 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents
Apr 03, 2026Memory makes LLM-based web agents personalized, powerful, yet exploitable. By storing past interactions to personalize future tasks, agents inadvertently create a persistent attack surface that spans websites and sessions. While existing security research on memory assumes attackers can directly inject into memory storage or exploit shared memory across users, we present a more realistic threat model: contamination through environmental observation alone. We introduce Environment-injected Trajectory-based Agent Memory Poisoning (eTAMP), the first attack to achieve cross-session, cross-site compromise without requiring direct memory access. A single contaminated observation (e.g., viewing a manipulated product page) silently poisons an agent's memory and activates during future tasks on different websites, bypassing permission-based defenses. Our experiments on (Visual)WebArena reveal two key findings. First, eTAMP achieves substantial attack success rates: up to 32.5% on GPT-5-mini, 23.4% on GPT-5.2, and 19.5% on GPT-OSS-120B. Second, we discover Frustration Exploitation: agents under environmental stress become dramatically more susceptible, with ASR increasing up to 8 times when agents struggle with dropped clicks or garbled text. Notably, more capable models are not more secure. GPT-5.2 shows substantial vulnerability despite superior task performance. With the rise of AI browsers like OpenClaw, ChatGPT Atlas, and Perplexity Comet, our findings underscore the urgent need for defenses against environment-injected memory poisoning.
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
Jan 24, 2025



Recent advances in natural language processing have leveraged instruction tuning to enhance Large Language Models (LLMs) for table-related tasks. However, previous works train different base models with different training data, lacking an apples-to-apples comparison across the result table LLMs. To address this, we fine-tune base models from the Mistral, OLMo, and Phi families on existing public training datasets. Our replication achieves performance on par with or surpassing existing table LLMs, establishing new state-of-the-art performance on Hitab, a table question-answering dataset. More importantly, through systematic out-of-domain evaluation, we decouple the contributions of training data and the base model, providing insight into their individual impacts. In addition, we assess the effects of table-specific instruction tuning on general-purpose benchmarks, revealing trade-offs between specialization and generalization.
PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries
Oct 14, 2024



Previous text-to-SQL datasets and systems have primarily focused on user questions with clear intentions that can be answered. However, real user questions can often be ambiguous with multiple interpretations or unanswerable due to a lack of relevant data. In this work, we construct a practical conversational text-to-SQL dataset called PRACTIQ, consisting of ambiguous and unanswerable questions inspired by real-world user questions. We first identified four categories of ambiguous questions and four categories of unanswerable questions by studying existing text-to-SQL datasets. Then, we generate conversations with four turns: the initial user question, an assistant response seeking clarification, the user's clarification, and the assistant's clarified SQL response with the natural language explanation of the execution results. For some ambiguous queries, we also directly generate helpful SQL responses, that consider multiple aspects of ambiguity, instead of requesting user clarification. To benchmark the performance on ambiguous, unanswerable, and answerable questions, we implemented large language model (LLM)-based baselines using various LLMs. Our approach involves two steps: question category classification and clarification SQL prediction. Our experiments reveal that state-of-the-art systems struggle to handle ambiguous and unanswerable questions effectively. We will release our code for data generation and experiments on GitHub.
You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL
Sep 18, 2024



While significant progress has been made on the text-to-SQL task, recent solutions repeatedly encode the same database schema for every question, resulting in unnecessary high inference cost and often overlooking crucial database knowledge. To address these issues, we propose You Only Read Once (YORO), a novel paradigm that directly internalizes database knowledge into the parametric knowledge of a text-to-SQL model during training and eliminates the need for schema encoding during inference. YORO significantly reduces the input token length by 66%-98%. Despite its shorter inputs, our empirical results demonstrate YORO's competitive performances with traditional systems on three benchmarks as well as its significant outperformance on large databases. Furthermore, YORO excels in handling questions with challenging value retrievals such as abbreviation.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
Selective Demonstrations for Cross-domain Text-to-SQL
Oct 10, 2023Large language models (LLMs) with in-context learning have demonstrated impressive generalization capabilities in the cross-domain text-to-SQL task, without the use of in-domain annotations. However, incorporating in-domain demonstration examples has been found to greatly enhance LLMs' performance. In this paper, we delve into the key factors within in-domain examples that contribute to the improvement and explore whether we can harness these benefits without relying on in-domain annotations. Based on our findings, we propose a demonstration selection framework ODIS which utilizes both out-of-domain examples and synthetically generated in-domain examples to construct demonstrations. By retrieving demonstrations from hybrid sources, ODIS leverages the advantages of both, showcasing its effectiveness compared to baseline methods that rely on a single data source. Furthermore, ODIS outperforms state-of-the-art approaches on two cross-domain text-to-SQL datasets, with improvements of 1.1 and 11.8 points in execution accuracy, respectively.
How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings
May 23, 2023Large language models (LLMs) with in-context learning have demonstrated remarkable capability in the text-to-SQL task. Previous research has prompted LLMs with various demonstration-retrieval strategies and intermediate reasoning steps to enhance the performance of LLMs. However, those works often employ varied strategies when constructing the prompt text for text-to-SQL inputs, such as databases and demonstration examples. This leads to a lack of comparability in both the prompt constructions and their primary contributions. Furthermore, selecting an effective prompt construction has emerged as a persistent problem for future research. To address this limitation, we comprehensively investigate the impact of prompt constructions across various settings and provide insights for future work.
Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness
Jan 21, 2023



