 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Video-Text Retrieval with Explicit High-Level Semantics
Aug 09, 2022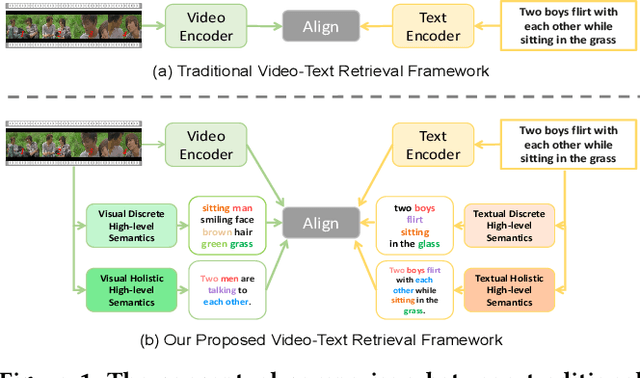
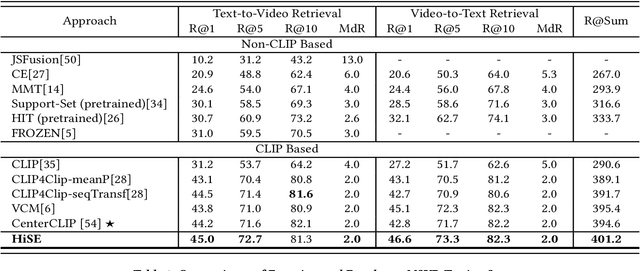
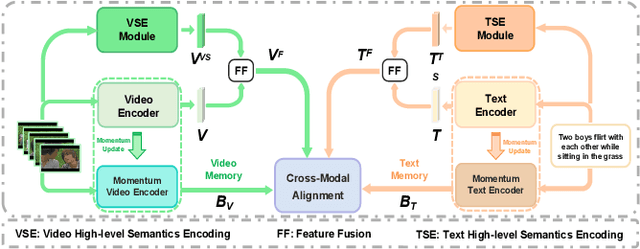
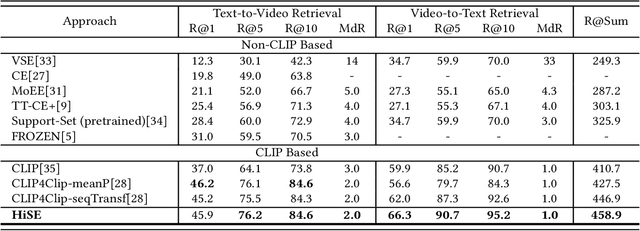
Video-text retrieval (VTR) is an attractive yet challenging task for multi-modal understanding, which aims to search for relevant video (text) given a query (video). Existing methods typically employ completely heterogeneous visual-textual information to align video and text, whilst lacking the awareness of homogeneous high-level semantic information residing in both modalities. To fill this gap, in this work, we propose a novel visual-linguistic aligning model named HiSE for VTR, which improves the cross-modal representation by incorporating explicit high-level semantics. First, we explore the hierarchical property of explicit high-level semantics, and further decompose it into two levels, i.e. discrete semantics and holistic semantics. Specifically, for visual branch, we exploit an off-the-shelf semantic entity predictor to generate discrete high-level semantics. In parallel, a trained video captioning model is employed to output holistic high-level semantics. As for the textual modality, we parse the text into three parts including occurrence, action and entity. In particular, the occurrence corresponds to the holistic high-level semantics, meanwhile both action and entity represent the discrete ones. Then, different graph reasoning techniques are utilized to promote the interaction between holistic and discrete high-level semantics. Extensive experiments demonstrate that, with the aid of explicit high-level semantics, our method achieves the superior performance over state-of-the-art methods on three benchmark datasets, including MSR-VTT, MSVD and DiDeMo.
Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Aug 02, 2022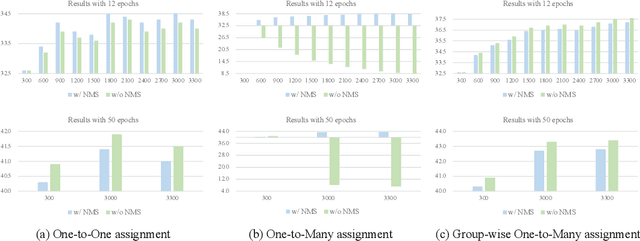
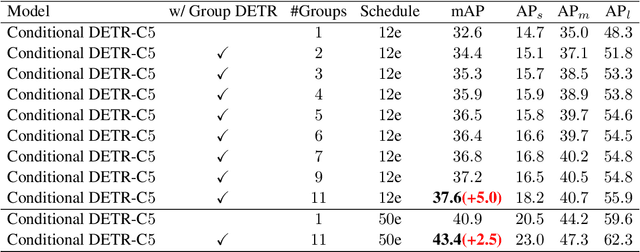
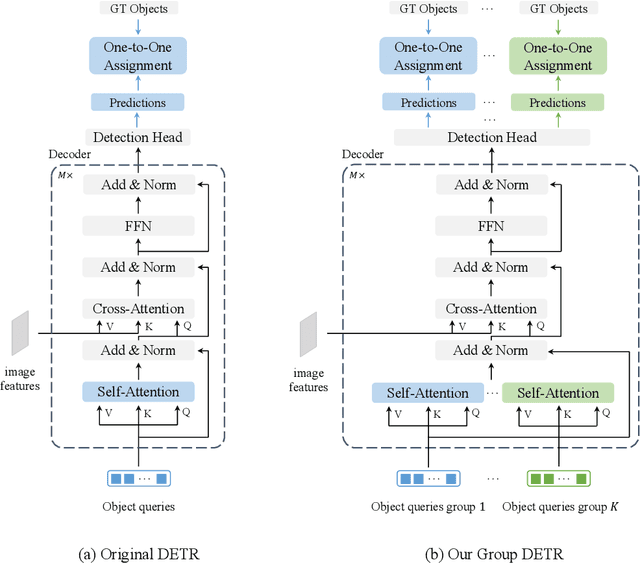
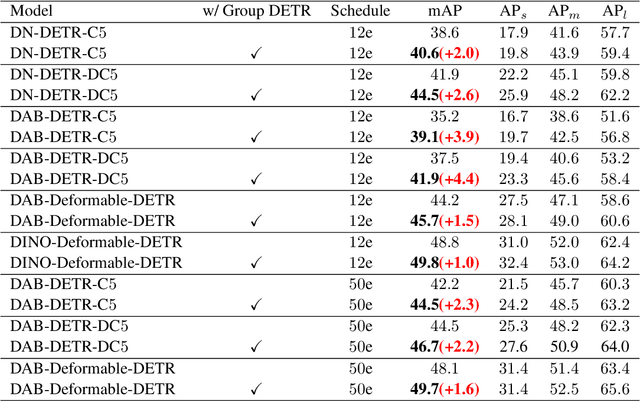
Detection Transformer (DETR) relies on One-to-One assignment, i.e., assigning one ground-truth object to only one positive object query, for end-to-end object detection and lacks the capability of exploiting multiple positive object queries. We present a novel DETR training approach, named {\em Group DETR}, to support Group-wise One-to-Many assignment. We make simple modifications during training: (i) adopt $K$ groups of object queries; (ii) conduct decoder self-attention on each group of object queries with the same parameters; (iii) perform One-to-One label assignment for each group, leading to $K$ positive object queries for each ground-truth object. In inference, we only use one group of object queries, making no modifications to DETR architecture and processes. We validate the effectiveness of the proposed approach on DETR variants, including Conditional DETR, DAB-DETR, DN-DETR, and DINO. Code will be available.
Detecting Deepfake by Creating Spatio-Temporal Regularity Disruption
Jul 21, 2022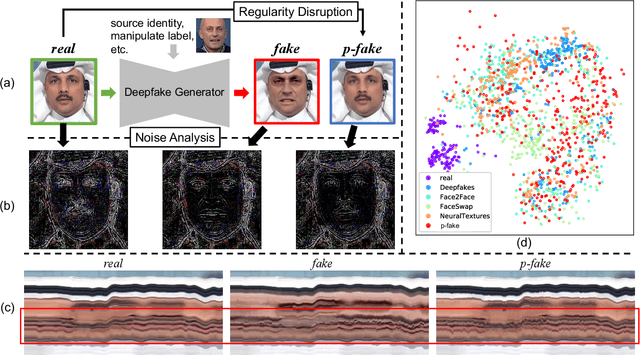
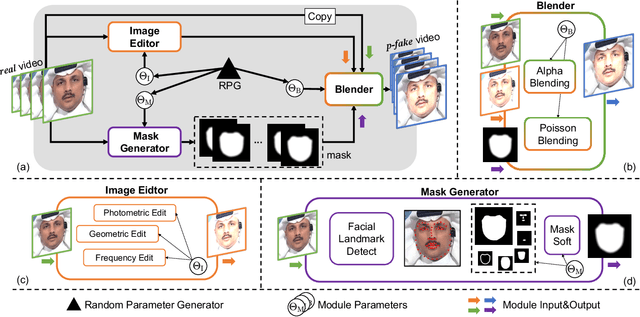
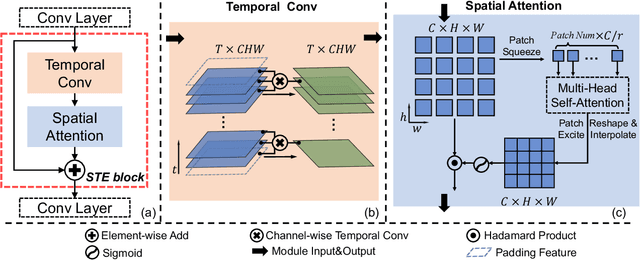
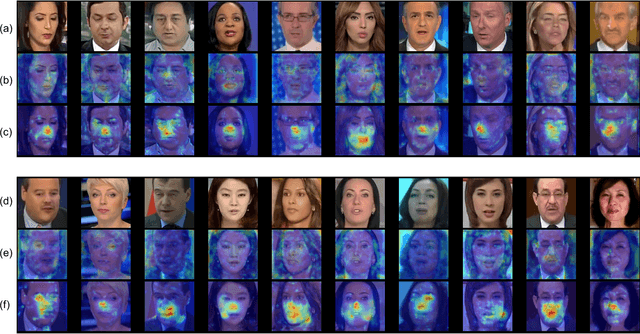
Despite encouraging progress in deepfake detection, generalization to unseen forgery types remains a significant challenge due to the limited forgery clues explored during training. In contrast, we notice a common phenomenon in deepfake: fake video creation inevitably disrupts the statistical regularity in original videos. Inspired by this observation, we propose to boost the generalization of deepfake detection by distinguishing the "regularity disruption" that does not appear in real videos. Specifically, by carefully examining the spatial and temporal properties, we propose to disrupt a real video through a Pseudo-fake Generator and create