 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
Jun 01, 2022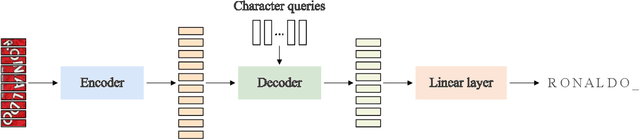

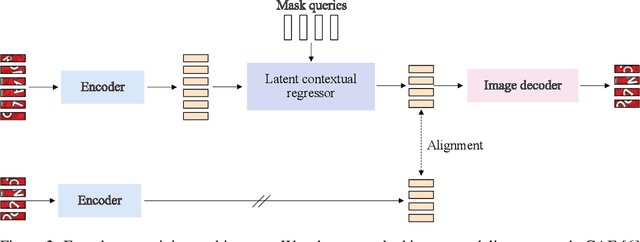

In this paper, we present a model pretraining technique, named MaskOCR, for text recognition. Our text recognition architecture is an encoder-decoder transformer: the encoder extracts the patch-level representations, and the decoder recognizes the text from the representations. Our approach pretrains both the encoder and the decoder in a sequential manner. (i) We pretrain the encoder in a self-supervised manner over a large set of unlabeled real text images. We adopt the masked image modeling approach, which shows the effectiveness for general images, expecting that the representations take on semantics. (ii) We pretrain the decoder over a large set of synthesized text images in a supervised manner and enhance the language modeling capability of the decoder by randomly masking some text image patches occupied by characters input to the encoder and accordingly the representations input to the decoder. Experiments show that the proposed MaskOCR approach achieves superior results on the benchmark datasets, including Chinese and English text images.
Few-Shot Font Generation by Learning Fine-Grained Local Styles
May 23, 2022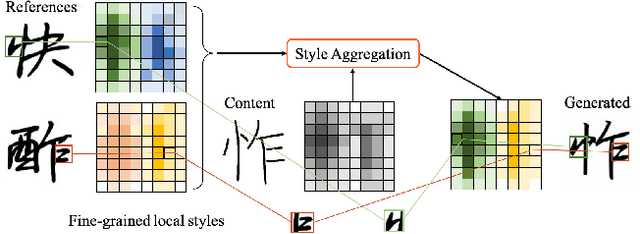
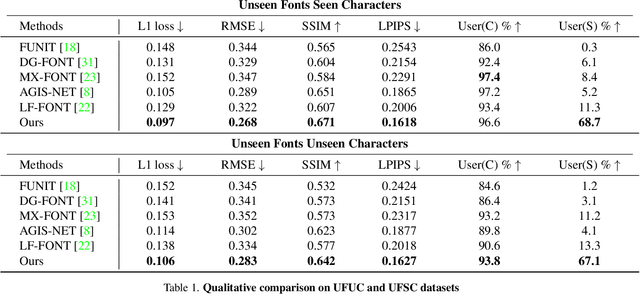
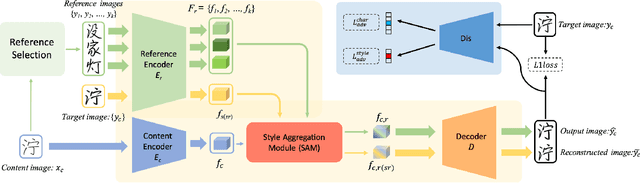
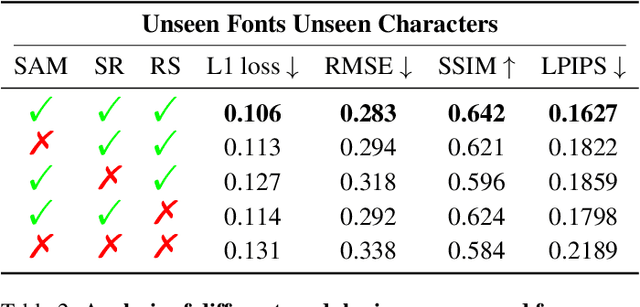
Few-shot font generation (FFG), which aims to generate a new font with a few examples, is gaining increasing attention due to the significant reduction in labor cost. A typical FFG pipeline considers characters in a standard font library as content glyphs and transfers them to a new target font by extracting style information from the reference glyphs. Most existing solutions explicitly disentangle content and style of reference glyphs globally or component-wisely. However, the style of glyphs mainly lies in the local details, i.e. the styles of radicals, components, and strokes together depict the style of a glyph. Therefore, even a single character can contain different styles distributed over spatial locations. In this paper, we propose a new font generation approach by learning 1) the fine-grained local styles from references, and 2) the spatial correspondence between the content and reference glyphs. Therefore, each spatial location in the content glyph can be assigned with the right fine-grained style. To this end, we adopt cross-attention over the representation of the content glyphs as the queries and the representations of the reference glyphs as the keys and values. Instead of explicitly disentangling global or component-wise modeling, the cross-attention mechanism can attend to the right local styles in the reference glyphs and aggregate the reference styles into a fine-grained style representation for the given content glyphs. The experiments show that the proposed method outperforms the state-of-the-art methods in FFG. In particular, the user studies also demonstrate the style consistency of our approach significantly outperforms previous methods.
