 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Articulated Parts Perception in Robot Manipulation
Jun 06, 2026We are surrounded by various objects with movable, articulated parts, e.g., box, handle, door. An accurate and generalizable perception of articulated parts is essential to enhance robotic manipulation capabilities. Building on this need, recent efforts in articulated parts perception have followed two main directions: One line of work uses pose-based representation, which requires high manual cost; in parallel, affordance-based methods extract future object motion from point tracking without additional manual efforts, but suffer from low-quality data. In this paper, we propose a new representation of articulated parts, Geometric Primary Structure (GPS), an abstraction of the part geometry structure to balance scalability and quality. For efficient and scalable data collection, GPS is integrated with a portable Virtual Reality (VR) device and requires only one minute to annotate one object sequence. This direct human annotation provides higher quality than the estimated affordance. With this efficient VR-GPS system, we collect 41K frames for 234 objects across six part classes, and train a generalizable GPS model with a single RGB-D object image as input. For object manipulation, we deploy a heuristic policy based on GPS prediction. Without any in-domain fine-tuning, our method achieves an 73% success rate, covering 270 initial states for 9 objects. Our code, data and reusable tool are available at https://enlighten0707.github.io/gps.
X-Imitator: Spatial-Aware Imitation Learning via Bidirectional Action-Pose Interaction
May 12, 2026Effectively handling the interplay between spatial perception and action generation remains a critical bottleneck in robotic manipulation. Existing methods typically treat spatial perception and action execution as decoupled or strictly unidirectional processes, fundamentally restricting a robot's ability to master complex manipulation tasks. To address this, we propose X-Imitator, a versatile dual-path framework that models spatial perception and action execution as a tightly coupled bidirectional loop. By reciprocally conditioning current pose predictions on past actions and vice versa, this framework enables continuous mutual refinement between spatial reasoning and action generation. This joint modeling exactly mimics human internal forward models. Designed as a modular architecture, the system can be seamlessly integrated into various visuomotor policies. Extensive experiments across 24 simulated and 3 real-world tasks demonstrate that our framework significantly outperforms both vanilla policies and prior methods utilizing explicit pose guidance. The code will be open sourced.
A Progressive Training Strategy for Vision-Language Models to Counteract Spatio-Temporal Hallucinations in Embodied Reasoning
Apr 12, 2026Vision-Language Models (VLMs) have made significant strides in static image understanding but continue to face critical hurdles in spatiotemporal reasoning. A major bottleneck is "multi-image reasoning hallucination", where a massive performance drop between forward and reverse temporal queries reveals a dependence on superficial shortcuts instead of genuine causal understanding. To mitigate this, we first develop a new Chain-of-Thought (CoT) dataset that decomposes intricate reasoning into detailed spatiotemporal steps and definitive judgments. Building on this, we present a progressive training framework: it initiates with supervised pre-training on our CoT dataset to instill logical structures, followed by fine-tuning with scalable weakly-labeled data for broader generalization. Our experiments demonstrate that this approach not only improves backbone accuracy but also slashes the forward-backward performance gap from over 70\% to only 6.53\%. This confirms the method's ability to develop authentic dynamic reasoning and reduce the inherent temporal biases of current VLMs.
From Perception to Planning: Evolving Ego-Centric Task-Oriented Spatiotemporal Reasoning via Curriculum Learning
Apr 12, 2026Modern vision-language models achieve strong performance in static perception, but remain limited in the complex spatiotemporal reasoning required for embodied, egocentric tasks. A major source of failure is their reliance on temporal priors learned from passive video data, which often leads to spatiotemporal hallucinations and poor generalization in dynamic environments. To address this, we present EgoTSR, a curriculum-based framework for learning task-oriented spatiotemporal reasoning. EgoTSR is built on the premise that embodied reasoning should evolve from explicit spatial understanding to internalized task-state assessment and finally to long-horizon planning. To support this paradigm, we construct EgoTSR-Data, a large-scale dataset comprising 46 million samples organized into three stages: Chain-of-Thought (CoT) supervision, weakly supervised tagging, and long-horizon sequences. Extensive experiments demonstrate that EgoTSR effectively eliminates chronological biases, achieving 92.4% accuracy on long-horizon logical reasoning tasks while maintaining high fine-grained perceptual precision, significantly outperforming existing open-source and closed-source state-of-the-art models.
LIDEA: Human-to-Robot Imitation Learning via Implicit Feature Distillation and Explicit Geometry Alignment
Apr 12, 2026Scaling up robot learning is hindered by the scarcity of robotic demonstrations, whereas human videos offer a vast, untapped source of interaction data. However, bridging the embodiment gap between human hands and robot arms remains a critical challenge. Existing cross-embodiment transfer strategies typically rely on visual editing, but they often introduce visual artifacts due to intrinsic discrepancies in visual appearance and 3D geometry. To address these limitations, we introduce LIDEA (Implicit Feature Distillation and Explicit Geometric Alignment), an imitation learning framework in which policy learning benefits from human demonstrations. In the 2D visual domain, LIDEA employs a dual-stage transitive distillation pipeline that aligns human and robot representations in a shared latent space. In the 3D geometric domain, we propose an embodiment-agnostic alignment strategy that explicitly decouples embodiment from interaction geometry, ensuring consistent 3D-aware perception. Extensive experiments empirically validate LIDEA from two perspectives: data efficiency and OOD robustness. Results show that human data substitutes up to 80% of costly robot demonstrations, and the framework successfully transfers unseen patterns from human videos for out-of-distribution generalization.
