 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAROT: Task-Adaptive Refinement of LLM-prior Graphs for Few-shot Tabular Learning
Jun 10, 2026Few-shot tabular learning provides a cost-effective approach for real-world applications where annotation is costly and collecting sufficient samples for new tasks is difficult. Existing Traditional and LLM-based methods have demonstrated effectiveness in few-shot scenarios. However, traditional methods need additional training on unlabeled or generated data, which incur significant computational overhead. In addition, LLM-based methods that directly feed raw tabular data into LLMs raise privacy and compliance concerns. More importantly, both paradigms largely overlook the semantic relationships between features, which provide structural and semantic prior for constructing a semantic graph. Semantic graph is essential for modeling meaningful feature interactions in few-shot scenarios. In this paper, we propose TAROT, a GNN-based framework that encodes the structural and semantic prior by constructing and refining a task-adaptive semantic graph from this prior, thereby improving predictive performance in few-shot tabular learning. TAROT first encodes heterogeneous tabular data into unified node semantic representations via a Unified Semantic Tabular Node Encoder (USTNE). Then, it prompts LLMs to infer the semantic relationship between features based on the task description and feature names to construct a semantic graph. To mitigate structural noise introduced by the hallucination of LLMs, TAROT introduces Task-adaptive Semantic Graph Refinement that prunes spurious or task-unrelated edges and adds missing task-related ones, aligning the graph structure with the downstream objective. Finally, a GNN performs message passing over the refined graph to capture task-related semantic dependencies for prediction. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of TAROT, establishing it as a state-of-the-art approach in this domain.
SAIGuard: Communication-State Simulation for Proactive Defense of LLM Multi-Agent Systems
Jun 10, 2026LLM-based multi-agent systems (MAS) solve complex tasks through inter-agent collaboration, but their communication-driven nature also allows security risks to spread across agents and trigger system-wide failures. Existing MAS defenses mainly follow a reactive paradigm after execution by detecting and isolating harmful agents, which may cause irreversible damage and degrade collaborative utility. To address this, we propose a proactive defense framework for MAS security, namely a Simulation-aware Interception Guard (SAIGuard). SAIGuard performs communication-state simulation over the MAS interaction graph, estimates the impact of incoming messages on local agent states and the global MAS state, and detects risky messages via reconstruction deviations from benign communication patterns. Instead of isolating agents, SAIGuard sanitizes or regenerates suspicious messages before it propagation into system. Experiments across diverse topologies and attack scenarios show that SAIGuard reduces attack success rates while maintaining MAS utility, outperforming reactive defenses.
Detect by Yourself: Self-Designing Agentic Workflows for Few-Shot Graph Anomaly Detection
May 26, 2026Graph anomaly detection aims to identify anomaly nodes in attributed graphs and plays an important role in real-world applications. However, existing graph anomaly detection methods still face two key challenges: 1) fixed pipelines, which restrict their adaptability across different graph tasks under limited supervision; 2) weak evidence, which prevents them from explicitly incorporating contextual and structural anomaly signals into the detection process. In this paper, we propose a novel framework, self-designing agentic workflows for few-shot graph anomaly detection (SignGAD). Specifically, we propose a novel paradigm that reformulates graph anomaly detection task from training a fixed anomaly detector to designing task-conditioned detection workflows. By constructing detection workflows, SignGAD selects suitable graph encodings and detector designs to exploit task-specific anomaly evidence. Meanwhile, we introduce a guarded final refit strategy to refine the selected workflow by calibrating refit acceptance, enhancing reliability under limited supervision. Extensive experiments conducted on several real-world datasets demonstrate that SignGAD achieves strong performance against state-of-the-art methods, highlighting its effectiveness on graph anomaly detection tasks.