Few-Shot Head Swapping in the Wild
Apr 27, 2022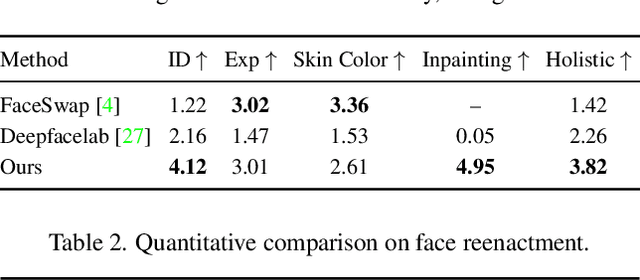
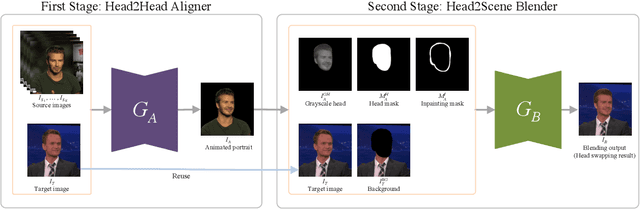
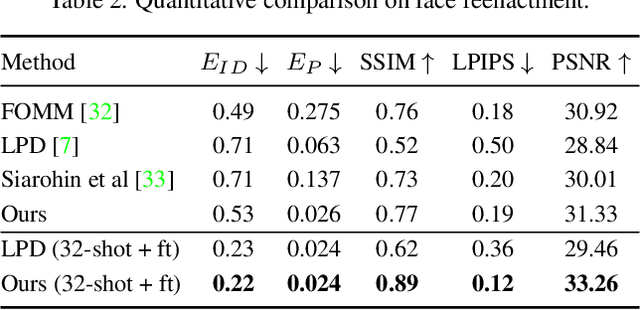
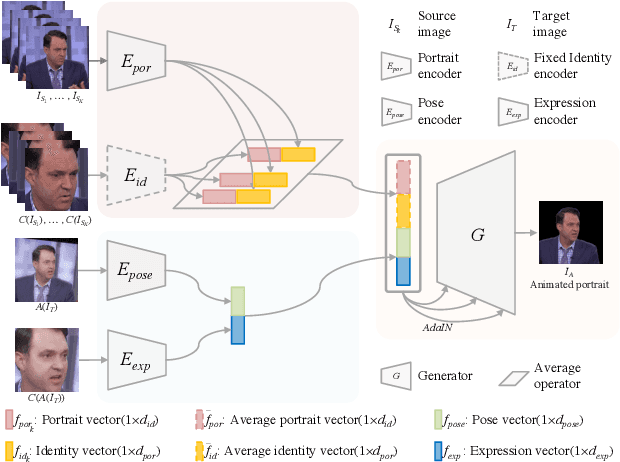
The head swapping task aims at flawlessly placing a source head onto a target body, which is of great importance to various entertainment scenarios. While face swapping has drawn much attention, the task of head swapping has rarely been explored, particularly under the few-shot setting. It is inherently challenging due to its unique needs in head modeling and background blending. In this paper, we present the Head Swapper (HeSer), which achieves few-shot head swapping in the wild through two delicately designed modules. Firstly, a Head2Head Aligner is devised to holistically migrate pose and expression information from the target to the source head by examining multi-scale information. Secondly, to tackle the challenges of skin color variations and head-background mismatches in the swapping procedure, a Head2Scene Blender is introduced to simultaneously modify facial skin color and fill mismatched gaps in the background around the head. Particularly, seamless blending is achieved with the help of a Semantic-Guided Color Reference Creation procedure and a Blending UNet. Extensive experiments demonstrate that the proposed method produces superior head swapping results in a variety of scenes.
