 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Towards Competitive Search Relevance For Inference-Free Learned Sparse Retrievers
Nov 07, 2024Learned sparse retrieval, which can efficiently perform retrieval through mature inverted-index engines, has garnered growing attention in recent years. Particularly, the inference-free sparse retrievers are attractive as they eliminate online model inference in the retrieval phase thereby avoids huge computational cost, offering reasonable throughput and latency. However, even the state-of-the-art (SOTA) inference-free sparse models lag far behind in terms of search relevance when compared to both sparse and dense siamese models. Towards competitive search relevance for inference-free sparse retrievers, we argue that they deserve dedicated training methods other than using same ones with siamese encoders. In this paper, we propose two different approaches for performance improvement. First, we introduce the IDF-aware FLOPS loss, which introduces Inverted Document Frequency (IDF) to the sparsification of representations. We find that it mitigates the negative impact of the FLOPS regularization on search relevance, allowing the model to achieve a better balance between accuracy and efficiency. Moreover, we propose a heterogeneous ensemble knowledge distillation framework that combines siamese dense and sparse retrievers to generate supervisory signals during the pre-training phase. The ensemble framework of dense and sparse retriever capitalizes on their strengths respectively, providing a strong upper bound for knowledge distillation. To concur the diverse feedback from heterogeneous supervisors, we normalize and then aggregate the outputs of the teacher models to eliminate score scale differences. On the BEIR benchmark, our model outperforms existing SOTA inference-free sparse model by \textbf{3.3 NDCG@10 score}. It exhibits search relevance comparable to siamese sparse retrievers and client-side latency only \textbf{1.1x that of BM25}.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Aug 13, 2024



The rapid growth of scientific literature imposes significant challenges for researchers endeavoring to stay updated with the latest advancements in their fields and delve into new areas. We introduce OpenResearcher, an innovative platform that leverages Artificial Intelligence (AI) techniques to accelerate the research process by answering diverse questions from researchers. OpenResearcher is built based on Retrieval-Augmented Generation (RAG) to integrate Large Language Models (LLMs) with up-to-date, domain-specific knowledge. Moreover, we develop various tools for OpenResearcher to understand researchers' queries, search from the scientific literature, filter retrieved information, provide accurate and comprehensive answers, and self-refine these answers. OpenResearcher can flexibly use these tools to balance efficiency and effectiveness. As a result, OpenResearcher enables researchers to save time and increase their potential to discover new insights and drive scientific breakthroughs. Demo, video, and code are available at: https://github.com/GAIR-NLP/OpenResearcher.
Unified Lexical Representation for Interpretable Visual-Language Alignment
Jul 25, 2024



Visual-Language Alignment (VLA) has gained a lot of attention since CLIP's groundbreaking work. Although CLIP performs well, the typical direct latent feature alignment lacks clarity in its representation and similarity scores. On the other hand, lexical representation, a vector whose element represents the similarity between the sample and a word from the vocabulary, is a natural sparse representation and interpretable, providing exact matches for individual words. However, lexical representations is difficult to learn due to no ground-truth supervision and false-discovery issues, and thus requires complex design to train effectively. In this paper, we introduce LexVLA, a more interpretable VLA framework by learning a unified lexical representation for both modalities without complex design. We use DINOv2 as our visual model for its local-inclined features and Llama 2, a generative language model, to leverage its in-context lexical prediction ability. To avoid the false discovery, we propose an overuse penalty to refrain the lexical representation from falsely frequently activating meaningless words. We demonstrate that these two pre-trained uni-modal models can be well-aligned by fine-tuning on modest multi-modal dataset and avoid intricate training configurations. On cross-modal retrieval benchmarks, LexVLA, trained on the CC-12M multi-modal dataset, outperforms baselines fine-tuned on larger datasets (e.g., YFCC15M) and those trained from scratch on even bigger datasets (e.g., 1.1B data, including CC-12M). We conduct extensive experiments to analyze LexVLA.
RefChecker: Reference-based Fine-grained Hallucination Checker and Benchmark for Large Language Models
May 23, 2024