a wide range of pseudo-fake videos for training. Such practice allows us to achieve deepfake detection without using fake videos and improves the generalization ability in a simple and efficient manner. To jointly capture the spatial and temporal disruptions, we propose a Spatio-Temporal Enhancement block to learn the regularity disruption across space and time on our self-created videos. Through comprehensive experiments, our method exhibits excellent performance on several datasets.
UFO: Unified Feature Optimization
Jul 21, 2022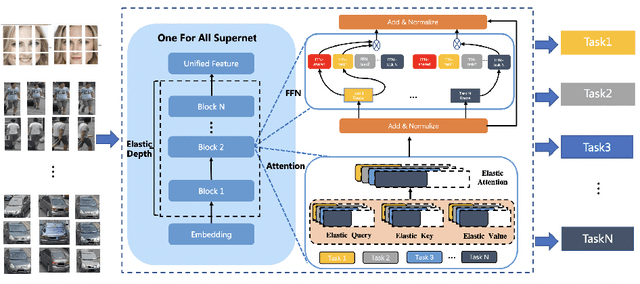
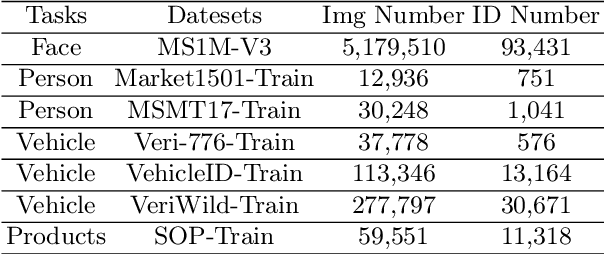
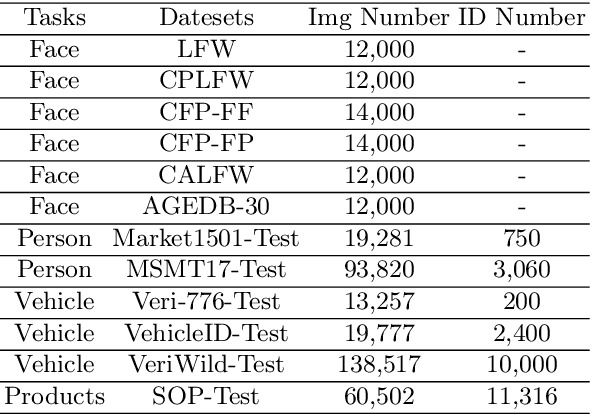
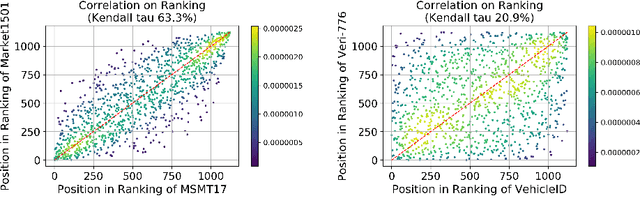
This paper proposes a novel Unified Feature Optimization (UFO) paradigm for training and deploying deep models under real-world and large-scale scenarios, which requires a collection of multiple AI functions. UFO aims to benefit each single task with a large-scale pretraining on all tasks. Compared with the well known foundation model, UFO has two different points of emphasis, i.e., relatively smaller model size and NO adaptation cost: 1) UFO squeezes a wide range of tasks into a moderate-sized unified model in a multi-task learning manner and further trims the model size when transferred to down-stream tasks. 2) UFO does not emphasize transfer to novel tasks. Instead, it aims to make the trimmed model dedicated for one or more already-seen task. With these two characteristics, UFO provides great convenience for flexible deployment, while maintaining the benefits of large-scale pretraining. A key merit of UFO is that the trimming process not only reduces the model size and inference consumption, but also even improves the accuracy on certain tasks. Specifically, UFO considers the multi-task training and brings two-fold impact on the unified model: some closely related tasks have mutual benefits, while some tasks have conflicts against each other. UFO manages to reduce the conflicts and to preserve the mutual benefits through a novel