Neural text-to-SQL models have achieved remarkable performance in translating natural language questions into SQL queries. However, recent studies reveal that text-to-SQL models are vulnerable to task-specific perturbations. Previous curated robustness test sets usually focus on individual phenomena. In this paper, we propose a comprehensive robustness benchmark based on Spider, a cross-domain text-to-SQL benchmark, to diagnose the model robustness. We design 17 perturbations on databases, natural language questions, and SQL queries to measure the robustness from different angles. In order to collect more diversified natural question perturbations, we utilize large pretrained language models (PLMs) to simulate human behaviors in creating natural questions. We conduct a diagnostic study of the state-of-the-art models on the robustness set. Experimental results reveal that even the most robust model suffers from a 14.0% performance drop overall and a 50.7% performance drop on the most challenging perturbation. We also present a breakdown analysis regarding text-to-SQL model designs and provide insights for improving model robustness.
MapQA: A Dataset for Question Answering on Choropleth Maps
Nov 15, 2022Choropleth maps are a common visual representation for region-specific tabular data and are used in a number of different venues (newspapers, articles, etc). These maps are human-readable but are often challenging to deal with when trying to extract data for screen readers, analyses, or other related tasks. Recent research into Visual-Question Answering (VQA) has studied question answering on human-generated charts (ChartQA), such as bar, line, and pie charts. However, little work has paid attention to understanding maps; general VQA models, and ChartQA models, suffer when asked to perform this task. To facilitate and encourage research in this area, we present MapQA, a large-scale dataset of ~800K question-answer pairs over ~60K map images. Our task tests various levels of map understanding, from surface questions about map styles to complex questions that require reasoning on the underlying data. We present the unique challenges of MapQA that frustrate most strong baseline algorithms designed for ChartQA and general VQA tasks. We also present a novel algorithm, Visual Multi-Output Data Extraction based QA (V-MODEQA) for MapQA. V-MODEQA extracts the underlying structured data from a map image with a multi-output model and then performs reasoning on the extracted data. Our experimental results show that V-MODEQA has better overall performance and robustness on MapQA than the state-of-the-art ChartQA and VQA algorithms by capturing the unique properties in map question answering.
Prefix-to-SQL: Text-to-SQL Generation from Incomplete User Questions
Sep 30, 2021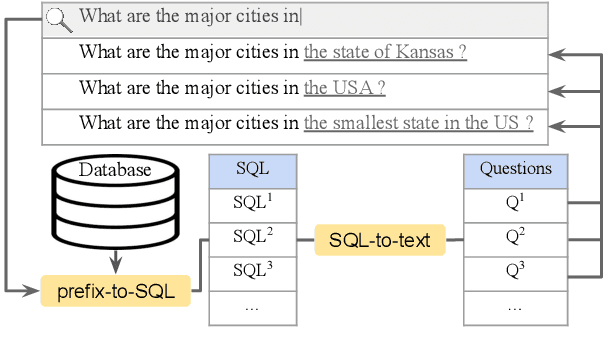

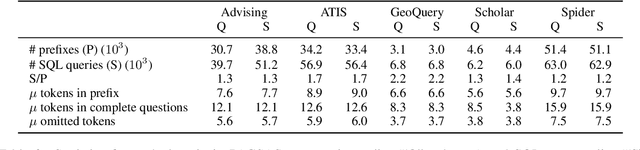
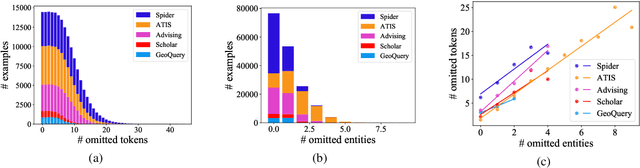
Existing text-to-SQL research only considers complete questions as the input, but lay-users might strive to formulate a complete question. To build a smarter natural language interface to database systems (NLIDB) that also processes incomplete questions, we propose a new task, prefix-to-SQL which takes question prefix from users as the input and predicts the intended SQL. We construct a new benchmark called PAGSAS that contains 124K user question prefixes and the intended SQL for 5 sub-tasks Advising, GeoQuery, Scholar, ATIS, and Spider. Additionally, we propose a new metric SAVE to measure how much effort can be saved by users. Experimental results show that PAGSAS is challenging even for strong baseline models such as T5. As we observe the difficulty of prefix-to-SQL is related to the number of omitted tokens, we incorporate curriculum learning of feeding examples with an increasing number of omitted tokens. This improves scores on various sub-tasks by as much as 9% recall scores on sub-task GeoQuery in PAGSAS.