LaMP: Learning Vision-Language-Action Policies with 3D Scene Flow as Latent Motion Prior
Mar 26, 2026We introduce \textbf{LaMP}, a dual-expert Vision-Language-Action framework that embeds dense 3D scene flow as a latent motion prior for robotic manipulation. Existing VLA models regress actions directly from 2D semantic visual features, forcing them to learn complex 3D physical interactions implicitly. This implicit learning strategy degrades under unfamiliar spatial dynamics. LaMP addresses this limitation by aligning a flow-matching \emph{Motion Expert} with a policy-predicting \emph{Action Expert} through gated cross-attention. Specifically, the Motion Expert generates a one-step partially denoised 3D scene flow, and its hidden states condition the Action Expert without full multi-step reconstruction. We evaluate LaMP on the LIBERO, LIBERO-Plus, and SimplerEnv-WidowX simulation benchmarks as well as real-world experiments. LaMP consistently outperforms evaluated VLA baselines across LIBERO, LIBERO-Plus, and SimplerEnv-WidowX benchmarks, achieving the highest reported average success rates under the same training budgets. On LIBERO-Plus OOD perturbations, LaMP shows improved robustness with an average 9.7% gain over the strongest prior baseline. Our project page is available at https://summerwxk.github.io/lamp-project-page/.
VFM-Recon: Unlocking Cross-Domain Scene-Level Neural Reconstruction with Scale-Aligned Foundation Priors
Mar 13, 2026Scene-level neural volumetric reconstruction from monocular videos remains challenging, especially under severe domain shifts. Although recent advances in vision foundation models (VFMs) provide transferable generalized priors learned from large-scale data, their scaleambiguous predictions are incompatible with the scale consistency required by volumetric fusion. To address this gap, we present VFMRecon, the first attempt to bridge transferable VFM priors with scaleconsistent requirements in scene-level neural reconstruction. Specifically, we first introduce a lightweight scale alignment stage that restores multiview scale coherence. We then integrate pretrained VFM features into the neural volumetric reconstruction pipeline via lightweight task-specific adapters, which are trained for reconstruction while preserving the crossdomain robustness of pretrained representations. We train our model on ScanNet train split and evaluate on both in-distribution ScanNet test split and out-of-distribution TUM RGB-D and Tanks and Temples datasets. The results demonstrate that our model achieves state-of-theart performance across all datasets domains. In particular, on the challenging outdoor Tanks and Temples dataset, our model achieves an F1 score of 70.1 in reconstructed mesh evaluation, substantially outperforming the closest competitor, VGGT, which only attains 51.8.
AG-MPBS: a Mobility-Aware Prediction and Behavior-Based Scheduling Framework for Air-Ground Unmanned Systems
Dec 18, 2025



As unmanned systems such as Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) become increasingly important to applications like urban sensing and emergency response, efficiently recruiting these autonomous devices to perform time-sensitive tasks has become a critical challenge. This paper presents MPBS (Mobility-aware Prediction and Behavior-based Scheduling), a scalable task recruitment framework that treats each device as a recruitable "user". MPBS integrates three key modules: a behavior-aware KNN classifier, a time-varying Markov prediction model for forecasting device mobility, and a dynamic priority scheduling mechanism that considers task urgency and base station performance. By combining behavioral classification with spatiotemporal prediction, MPBS adaptively assigns tasks to the most suitable devices in real time. Experimental evaluations on the real-world GeoLife dataset show that MPBS significantly improves task completion efficiency and resource utilization. The proposed framework offers a predictive, behavior-aware solution for intelligent and collaborative scheduling in unmanned systems.
OmniCam: Unified Multimodal Video Generation via Camera Control
Apr 03, 2025

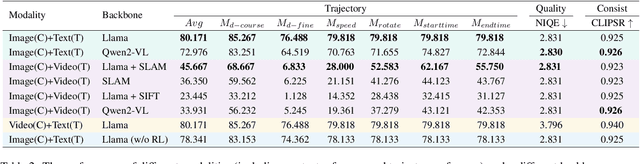
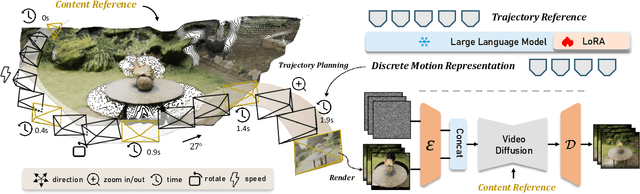
Camera control, which achieves diverse visual effects by changing camera position and pose, has attracted widespread attention. However, existing methods face challenges such as complex interaction and limited control capabilities. To address these issues, we present OmniCam, a unified multimodal camera control framework. Leveraging large language models and video diffusion models, OmniCam generates spatio-temporally consistent videos. It supports various combinations of input modalities: the user can provide text or video with expected trajectory as camera path guidance, and image or video as content reference, enabling precise control over camera motion. To facilitate the training of OmniCam, we introduce the OmniTr dataset, which contains a large collection of high-quality long-sequence trajectories, videos, and corresponding descriptions. Experimental results demonstrate that our model achieves state-of-the-art performance in high-quality camera-controlled video generation across various metrics.
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.