Network Architecture Search (NAS) method. Experiments on a wide range of deep representation learning tasks (i.e., face recognition, person re-identification, vehicle re-identification and product retrieval) show that the model trimmed from UFO achieves higher accuracy than its single-task-trained counterpart and yet has smaller model size, validating the concept of UFO. Besides, UFO also supported the release of 17 billion parameters computer vision (CV) foundation model which is the largest CV model in the industry.
Action Quality Assessment with Temporal Parsing Transformer
Jul 19, 2022
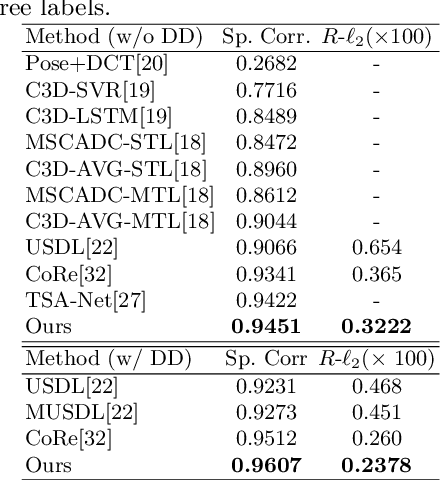
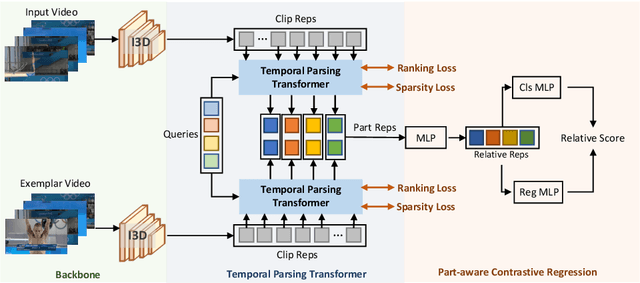
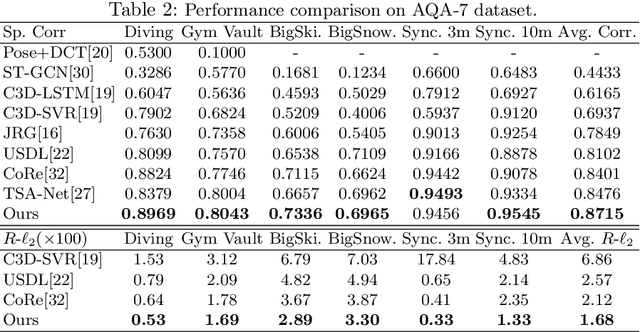
Action Quality Assessment(AQA) is important for action understanding and resolving the task poses unique challenges due to subtle visual differences. Existing state-of-the-art methods typically rely on the holistic video representations for score regression or ranking, which limits the generalization to capture fine-grained intra-class variation. To overcome the above limitation, we propose a temporal parsing transformer to decompose the holistic feature into temporal part-level representations. Specifically, we utilize a set of learnable queries to represent the atomic temporal patterns for a specific action. Our decoding process converts the frame representations to a fixed number of temporally ordered part representations. To obtain the quality score, we adopt the state-of-the-art contrastive regression based on the part representations. Since existing AQA datasets do not provide temporal part-level labels or partitions, we propose two novel loss functions on the cross attention responses of the decoder: a ranking loss to ensure the learnable queries to satisfy the temporal order in cross attention and a sparsity loss to encourage the part representations to be more discriminative. Extensive experiments show that our proposed method outperforms prior work on three public AQA benchmarks by a considerable margin.
