 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Aug 13, 2024



The rapid growth of scientific literature imposes significant challenges for researchers endeavoring to stay updated with the latest advancements in their fields and delve into new areas. We introduce OpenResearcher, an innovative platform that leverages Artificial Intelligence (AI) techniques to accelerate the research process by answering diverse questions from researchers. OpenResearcher is built based on Retrieval-Augmented Generation (RAG) to integrate Large Language Models (LLMs) with up-to-date, domain-specific knowledge. Moreover, we develop various tools for OpenResearcher to understand researchers' queries, search from the scientific literature, filter retrieved information, provide accurate and comprehensive answers, and self-refine these answers. OpenResearcher can flexibly use these tools to balance efficiency and effectiveness. As a result, OpenResearcher enables researchers to save time and increase their potential to discover new insights and drive scientific breakthroughs. Demo, video, and code are available at: https://github.com/GAIR-NLP/OpenResearcher.
FRoG: Evaluating Fuzzy Reasoning of Generalized Quantifiers in Large Language Models
Jul 01, 2024



Fuzzy reasoning is vital due to the frequent use of imprecise information in daily contexts. However, the ability of current large language models (LLMs) to handle such reasoning remains largely uncharted. In this paper, we introduce a new benchmark, FRoG, for fuzzy reasoning, featuring real-world mathematical word problems that incorporate generalized quantifiers. Our experimental findings reveal that fuzzy reasoning continues to pose significant challenges for LLMs. Moreover, we find that existing methods designed to enhance reasoning do not consistently improve performance in tasks involving fuzzy logic. Additionally, our results show an inverse scaling effect in the performance of LLMs on FRoG. Interestingly, we also demonstrate that strong mathematical reasoning skills are not necessarily indicative of success on our benchmark.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024



The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Prompt Chaining or Stepwise Prompt? Refinement in Text Summarization
Jun 01, 2024



Large language models (LLMs) have demonstrated the capacity to improve summary quality by mirroring a human-like iterative process of critique and refinement starting from the initial draft. Two strategies are designed to perform this iterative process: Prompt Chaining and Stepwise Prompt. Prompt chaining orchestrates the drafting, critiquing, and refining phases through a series of three discrete prompts, while Stepwise prompt integrates these phases within a single prompt. However, the relative effectiveness of the two methods has not been extensively studied. This paper is dedicated to examining and comparing these two methods in the context of text summarization to ascertain which method stands out as the most effective. Experimental results show that the prompt chaining method can produce a more favorable outcome. This might be because stepwise prompt might produce a simulated refinement process according to our various experiments. Since refinement is adaptable to diverse tasks, our conclusions have the potential to be extrapolated to other applications, thereby offering insights that may contribute to the broader development of LLMs.
Dissecting Human and LLM Preferences
Feb 17, 2024



As a relative quality comparison of model responses, human and Large Language Model (LLM) preferences serve as common alignment goals in model fine-tuning and criteria in evaluation. Yet, these preferences merely reflect broad tendencies, resulting in less explainable and controllable models with potential safety risks. In this work, we dissect the preferences of human and 32 different LLMs to understand their quantitative composition, using annotations from real-world user-model conversations for a fine-grained, scenario-wise analysis. We find that humans are less sensitive to errors, favor responses that support their stances, and show clear dislike when models admit their limits. On the contrary, advanced LLMs like GPT-4-Turbo emphasize correctness, clarity, and harmlessness more. Additionally, LLMs of similar sizes tend to exhibit similar preferences, regardless of their training methods, and fine-tuning for alignment does not significantly alter the preferences of pretrained-only LLMs. Finally, we show that preference-based evaluation can be intentionally manipulated. In both training-free and training-based settings, aligning a model with the preferences of judges boosts scores, while injecting the least preferred properties lowers them. This results in notable score shifts: up to 0.59 on MT-Bench (1-10 scale) and 31.94 on AlpacaEval 2.0 (0-100 scale), highlighting the significant impact of this strategic adaptation. Interactive Demo: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization Dataset: https://huggingface.co/datasets/GAIR/preference-dissection Code: https://github.com/GAIR-NLP/Preference-Dissection
The Critique of Critique
Jan 09, 2024



Critique, as a natural language description for assessing the quality of model-generated content, has been proven to play an essential role in the training, evaluation, and refinement of Large Language Models (LLMs). However, there is a lack of principled understanding in evaluating the quality of the critique itself. In this paper, we pioneer the critique of critique, termed MetaCritique, which is a framework to evaluate the critique from two aspects, i.e., factuality as precision score and comprehensiveness as recall score. We calculate the harmonic mean of precision and recall as the overall rating called F1 score. To obtain a reliable evaluation outcome, we propose Atomic Information Units (AIUs), which describe the critique in a more fine-grained manner. MetaCritique takes each AIU into account and aggregates each AIU's judgment for the overall score. Moreover, given the evaluation process involves intricate reasoning, our MetaCritique provides a natural language rationale to support each judgment. We construct a meta-evaluation dataset containing 300 critiques (2653 AIUs) across four tasks (question answering, reasoning, entailment, and summarization), and we conduct a comparative study to demonstrate the feasibility and effectiveness. Experiments also show superior critique judged by MetaCritique leads to better refinement, indicating generative artificial intelligence indeed has the potential to be significantly advanced with our MetaCritique. We will release relevant code and meta-evaluation datasets at https://github.com/GAIR-NLP/MetaCritique.
Evolving Large Language Model Assistant with Long-Term Conditional Memory
Dec 22, 2023



