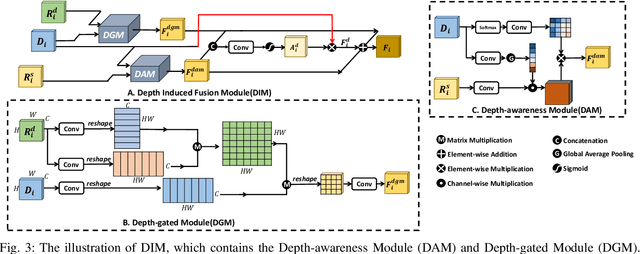

Training deep models for RGB-D salient object detection (SOD) often requires a large number of labeled RGB-D images. However, RGB-D data is not easily acquired, which limits the development of RGB-D SOD techniques. To alleviate this issue, we present a Dual-Semi RGB-D Salient Object Detection Network (DS-Net) to leverage unlabeled RGB images for boosting RGB-D saliency detection. We first devise a depth decoupling convolutional neural network (DDCNN), which contains a depth estimation branch and a saliency detection branch. The depth estimation branch is trained with RGB-D images and then used to estimate the pseudo depth maps for all unlabeled RGB images to form the paired data. The saliency detection branch is used to fuse the RGB feature and depth feature to predict the RGB-D saliency. Then, the whole DDCNN is assigned as the backbone in a teacher-student framework for semi-supervised learning. Moreover, we also introduce a consistency loss on the intermediate attention and saliency maps for the unlabeled data, as well as a supervised depth and saliency loss for labeled data. Experimental results on seven widely-used benchmark datasets demonstrate that our DDCNN outperforms state-of-the-art methods both quantitatively and qualitatively. We also demonstrate that our semi-supervised DS-Net can further improve the performance, even when using an RGB image with the pseudo depth map.
Multi-agent Communication with Graph Information Bottleneck under Limited Bandwidth
Dec 29, 2021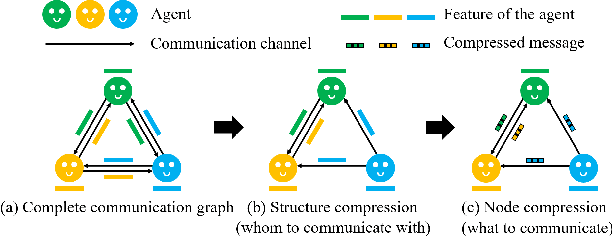
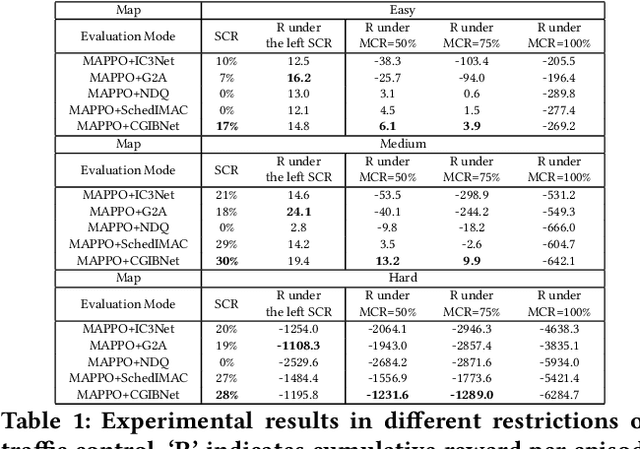
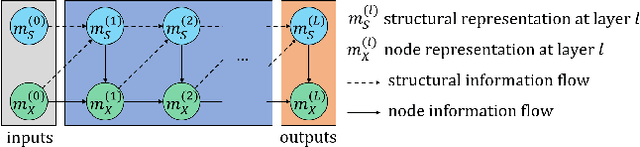
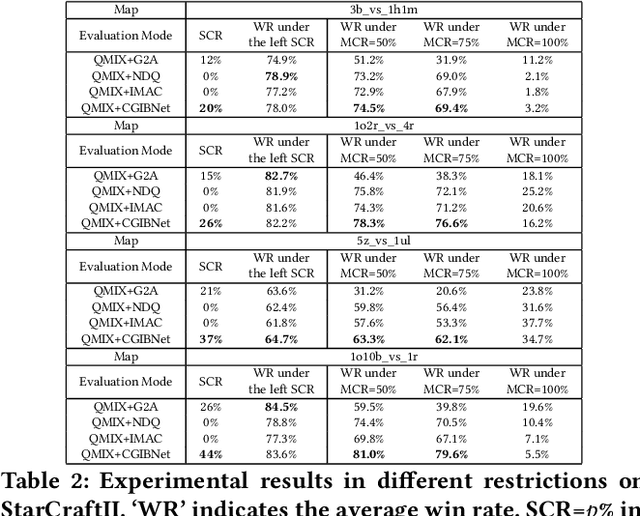
Recent studies have shown that introducing communication between agents can significantly improve overall performance in cooperative Multi-agent reinforcement learning (MARL). In many real-world scenarios, communication can be expensive and the bandwidth of the multi-agent system is subject to certain constraints. Redundant messages who occupy the communication resources can block the transmission of informative messages and thus jeopardize the performance. In this paper, we aim to learn the minimal sufficient communication messages. First, we initiate the