Neural Color Operators for Sequential Image Retouching
Jul 17, 2022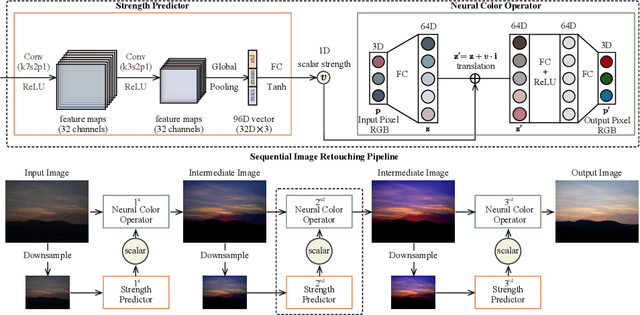
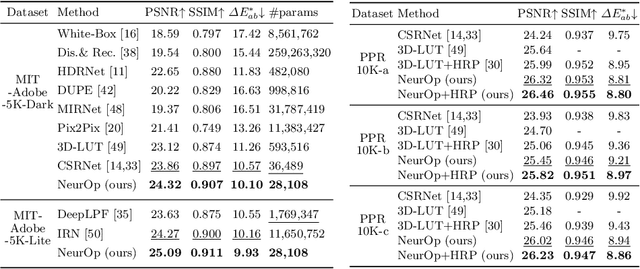


We propose a novel image retouching method by modeling the retouching process as performing a sequence of newly introduced trainable neural color operators. The neural color operator mimics the behavior of traditional color operators and learns pixelwise color transformation while its strength is controlled by a scalar. To reflect the homomorphism property of color operators, we employ equivariant mapping and adopt an encoder-decoder structure which maps the non-linear color transformation to a much simpler transformation (i.e., translation) in a high dimensional space. The scalar strength of each neural color operator is predicted using CNN based strength predictors by analyzing global image statistics. Overall, our method is rather lightweight and offers flexible controls. Experiments and user studies on public datasets show that our method consistently achieves the best results compared with SOTA methods in both quantitative measures and visual qualities. The code and data will be made publicly available.
Paint and Distill: Boosting 3D Object Detection with Semantic Passing Network
Jul 12, 2022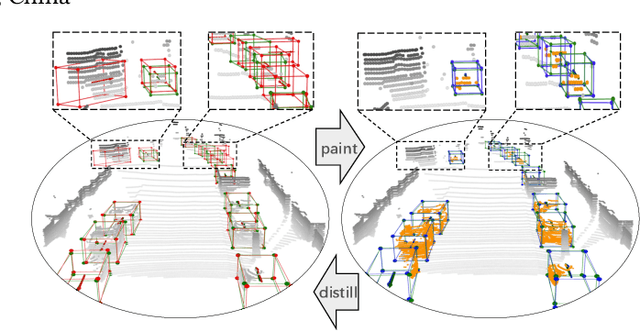