With the rapid development of large language models, AI assistants like ChatGPT have widely entered people's works and lives. In this paper, we present an evolving large language model assistant that utilizes verbal long-term memory. It focuses on preserving the knowledge and experience from the history dialogue between the user and AI assistant, which can be applied to future dialogue for generating a better response. The model generates a set of records for each finished dialogue and stores them in the memory. In later usage, given a new user input, the model uses it to retrieve its related memory to improve the quality of the response. To find the best form of memory, we explore different ways of constructing the memory and propose a new memorizing mechanism called conditional memory to solve the problems in previous methods. We also investigate the retrieval and usage of memory in the generation process. The assistant uses GPT-4 as the backbone and we evaluate it on three constructed test datasets focusing on different abilities required by an AI assistant with long-term memory.
Generative Judge for Evaluating Alignment
Oct 09, 2023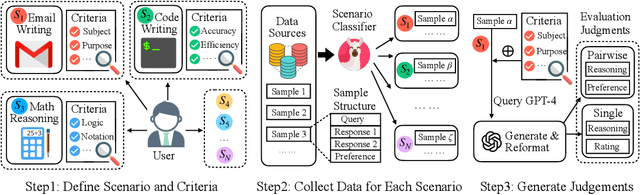
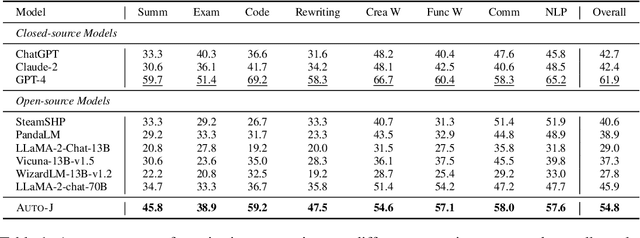
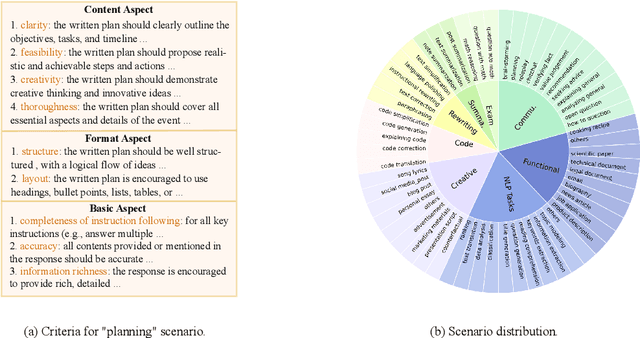
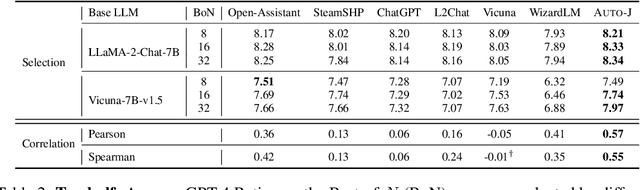
The rapid development of Large Language Models (LLMs) has substantially expanded the range of tasks they can address. In the field of Natural Language Processing (NLP), researchers have shifted their focus from conventional NLP tasks (e.g., sequence tagging and parsing) towards tasks that revolve around aligning with human needs (e.g., brainstorming and email writing). This shift in task distribution imposes new requirements on evaluating these aligned models regarding generality (i.e., assessing performance across diverse scenarios), flexibility (i.e., examining under different protocols), and interpretability (i.e., scrutinizing models with explanations). In this paper, we propose a generative judge with 13B parameters, Auto-J, designed to address these challenges. Our model is trained on user queries and LLM-generated responses under massive real-world scenarios and accommodates diverse evaluation protocols (e.g., pairwise response comparison and single-response evaluation) with well-structured natural language critiques. To demonstrate the efficacy of our approach, we construct a new testbed covering 58 different scenarios. Experimentally, Auto-J outperforms a series of strong competitors, including both open-source and closed-source models, by a large margin. We also provide detailed analysis and case studies to further reveal the potential of our method and make a variety of resources public at https://github.com/GAIR-NLP/auto-j.
Aligning Language Models with Human Preferences via a Bayesian Approach
Oct 09, 2023



In the quest to advance human-centric natural language generation (NLG) systems, ensuring alignment between NLG models and human preferences is crucial. For this alignment, current popular methods leverage a reinforcement learning (RL) approach with a reward model trained on feedback from humans. However, inherent disagreements due to the subjective nature of human preferences pose a significant challenge for training the reward model, resulting in a deterioration of the NLG performance. To tackle this issue, previous approaches typically rely on majority voting or averaging to consolidate multiple inconsistent preferences into a merged one. Although straightforward to understand and execute, such methods suffer from an inability to capture the nuanced degrees of disaggregation among humans and may only represent a specialized subset of individuals, thereby lacking the ability to quantitatively disclose the universality of human preferences. To address this challenge, this paper proposes a novel approach, which employs a Bayesian framework to account for the distribution of disagreements among human preferences as training a preference model, and names it as d-PM. Besides, considering the RL strategy's inefficient and complex training process over the training efficiency, we further propose utilizing the contrastive learning strategy to train the NLG model with the preference scores derived from the d-PM model. Extensive experiments on two human-centric NLG tasks, i.e., emotional support conversation and integrity "Rule-of-Thumb" generation, show that our method consistently exceeds previous SOTA models in both automatic and human evaluations.