Large Language Models (LLMs) have shown impressive capabilities but also a concerning tendency to hallucinate. This paper presents RefChecker, a framework that introduces claim-triplets to represent claims in LLM responses, aiming to detect fine-grained hallucinations. In RefChecker, an extractor generates claim-triplets from a response, which are then evaluated by a checker against a reference. We delineate three task settings: Zero, Noisy and Accurate Context, to reflect various real-world use cases. We curated a benchmark spanning various NLP tasks and annotated 11k claim-triplets from 2.1k responses by seven LLMs. RefChecker supports both proprietary and open-source models as the extractor and checker. Experiments demonstrate that claim-triplets enable superior hallucination detection, compared to other granularities such as response, sentence and sub-sentence level claims. RefChecker outperforms prior methods by 6.8 to 26.1 points on our benchmark and the checking results of RefChecker are strongly aligned with human judgments. This work is open sourced at https://github.com/amazon-science/RefChecker
StoryAnalogy: Deriving Story-level Analogies from Large Language Models to Unlock Analogical Understanding
Oct 23, 2023Analogy-making between narratives is crucial for human reasoning. In this paper, we evaluate the ability to identify and generate analogies by constructing a first-of-its-kind large-scale story-level analogy corpus, \textsc{StoryAnalogy}, which contains 24K story pairs from diverse domains with human annotations on two similarities from the extended Structure-Mapping Theory. We design a set of tests on \textsc{StoryAnalogy}, presenting the first evaluation of story-level analogy identification and generation. Interestingly, we find that the analogy identification tasks are incredibly difficult not only for sentence embedding models but also for the recent large language models (LLMs) such as ChatGPT and LLaMa. ChatGPT, for example, only achieved around 30% accuracy in multiple-choice questions (compared to over 85% accuracy for humans). Furthermore, we observe that the data in \textsc{StoryAnalogy} can improve the quality of analogy generation in LLMs, where a fine-tuned FlanT5-xxl model achieves comparable performance to zero-shot ChatGPT.
Distributed Marker Representation for Ambiguous Discourse Markers and Entangled Relations
Jun 19, 2023Discourse analysis is an important task because it models intrinsic semantic structures between sentences in a document. Discourse markers are natural representations of discourse in our daily language. One challenge is that the markers as well as pre-defined and human-labeled discourse relations can be ambiguous when describing the semantics between sentences. We believe that a better approach is to use a contextual-dependent distribution over the markers to express discourse information. In this work, we propose to learn a Distributed Marker Representation (DMR) by utilizing the (potentially) unlimited discourse marker data with a latent discourse sense, thereby bridging markers with sentence pairs. Such representations can be learned automatically from data without supervision, and in turn provide insights into the data itself. Experiments show the SOTA performance of our DMR on the implicit discourse relation recognition task and strong interpretability. Our method also offers a valuable tool to understand complex ambiguity and entanglement among discourse markers and manually defined discourse relations.
Learning Logic Rules for Document-level Relation Extraction
Nov 09, 2021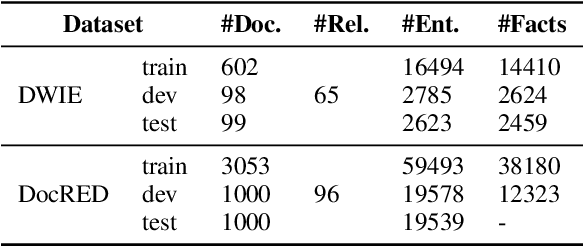

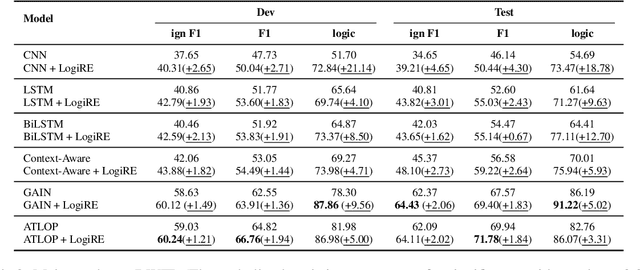

Document-level relation extraction aims to identify relations between entities in a whole document. Prior efforts to capture long-range dependencies have relied heavily on implicitly powerful representations learned through (graph) neural networks, which makes the model less transparent. To tackle this challenge, in this paper, we propose LogiRE, a novel probabilistic model for document-level relation extraction by learning logic rules. LogiRE treats logic rules as latent variables and consists of two modules: a rule generator and a relation extractor. The rule generator is to generate logic rules potentially contributing to final predictions, and the relation extractor outputs final predictions based on the generated logic rules. Those two modules can be efficiently optimized with the expectation-maximization (EM) algorithm. By introducing logic rules into neural networks, LogiRE can explicitly capture long-range dependencies as well as enjoy better interpretation. Empirical results show that LogiRE significantly outperforms several strong baselines in terms of relation performance (1.8 F1 score) and logical consistency (over 3.3 logic score). Our code is available at https://github.com/rudongyu/LogiRE.
Active Sentence Learning by Adversarial Uncertainty Sampling in Discrete Space
Apr 17, 2020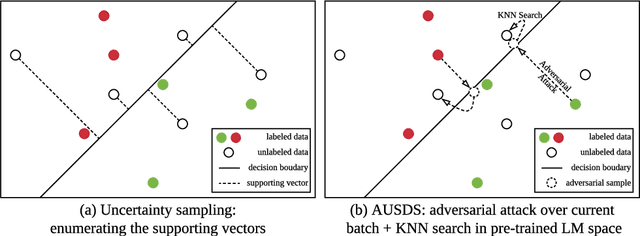

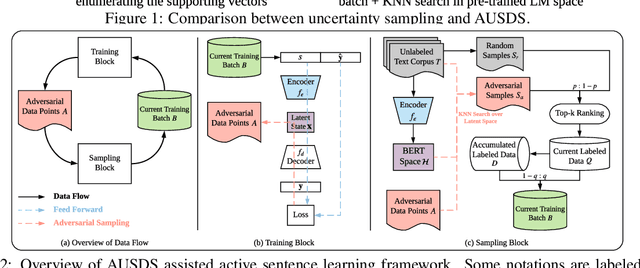

In this paper, we focus on reducing the labeled data size for sentence learning. We argue that real-time uncertainty sampling of active learning is time-consuming, and delayed uncertainty sampling may lead to the ineffective sampling problem. We propose the adversarial uncertainty sampling in discrete space, in which sentences are mapped into the popular pre-trained language model encoding space. Our proposed approach can work in real-time and is more efficient than traditional uncertainty sampling. Experimental results on five datasets show that our proposed approach outperforms strong baselines and can achieve better uncertainty sampling effectiveness with acceptable running time.