PRBench: End-to-end Paper Reproduction in Physics Research
Mar 29, 2026AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
HyperD: Hybrid Periodicity Decoupling Framework for Traffic Forecasting
Nov 16, 2025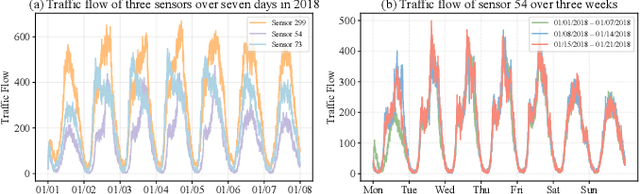
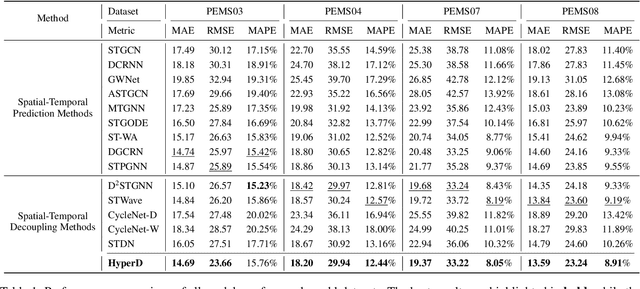
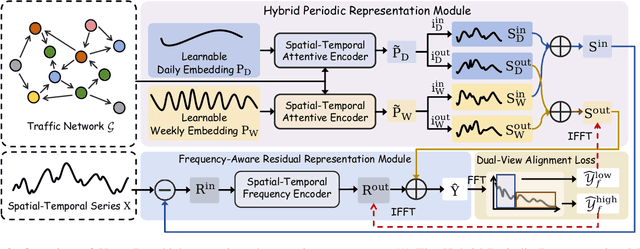
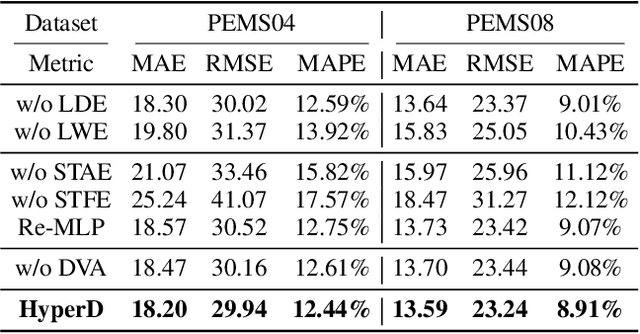
Accurate traffic forecasting plays a vital role in intelligent transportation systems, enabling applications such as congestion control, route planning, and urban mobility optimization. However, traffic forecasting remains challenging due to two key factors: (1) complex spatial dependencies arising from dynamic interactions between road segments and traffic sensors across the network, and (2) the coexistence of multi-scale periodic patterns (e.g., daily and weekly periodic patterns driven by human routines) with irregular fluctuations caused by unpredictable events (e.g., accidents, weather, or construction). To tackle these challenges, we propose HyperD (Hybrid Periodic Decoupling), a novel framework that decouples traffic data into periodic and residual components. The periodic component is handled by the Hybrid Periodic Representation Module, which extracts fine-grained daily and weekly patterns using learnable periodic embeddings and spatial-temporal attention. The residual component, which captures non-periodic, high-frequency fluctuations, is modeled by the Frequency-Aware Residual Representation Module, leveraging complex-valued MLP in frequency domain. To enforce semantic separation between the two components, we further introduce a Dual-View Alignment Loss, which aligns low-frequency information with the periodic branch and high-frequency information with the residual branch. Extensive experiments on four real-world traffic datasets demonstrate that HyperD achieves state-of-the-art prediction accuracy, while offering superior robustness under disturbances and improved computational efficiency compared to existing methods.
Dual Mamba for Node-Specific Representation Learning: Tackling Over-Smoothing with Selective State Space Modeling
Nov 11, 2025Over-smoothing remains a fundamental challenge in deep Graph Neural Networks (GNNs), where repeated message passing causes node representations to become indistinguishable. While existing solutions, such as residual connections and skip layers, alleviate this issue to some extent, they fail to explicitly model how node representations evolve in a node-specific and progressive manner across layers. Moreover, these methods do not take global information into account, which is also crucial for mitigating the over-smoothing problem. To address the aforementioned issues, in this work, we propose a Dual Mamba-enhanced Graph Convolutional Network (DMbaGCN), which is a novel framework that integrates Mamba into GNNs to address over-smoothing from both local and global perspectives. DMbaGCN consists of two modules: the Local State-Evolution Mamba (LSEMba) for local neighborhood aggregation and utilizing Mamba's selective state space modeling to capture node-specific representation dynamics across layers, and the Global Context-Aware Mamba (GCAMba) that leverages Mamba's global attention capabilities to incorporate global context for each node. By combining these components, DMbaGCN enhances node discriminability in deep GNNs, thereby mitigating over-smoothing. Extensive experiments on multiple benchmarks demonstrate the effectiveness and efficiency of our method.
