 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2StyleGS: Multi-Modality 3D Style Transfer with Gaussian Splatting
Apr 04, 2026Conventional 3D style transfer methods rely on a fixed reference image to apply artistic patterns to 3D scenes. However, in practical applications such as virtual or augmented reality, users often prefer more flexible inputs, including textual descriptions and diverse imagery. In this work, we introduce a novel real-time styling technique M2StyleGS to generate a sequence of precisely color-mapped views. It utilizes 3D Gaussian Splatting (3DGS) as a 3D presentation and multi-modality knowledge refined by CLIP as a reference style. M2StyleGS resolves the abnormal transformation issue by employing a precise feature alignment, namely subdivisive flow, it strengthens the projection of the mapped CLIP text-visual combination feature to the VGG style feature. In addition, we introduce observation loss, which assists in the stylized scene better matching the reference style during the generation, and suppression loss, which suppresses the offset of reference color information throughout the decoding process. By integrating these approaches, M2StyleGS can employ text or images as references to generate a set of style-enhanced novel views. Our experiments show that M2StyleGS achieves better visual quality and surpasses the previous work by up to 32.92% in terms of consistency.
Beyond Hungarian: Match-Free Supervision for End-to-End Object Detection
Mar 09, 2026Recent DEtection TRansformer (DETR) based frameworks have achieved remarkable success in end-to-end object detection. However, the reliance on the Hungarian algorithm for bipartite matching between queries and ground truths introduces computational overhead and complicates the training dynamics. In this paper, we propose a novel matching-free training scheme for DETR-based detectors that eliminates the need for explicit heuristic matching. At the core of our approach is a dedicated Cross-Attention-based Query Selection (CAQS) module. Instead of discrete assignment, we utilize encoded ground-truth information to probe the decoder queries through a cross-attention mechanism. By minimizing the weighted error between the queried results and the ground truths, the model autonomously learns the implicit correspondences between object queries and specific targets. This learned relationship further provides supervision signals for the learning of queries. Experimental results demonstrate that our proposed method bypasses the traditional matching process, significantly enhancing training efficiency, reducing the matching latency by over 50\%, effectively eliminating the discrete matching bottleneck through differentiable correspondence learning, and also achieving superior performance compared to existing state-of-the-art methods.
TrajVG: 3D Trajectory-Coupled Visual Geometry Learning
Feb 05, 2026Feed-forward multi-frame 3D reconstruction models often degrade on videos with object motion. Global-reference becomes ambiguous under multiple motions, while the local pointmap relies heavily on estimated relative poses and can drift, causing cross-frame misalignment and duplicated structures. We propose TrajVG, a reconstruction framework that makes cross-frame 3D correspondence an explicit prediction by estimating camera-coordinate 3D trajectories. We couple sparse trajectories, per-frame local point maps, and relative camera poses with geometric consistency objectives: (i) bidirectional trajectory-pointmap consistency with controlled gradient flow, and (ii) a pose consistency objective driven by static track anchors that suppresses gradients from dynamic regions. To scale training to in-the-wild videos where 3D trajectory labels are scarce, we reformulate the same coupling constraints into self-supervised objectives using only pseudo 2D tracks, enabling unified training with mixed supervision. Extensive experiments across 3D tracking, pose estimation, pointmap reconstruction, and video depth show that TrajVG surpasses the current feedforward performance baseline.