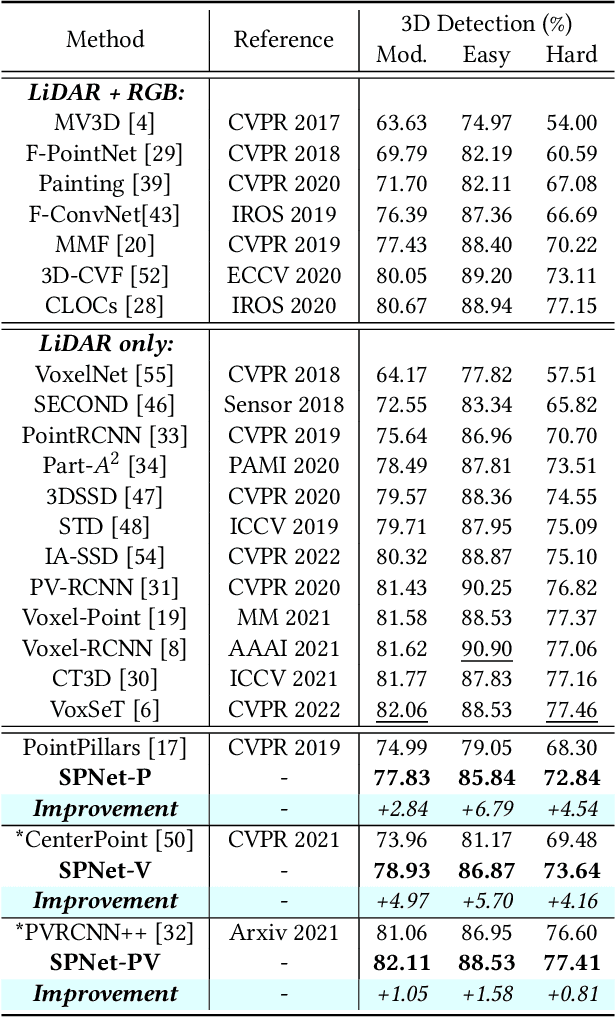
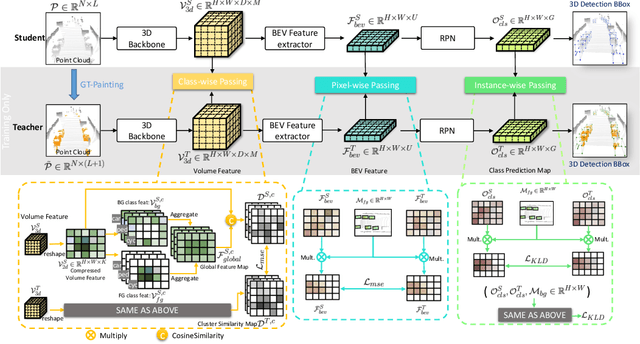
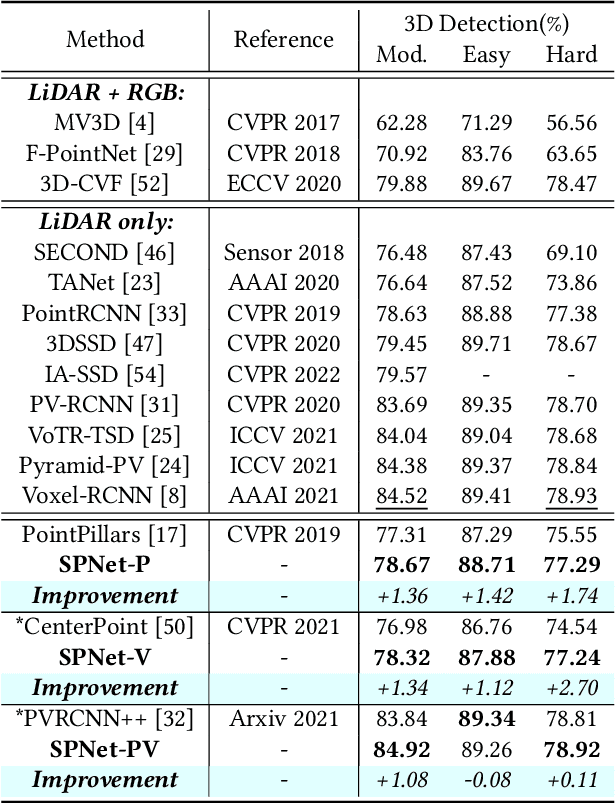
3D object detection task from lidar or camera sensors is essential for autonomous driving. Pioneer attempts at multi-modality fusion complement the sparse lidar point clouds with rich semantic texture information from images at the cost of extra network designs and overhead. In this work, we propose a novel semantic passing framework, named SPNet, to boost the performance of existing lidar-based 3D detection models with the guidance of rich context painting, with no extra computation cost during inference. Our key design is to first exploit the potential instructive semantic knowledge within the ground-truth labels by training a semantic-painted teacher model and then guide the pure-lidar network to learn the semantic-painted representation via knowledge passing modules at different granularities: class-wise passing, pixel-wise passing and instance-wise passing. Experimental results show that the proposed SPNet can seamlessly cooperate with most existing 3D detection frameworks with 1~5% AP gain and even achieve new state-of-the-art 3D detection performance on the KITTI test benchmark. Code is available at: https://github.com/jb892/SPNet.