Human-Object Interaction Detection via Disentangled Transformer
Apr 20, 2022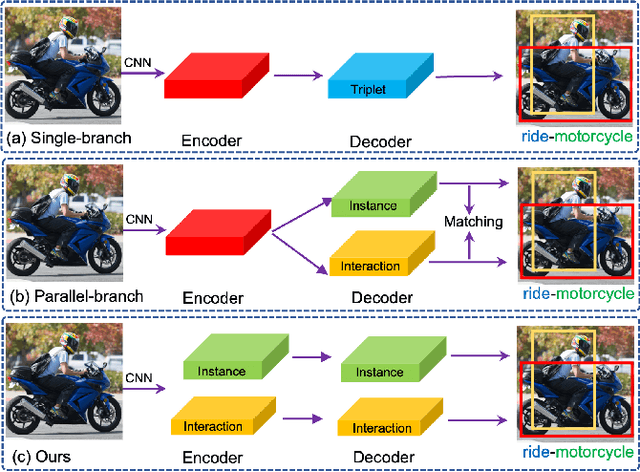
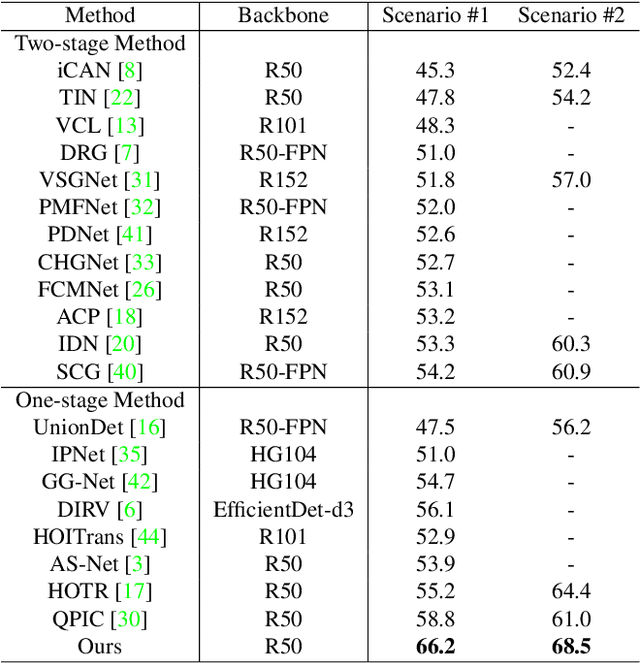
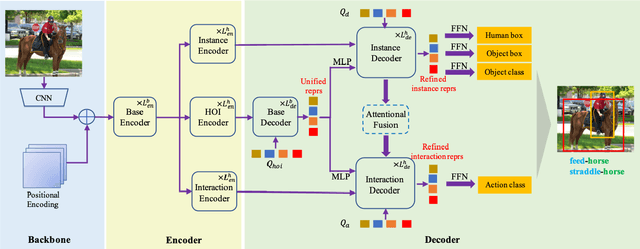
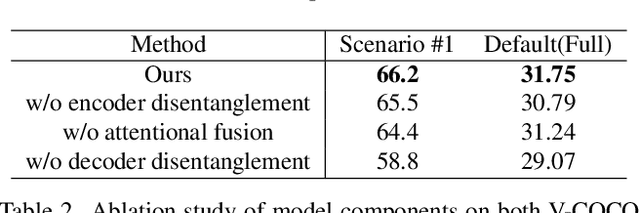
Human-Object Interaction Detection tackles the problem of joint localization and classification of human object interactions. Existing HOI transformers either adopt a single decoder for triplet prediction, or utilize two parallel decoders to detect individual objects and interactions separately, and compose triplets by a matching process. In contrast, we decouple the triplet prediction into human-object pair detection and interaction classification. Our main motivation is that detecting the human-object instances and classifying interactions accurately needs to learn representations that focus on different regions. To this end, we present Disentangled Transformer, where both encoder and decoder are disentangled to facilitate learning of two sub-tasks. To associate the predictions of disentangled decoders, we first generate a unified representation for HOI triplets with a base decoder, and then utilize it as input feature of each disentangled decoder. Extensive experiments show that our method outperforms prior work on two public HOI benchmarks by a sizeable margin. Code will be available.