From Frames to Sequences: Temporally Consistent Human-Centric Dense Prediction
Feb 03, 2026In this work, we focus on the challenge of temporally consistent human-centric dense prediction across video sequences. Existing models achieve strong per-frame accuracy but often flicker under motion, occlusion, and lighting changes, and they rarely have paired human video supervision for multiple dense tasks. We address this gap with a scalable synthetic data pipeline that generates photorealistic human frames and motion-aligned sequences with pixel-accurate depth, normals, and masks. Unlike prior static data synthetic pipelines, our pipeline provides both frame-level labels for spatial learning and sequence-level supervision for temporal learning. Building on this, we train a unified ViT-based dense predictor that (i) injects an explicit human geometric prior via CSE embeddings and (ii) improves geometry-feature reliability with a lightweight channel reweighting module after feature fusion. Our two-stage training strategy, combining static pretraining with dynamic sequence supervision, enables the model first to acquire robust spatial representations and then refine temporal consistency across motion-aligned sequences. Extensive experiments show that we achieve state-of-the-art performance on THuman2.1 and Hi4D and generalize effectively to in-the-wild videos.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025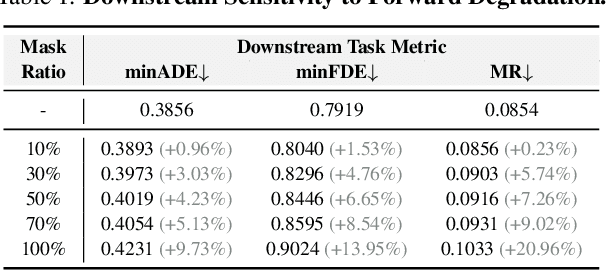
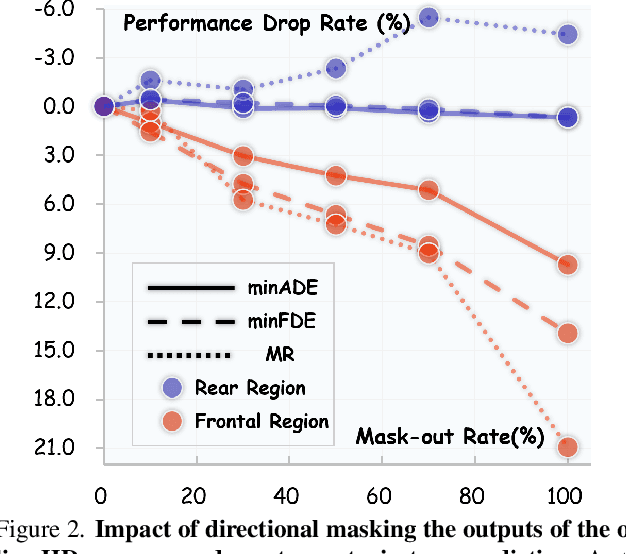
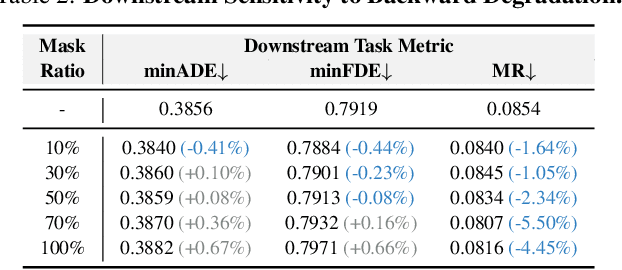
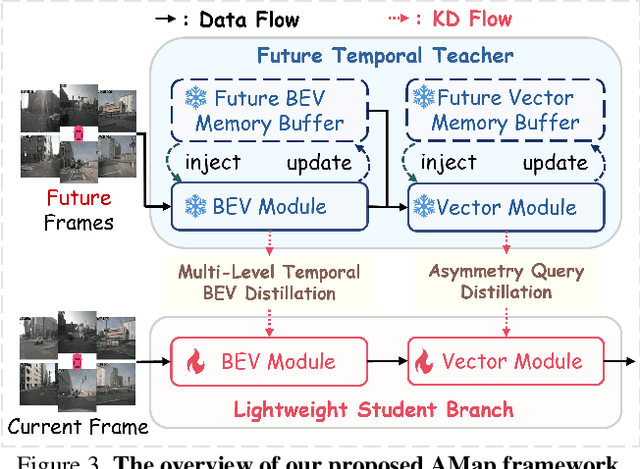
Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
vMFCoOp: Towards Equilibrium on a Unified Hyperspherical Manifold for Prompting Biomedical VLMs
Nov 13, 2025Recent advances in context optimization (CoOp) guided by large language model (LLM)-distilled medical semantic priors offer a scalable alternative to manual prompt engineering and full fine-tuning for adapting biomedical CLIP-based vision-language models (VLMs). However, prompt learning in this context is challenged by semantic misalignment between LLMs and CLIP variants due to divergent training corpora and model architectures; it further lacks scalability across continuously evolving families of foundation models. More critically, pairwise multimodal alignment via conventional Euclidean-space optimization lacks the capacity to model unified representations or apply localized geometric constraints, which tends to amplify modality gaps in complex biomedical imaging and destabilize few-shot adaptation. In this work, we propose vMFCoOp, a framework that inversely estimates von Mises-Fisher (vMF) distributions on a shared Hyperspherical Manifold, aligning semantic biases between arbitrary LLMs and CLIP backbones via Unified Semantic Anchors to achieve robust biomedical prompting and superior few-shot classification. Grounded in three complementary constraints, vMFCoOp demonstrates consistent improvements across 14 medical datasets, 12 medical imaging modalities, and 13 anatomical regions, outperforming state-of-the-art methods in accuracy, generalization, and clinical applicability. This work aims to continuously expand to encompass more downstream applications, and the corresponding resources are intended to be shared through https://github.com/VinyehShaw/UniEqui.