communication between agents by a complete graph. Then we introduce the graph information bottleneck (GIB) principle into this complete graph and derive the optimization over graph structures. Based on the optimization, a novel multi-agent communication module, called CommGIB, is proposed, which effectively compresses the structure information and node information in the communication graph to deal with bandwidth-constrained settings. Extensive experiments in Traffic Control and StanCraft II are conducted. The results indicate that the proposed methods can achieve better performance in bandwidth-restricted settings compared with state-of-the-art algorithms, with especially large margins in large-scale multi-agent tasks.
Feature Distillation Interaction Weighting Network for Lightweight Image Super-Resolution
Dec 16, 2021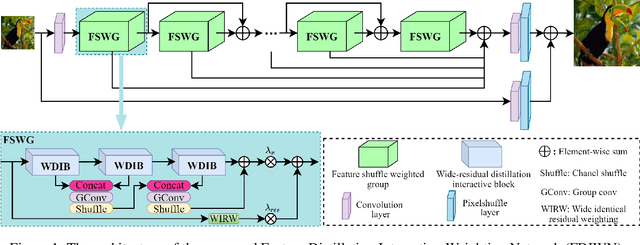
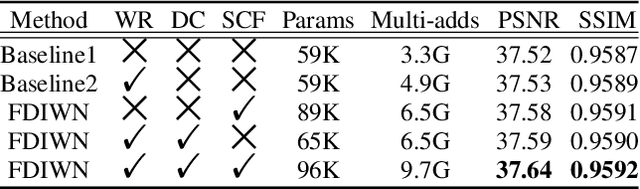
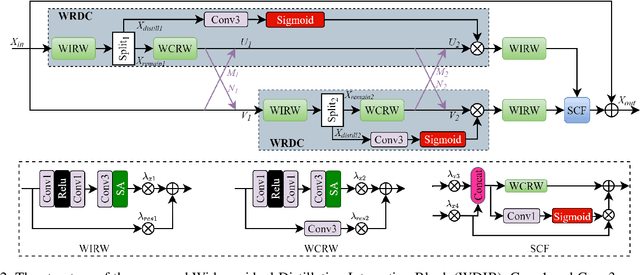
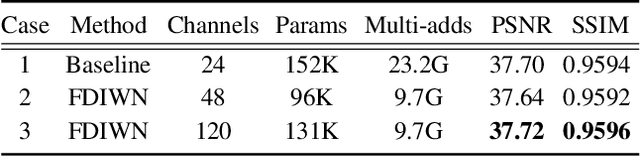
Convolutional neural networks based single-image super-resolution (SISR) has made great progress in recent years. However, it is difficult to apply these methods to real-world scenarios due to the computational and memory cost. Meanwhile, how to take full advantage of the intermediate features under the constraints of limited parameters and calculations is also a huge challenge. To alleviate these issues, we propose a lightweight yet efficient Feature Distillation Interaction Weighted Network (FDIWN). Specifically, FDIWN utilizes a series of specially designed Feature Shuffle Weighted Groups (FSWG) as the backbone, and several novel mutual Wide-residual Distillation Interaction Blocks (WDIB) form an FSWG. In addition, Wide Identical Residual Weighting (WIRW) units and Wide Convolutional Residual Weighting (WCRW) units are introduced into WDIB for better feature distillation. Moreover, a Wide-Residual Distillation Connection (WRDC) framework and a Self-Calibration Fusion (SCF) unit are proposed to interact features with different scales more flexibly and efficiently.Extensive experiments show that our FDIWN is superior to other models to strike a good balance between model performance and efficiency. The code is available at https://github.com/IVIPLab/FDIWN.