GitNet: Geometric Prior-based Transformation for Birds-Eye-View Segmentation
Apr 16, 2022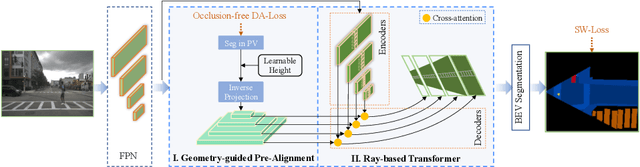
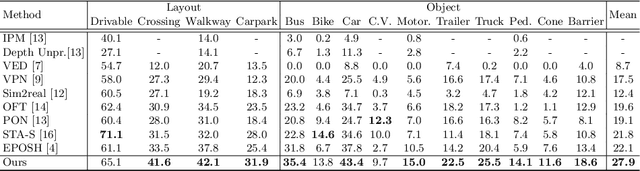
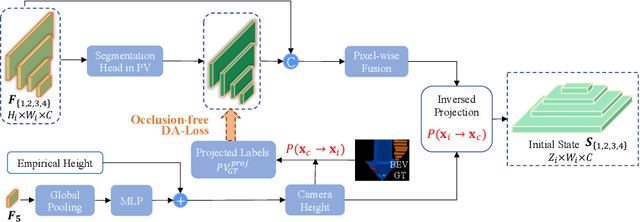
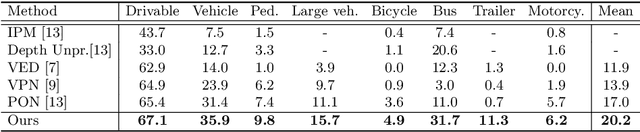
Birds-eye-view (BEV) semantic segmentation is critical for autonomous driving for its powerful spatial representation ability. It is challenging to estimate the BEV semantic maps from monocular images due to the spatial gap, since it is implicitly required to realize both the perspective-to-BEV transformation and segmentation. We present a novel two-stage Geometry Prior-based Transformation framework named GitNet, consisting of (i) the geometry-guided pre-alignment and (ii) ray-based transformer. In the first stage, we decouple the BEV segmentation into the perspective image segmentation and geometric prior-based mapping, with explicit supervision by projecting the BEV semantic labels onto the image plane to learn visibility-aware features and learnable geometry to translate into BEV space. Second, the pre-aligned coarse BEV features are further deformed by ray-based transformers to take visibility knowledge into account. GitNet achieves the leading performance on the challenging nuScenes and Argoverse Datasets. The code will be publicly available.