Learning Global Representation from Queries for Vectorized HD Map Construction
Oct 08, 2025The online construction of vectorized high-definition (HD) maps is a cornerstone of modern autonomous driving systems. State-of-the-art approaches, particularly those based on the DETR framework, formulate this as an instance detection problem. However, their reliance on independent, learnable object queries results in a predominantly local query perspective, neglecting the inherent global representation within HD maps. In this work, we propose \textbf{MapGR} (\textbf{G}lobal \textbf{R}epresentation learning for HD \textbf{Map} construction), an architecture designed to learn and utilize a global representations from queries. Our method introduces two synergistic modules: a Global Representation Learning (GRL) module, which encourages the distribution of all queries to better align with the global map through a carefully designed holistic segmentation task, and a Global Representation Guidance (GRG) module, which endows each individual query with explicit, global-level contextual information to facilitate its optimization. Evaluations on the nuScenes and Argoverse2 datasets validate the efficacy of our approach, demonstrating substantial improvements in mean Average Precision (mAP) compared to leading baselines.
Rethinking Brain Tumor Segmentation from the Frequency Domain Perspective
Jun 11, 2025Precise segmentation of brain tumors, particularly contrast-enhancing regions visible in post-contrast MRI (areas highlighted by contrast agent injection), is crucial for accurate clinical diagnosis and treatment planning but remains challenging. However, current methods exhibit notable performance degradation in segmenting these enhancing brain tumor areas, largely due to insufficient consideration of MRI-specific tumor features such as complex textures and directional variations. To address this, we propose the Harmonized Frequency Fusion Network (HFF-Net), which rethinks brain tumor segmentation from a frequency-domain perspective. To comprehensively characterize tumor regions, we develop a Frequency Domain Decomposition (FDD) module that separates MRI images into low-frequency components, capturing smooth tumor contours and high-frequency components, highlighting detailed textures and directional edges. To further enhance sensitivity to tumor boundaries, we introduce an Adaptive Laplacian Convolution (ALC) module that adaptively emphasizes critical high-frequency details using dynamically updated convolution kernels. To effectively fuse tumor features across multiple scales, we design a Frequency Domain Cross-Attention (FDCA) integrating semantic, positional, and slice-specific information. We further validate and interpret frequency-domain improvements through visualization, theoretical reasoning, and experimental analyses. Extensive experiments on four public datasets demonstrate that HFF-Net achieves an average relative improvement of 4.48\% (ranging from 2.39\% to 7.72\%) in the mean Dice scores across the three major subregions, and an average relative improvement of 7.33% (ranging from 5.96% to 8.64%) in the segmentation of contrast-enhancing tumor regions, while maintaining favorable computational efficiency and clinical applicability. Code: https://github.com/VinyehShaw/HFF.
Rethinking Score Distilling Sampling for 3D Editing and Generation
May 03, 2025Score Distillation Sampling (SDS) has emerged as a prominent method for text-to-3D generation by leveraging the strengths of 2D diffusion models. However, SDS is limited to generation tasks and lacks the capability to edit existing 3D assets. Conversely, variants of SDS that introduce editing capabilities often can not generate new 3D assets effectively. In this work, we observe that the processes of generation and editing within SDS and its variants have unified underlying gradient terms. Building on this insight, we propose Unified Distillation Sampling (UDS), a method that seamlessly integrates both the generation and editing of 3D assets. Essentially, UDS refines the gradient terms used in vanilla SDS methods, unifying them to support both tasks. Extensive experiments demonstrate that UDS not only outperforms baseline methods in generating 3D assets with richer details but also excels in editing tasks, thereby bridging the gap between 3D generation and editing. The code is available on: https://github.com/xingy038/UDS.
Laser: Efficient Language-Guided Segmentation in Neural Radiance Fields
Jan 31, 2025



In this work, we propose a method that leverages CLIP feature distillation, achieving efficient 3D segmentation through language guidance. Unlike previous methods that rely on multi-scale CLIP features and are limited by processing speed and storage requirements, our approach aims to streamline the workflow by directly and effectively distilling dense CLIP features, thereby achieving precise segmentation of 3D scenes using text. To achieve this, we introduce an adapter module and mitigate the noise issue in the dense CLIP feature distillation process through a self-cross-training strategy. Moreover, to enhance the accuracy of segmentation edges, this work presents a low-rank transient query attention mechanism. To ensure the consistency of segmentation for similar colors under different viewpoints, we convert the segmentation task into a classification task through label volume, which significantly improves the consistency of segmentation in color-similar areas. We also propose a simplified text augmentation strategy to alleviate the issue of ambiguity in the correspondence between CLIP features and text. Extensive experimental results show that our method surpasses current state-of-the-art technologies in both training speed and performance. Our code is available on: https://github.com/xingy038/Laser.git.