Delving into Sequential Patches for Deepfake Detection
Jul 06, 2022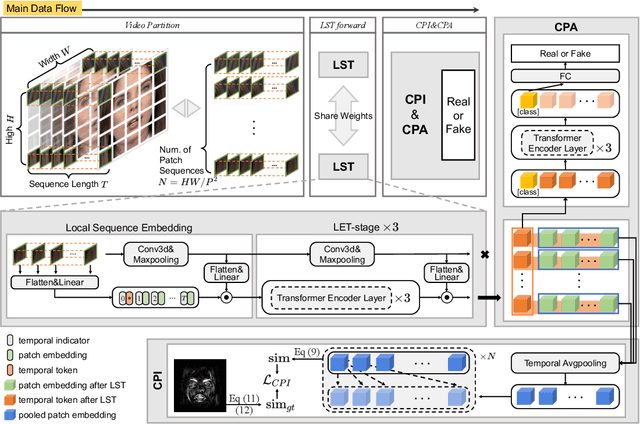
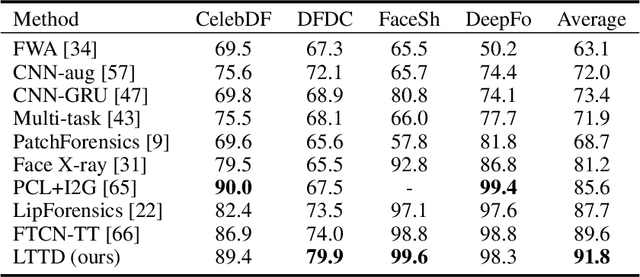
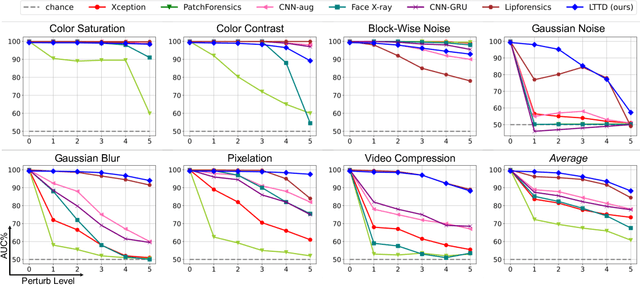

Recent advances in face forgery techniques produce nearly visually untraceable deepfake videos, which could be leveraged with malicious intentions. As a result, researchers have been devoted to deepfake detection. Previous studies has identified the importance of local low-level cues and temporal information in pursuit to generalize well across deepfake methods, however, they still suffer from robustness problem against post-processings. In this work, we propose the Local- & Temporal-aware Transformer-based Deepfake Detection (LTTD) framework, which adopts a local-to-global learning protocol with a particular focus on the valuable temporal information within local sequences. Specifically, we propose a Local Sequence Transformer (LST), which models the temporal consistency on sequences of restricted spatial regions, where low-level information is hierarchically enhanced with shallow layers of learned 3D filters. Based on the local temporal embeddings, we then achieve the final classification in a global contrastive way. Extensive experiments on popular datasets validate that our approach effectively spots local forgery cues and achieves state-of-the-art performance.
Neural Deformable Voxel Grid for Fast Optimization of Dynamic View Synthesis
Jun 15, 2022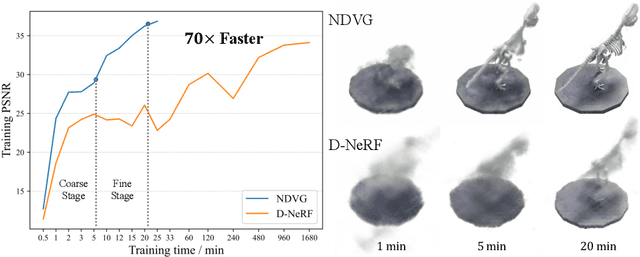
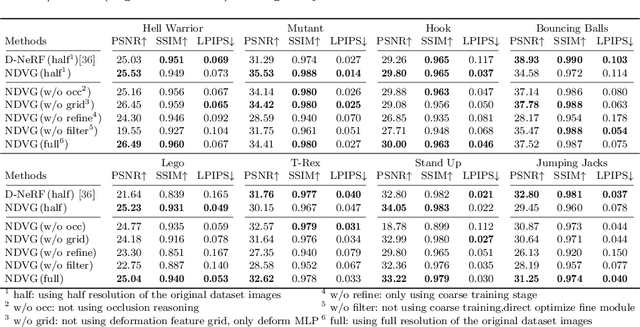
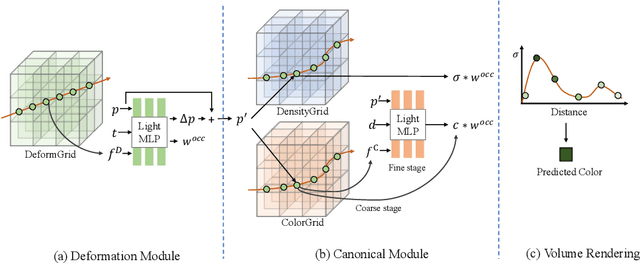

Recently, Neural Radiance Fields (NeRF) is revolutionizing the task of novel view synthesis (NVS) for its superior performance. However, NeRF and its variants generally require a lengthy per-scene training procedure, where a multi-layer perceptron (MLP) is fitted to the captured images. To remedy the challenge, the voxel-grid representation has been proposed to significantly speed up the training. However, these existing methods can only deal with static scenes. How to develop an efficient and accurate dynamic view synthesis method remains an open problem. Extending the methods for static scenes to dynamic scenes is not straightforward as both the scene geometry and appearance change over time. In this paper, built on top of the recent advances in voxel-grid optimization, we propose a fast deformable radiance field method to handle dynamic scenes. Our method consists of two modules. The first module adopts a deformation grid to store 3D dynamic features, and a light-weight MLP for decoding the deformation that maps a 3D point in observation space to the canonical space using the interpolated features. The second module contains a density and a color grid to model the geometry and density of the scene. The occlusion is explicitly modeled to further improve the rendering quality. Experimental results show that our method achieves comparable performance to D-NeRF using only 20 minutes for training, which is more than 70x faster than D-NeRF, clearly demonstrating the efficiency of our proposed method.
Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning
Jun 13, 2022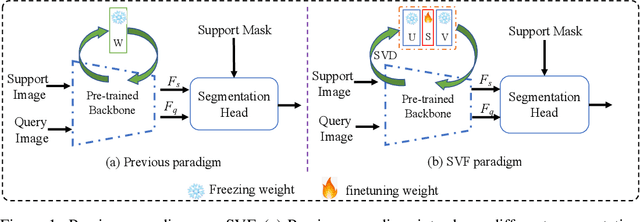
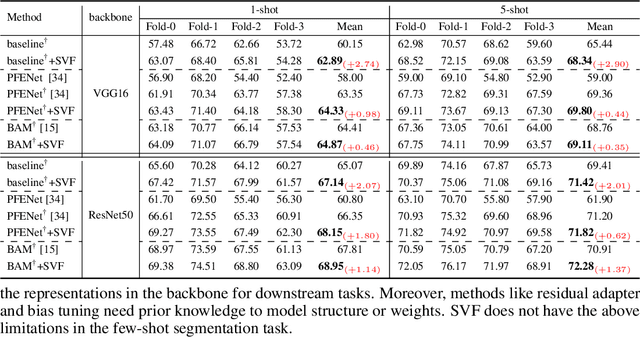
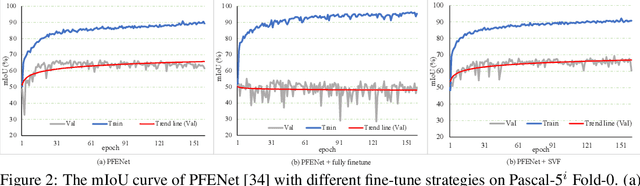
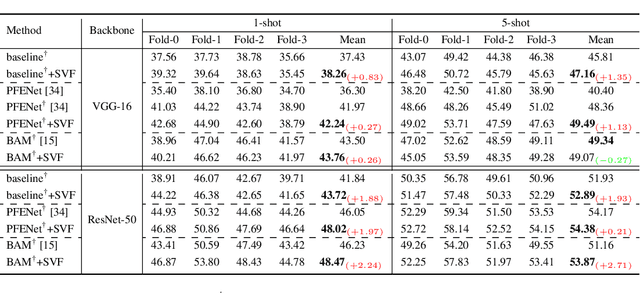
Freezing the pre-trained backbone has become a standard paradigm to avoid overfitting in few-shot segmentation. In this paper, we rethink the paradigm and explore a new regime: {\em fine-tuning a small part of parameters in the backbone}. We present a solution to overcome the overfitting problem, leading to better model generalization on learning novel classes. Our method decomposes backbone parameters into three successive matrices via the Singular Value Decomposition (SVD), then {\em only fine-tunes the singular values} and keeps others frozen. The above design allows the model to adjust feature representations on novel classes while maintaining semantic clues within the pre-trained backbone. We evaluate our {\em Singular Value Fine-tuning (SVF)} approach on various few-shot segmentation methods with different backbones. We achieve state-of-the-art results on both Pascal-5$^i$ and COCO-20$^i$ across 1-shot and 5-shot settings. Hopefully, this simple baseline will encourage researchers to rethink the role of backbone fine-tuning in few-shot settings. The source code and models will be available at \url{https://github.com/syp2ysy/SVF}.