Implicit Sample Extension for Unsupervised Person Re-Identification
Apr 14, 2022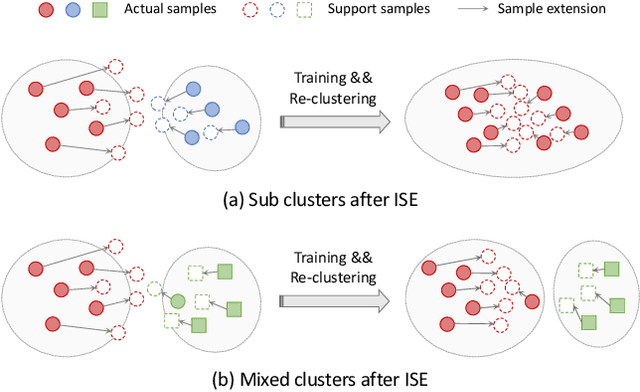
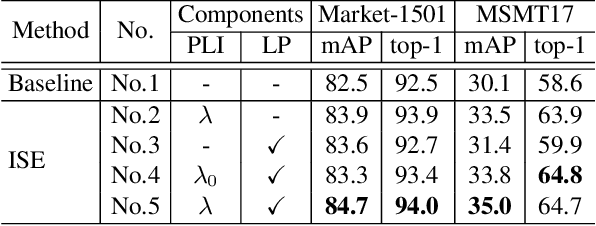
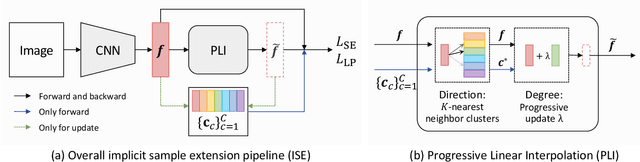
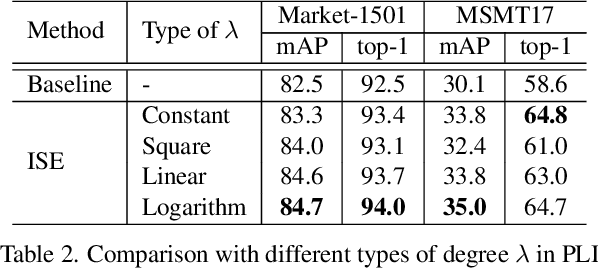
Most existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo labels for model training. Unfortunately, clustering sometimes mixes different true identities together or splits the same identity into two or more sub clusters. Training on these noisy clusters substantially hampers the Re-ID accuracy. Due to the limited samples in each identity, we suppose there may lack some underlying information to well reveal the accurate clusters. To discover these information, we propose an Implicit Sample Extension (\OurWholeMethod) method to generate what we call support samples around the cluster boundaries. Specifically, we generate support samples from actual samples and their neighbouring clusters in the embedding space through a progressive linear interpolation (PLI) strategy. PLI controls the generation with two critical factors, i.e., 1) the direction from the actual sample towards its K-nearest clusters and 2) the degree for mixing up the context information from the K-nearest clusters. Meanwhile, given the support samples, ISE further uses a label-preserving loss to pull them towards their corresponding actual samples, so as to compact each cluster. Consequently, ISE reduces the "sub and mixed" clustering errors, thus improving the Re-ID performance. Extensive experiments demonstrate that the proposed method is effective and achieves state-of-the-art performance for unsupervised person Re-ID. Code is available at: \url{https://github.com/PaddlePaddle/PaddleClas}.
MixFormer: Mixing Features across Windows and Dimensions
Apr 12, 2022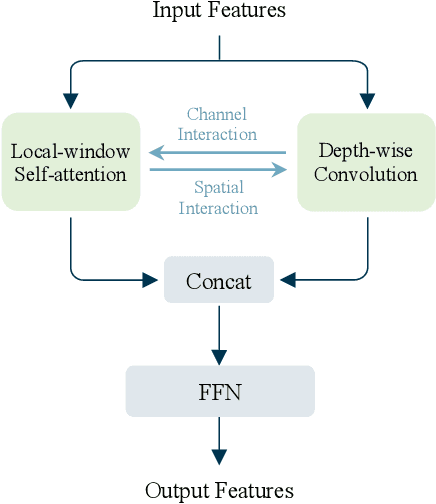

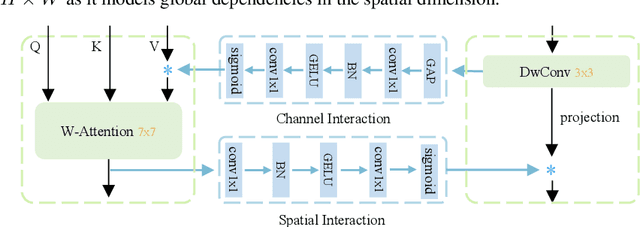

While local-window self-attention performs notably in vision tasks, it suffers from limited receptive field and weak modeling capability issues. This is mainly because it performs self-attention within non-overlapped windows and shares weights on the channel dimension. We propose MixFormer to find a solution. First, we combine local-window self-attention with depth-wise convolution in a parallel design, modeling cross-window connections to enlarge the receptive fields. Second, we propose bi-directional interactions across branches to provide complementary clues in the channel and spatial dimensions. These two designs are integrated to achieve efficient feature mixing among windows and dimensions. Our MixFormer provides competitive results on image classification with EfficientNet and shows better results than RegNet and Swin Transformer. Performance in downstream tasks outperforms its alternatives by significant margins with less computational costs in 5 dense prediction tasks on MS COCO, ADE20k, and LVIS. Code is available at \url{https://github.com/PaddlePaddle/PaddleClas}.
ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Mar 31, 2022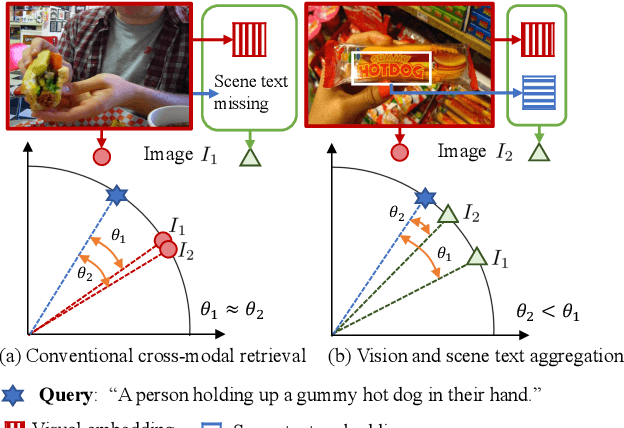

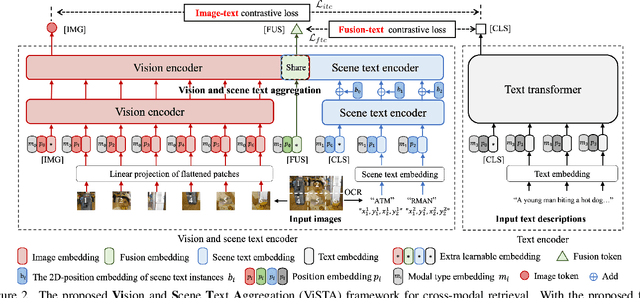

Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics. Most of existing cross-modal retrieval approaches ignore the usage of scene text information and directly adding this information may lead to performance degradation in scene text free scenarios. To address this issue, we propose a full transformer architecture to unify these cross-modal retrieval scenarios in a single $\textbf{Vi}$sion and $\textbf{S}$cene $\textbf{T}$ext $\textbf{A}$ggregation framework (ViSTA). Specifically, ViSTA utilizes transformer blocks to directly encode image patches and fuse scene text embedding to learn an aggregated visual representation for cross-modal retrieval. To tackle the modality missing problem of scene text, we propose a novel fusion token based transformer aggregation approach to exchange the necessary scene text information only through the fusion token and concentrate on the most important features in each modality. To further strengthen the visual modality, we develop dual contrastive learning losses to embed both image-text pairs and fusion-text pairs into a common cross-modal space. Compared to existing methods, ViSTA enables to aggregate relevant scene text semantics with visual appearance, and hence improve results under both scene text free and scene text aware scenarios. Experimental results show that ViSTA outperforms other methods by at least $\bf{8.4}\%$ at Recall@1 for scene text aware retrieval task. Compared with state-of-the-art scene text free retrieval methods, ViSTA can achieve better accuracy on Flicker30K and MSCOCO while running at least three times faster during the inference stage, which validates the effectiveness of the proposed framework.