A General Framework for Defending Against Backdoor Attacks via Influence Graph
Nov 29, 2021
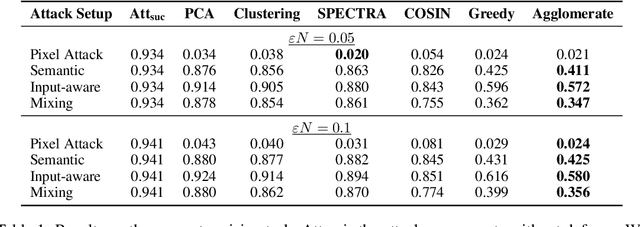
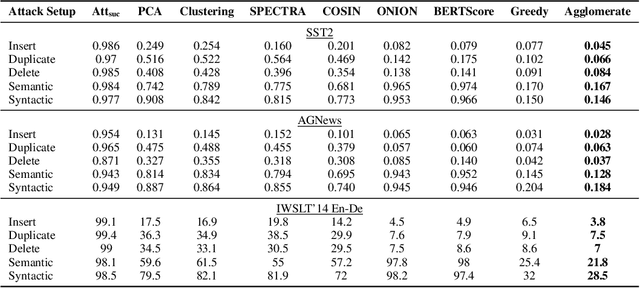
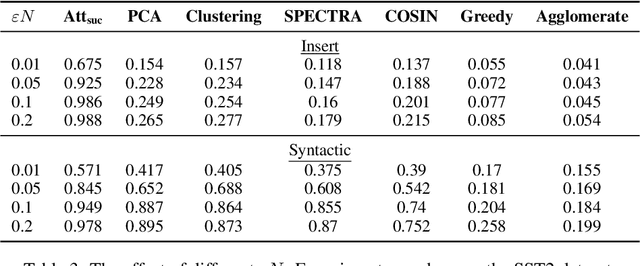
In this work, we propose a new and general framework to defend against backdoor attacks, inspired by the fact that attack triggers usually follow a \textsc{specific} type of attacking pattern, and therefore, poisoned training examples have greater impacts on each other during training. We introduce the notion of the {\it influence graph}, which consists of nodes and edges respectively representative of individual training points and associated pair-wise influences. The influence between a pair of training points represents the impact of removing one training point on the prediction of another, approximated by the influence function \citep{koh2017understanding}. Malicious training points are extracted by finding the maximum average sub-graph subject to a particular size. Extensive experiments on computer vision and natural language processing tasks demonstrate the effectiveness and generality of the proposed framework.
Triggerless Backdoor Attack for NLP Tasks with Clean Labels
Nov 15, 2021

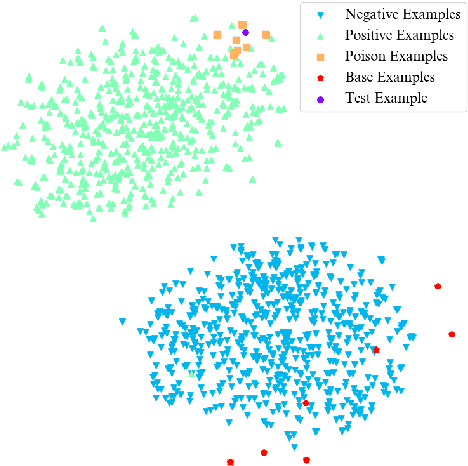
Backdoor attacks pose a new threat to NLP models. A standard strategy to construct poisoned data in backdoor attacks is to insert triggers (e.g., rare words) into selected sentences and alter the original label to a target label. This strategy comes with a severe flaw of being easily detected from both the trigger and the label perspectives: the trigger injected, which is usually a rare word, leads to an abnormal natural language expression, and thus can be easily detected by a defense model; the changed target label leads the example to be mistakenly labeled and thus can be easily detected by manual inspections. To deal with this issue, in this paper, we propose a new strategy to perform textual backdoor attacks which do not require an external trigger, and the poisoned samples are correctly labeled. The core idea of the proposed strategy is to construct clean-labeled examples, whose labels are correct but can lead to test label changes when fused with the training set. To generate poisoned clean-labeled examples, we propose a sentence generation model based on the genetic algorithm to cater to the non-differentiable characteristic of text data. Extensive experiments demonstrate that the proposed attacking strategy is not only effective, but more importantly, hard to defend due to its triggerless and clean-labeled nature. Our work marks the first step towards developing triggerless attacking strategies in NLP.