BlindGuard: Safeguarding LLM-based Multi-Agent Systems under Unknown Attacks
Aug 11, 2025The security of LLM-based multi-agent systems (MAS) is critically threatened by propagation vulnerability, where malicious agents can distort collective decision-making through inter-agent message interactions. While existing supervised defense methods demonstrate promising performance, they may be impractical in real-world scenarios due to their heavy reliance on labeled malicious agents to train a supervised malicious detection model. To enable practical and generalizable MAS defenses, in this paper, we propose BlindGuard, an unsupervised defense method that learns without requiring any attack-specific labels or prior knowledge of malicious behaviors. To this end, we establish a hierarchical agent encoder to capture individual, neighborhood, and global interaction patterns of each agent, providing a comprehensive understanding for malicious agent detection. Meanwhile, we design a corruption-guided detector that consists of directional noise injection and contrastive learning, allowing effective detection model training solely on normal agent behaviors. Extensive experiments show that BlindGuard effectively detects diverse attack types (i.e., prompt injection, memory poisoning, and tool attack) across MAS with various communication patterns while maintaining superior generalizability compared to supervised baselines. The code is available at: https://github.com/MR9812/BlindGuard.
Can LLMs Find Fraudsters? Multi-level LLM Enhanced Graph Fraud Detection
Jul 16, 2025



Graph fraud detection has garnered significant attention as Graph Neural Networks (GNNs) have proven effective in modeling complex relationships within multimodal data. However, existing graph fraud detection methods typically use preprocessed node embeddings and predefined graph structures to reveal fraudsters, which ignore the rich semantic cues contained in raw textual information. Although Large Language Models (LLMs) exhibit powerful capabilities in processing textual information, it remains a significant challenge to perform multimodal fusion of processed textual embeddings with graph structures. In this paper, we propose a \textbf{M}ulti-level \textbf{L}LM \textbf{E}nhanced Graph Fraud \textbf{D}etection framework called MLED. In MLED, we utilize LLMs to extract external knowledge from textual information to enhance graph fraud detection methods. To integrate LLMs with graph structure information and enhance the ability to distinguish fraudsters, we design a multi-level LLM enhanced framework including type-level enhancer and relation-level enhancer. One is to enhance the difference between the fraudsters and the benign entities, the other is to enhance the importance of the fraudsters in different relations. The experiments on four real-world datasets show that MLED achieves state-of-the-art performance in graph fraud detection as a generalized framework that can be applied to existing methods.
Understanding the Information Propagation Effects of Communication Topologies in LLM-based Multi-Agent Systems
May 29, 2025The communication topology in large language model-based multi-agent systems fundamentally governs inter-agent collaboration patterns, critically shaping both the efficiency and effectiveness of collective decision-making. While recent studies for communication topology automated design tend to construct sparse structures for efficiency, they often overlook why and when sparse and dense topologies help or hinder collaboration. In this paper, we present a causal framework to analyze how agent outputs, whether correct or erroneous, propagate under topologies with varying sparsity. Our empirical studies reveal that moderately sparse topologies, which effectively suppress error propagation while preserving beneficial information diffusion, typically achieve optimal task performance. Guided by this insight, we propose a novel topology design approach, EIB-leanrner, that balances error suppression and beneficial information propagation by fusing connectivity patterns from both dense and sparse graphs. Extensive experiments show the superior effectiveness, communication cost, and robustness of EIB-leanrner.
A Comprehensive Survey of Synthetic Tabular Data Generation
Apr 23, 2025Tabular data remains one of the most prevalent and critical data formats across diverse real-world applications. However, its effective use in machine learning (ML) is often constrained by challenges such as data scarcity, privacy concerns, and class imbalance. Synthetic data generation has emerged as a promising solution, leveraging generative models to learn the distribution of real datasets and produce high-fidelity, privacy-preserving samples. Various generative paradigms have been explored, including energy-based models (EBMs), variational autoencoders (VAEs), generative adversarial networks (GANs), large language models (LLMs), and diffusion models. While several surveys have investigated synthetic tabular data generation, most focus on narrow subdomains or specific generative methods, such as GANs, diffusion models, or privacy-preserving techniques. This limited scope often results in fragmented insights, lacking a comprehensive synthesis that bridges diverse approaches. In particular, recent advances driven by LLMs and diffusion-based models remain underexplored. This gap hinders a holistic understanding of the field`s evolution, methodological interplay, and open challenges. To address this, our survey provides a unified and systematic review of synthetic tabular data generation. Our contributions are threefold: (1) we propose a comprehensive taxonomy that organizes existing methods into traditional approaches, diffusion-based methods, and LLM-based models, and provide an in-depth comparative analysis; (2) we detail the complete pipeline for synthetic tabular data generation, including data synthesis, post-processing, and evaluation; (3) we identify major challenges, explore real-world applications, and outline open research questions and future directions to guide future work in this rapidly evolving area.