Rope3D: TheRoadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task
Mar 25, 2022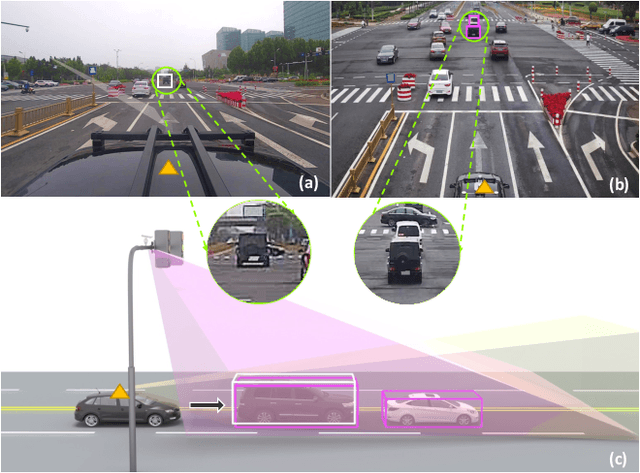
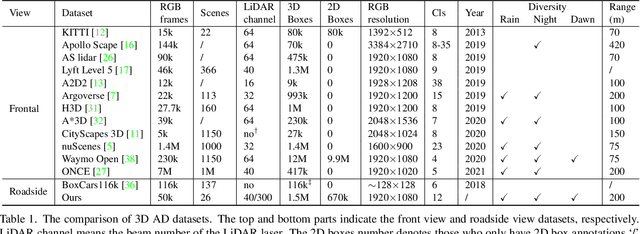

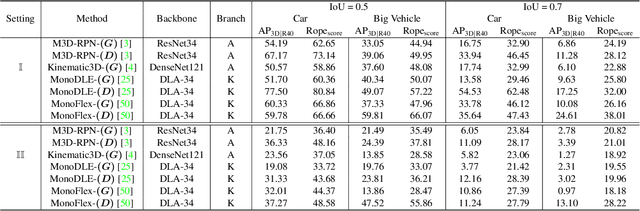
Concurrent perception datasets for autonomous driving are mainly limited to frontal view with sensors mounted on the vehicle. None of them is designed for the overlooked roadside perception tasks. On the other hand, the data captured from roadside cameras have strengths over frontal-view data, which is believed to facilitate a safer and more intelligent autonomous driving system. To accelerate the progress of roadside perception, we present the first high-diversity challenging Roadside Perception 3D dataset- Rope3D from a novel view. The dataset consists of 50k images and over 1.5M 3D objects in various scenes, which are captured under different settings including various cameras with ambiguous mounting positions, camera specifications, viewpoints, and different environmental conditions. We conduct strict 2D-3D joint annotation and comprehensive data analysis, as well as set up a new 3D roadside perception benchmark with metrics and evaluation devkit. Furthermore, we tailor the existing frontal-view monocular 3D object detection approaches and propose to leverage the geometry constraint to solve the inherent ambiguities caused by various sensors, viewpoints. Our dataset is available on https://thudair.baai.ac.cn/rope.
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
Mar 08, 2022
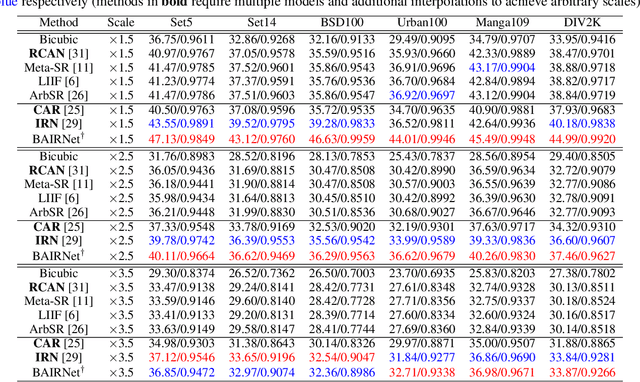
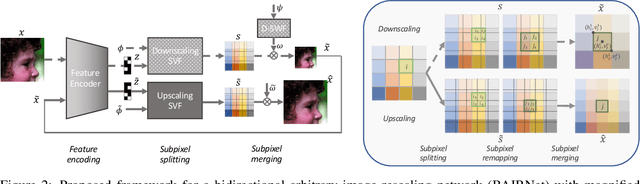

Deep learning based single image super-resolution models have been widely studied and superb results are achieved in upscaling low-resolution images with fixed scale factor and downscaling degradation kernel. To improve real world applicability of such models, there are growing interests to develop models optimized for arbitrary upscaling factors. Our proposed method is the first to treat arbitrary rescaling, both upscaling and downscaling, as one unified process. Using joint optimization of both directions, the proposed model is able to learn upscaling and downscaling simultaneously and achieve bidirectional arbitrary image rescaling. It improves the performance of current arbitrary upscaling models by a large margin while at the same time learns to maintain visual perception quality in downscaled images. The proposed model is further shown to be robust in cycle idempotence test, free of severe degradations in reconstruction accuracy when the downscaling-to-upscaling cycle is applied repetitively. This robustness is beneficial for image rescaling in the wild when this cycle could be applied to one image for multiple times. It also performs well on tests with arbitrary large scales and asymmetric scales, even when the model is not trained with such tasks. Extensive experiments are conducted to demonstrate the superior performance of our model.