 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer
Apr 18, 2021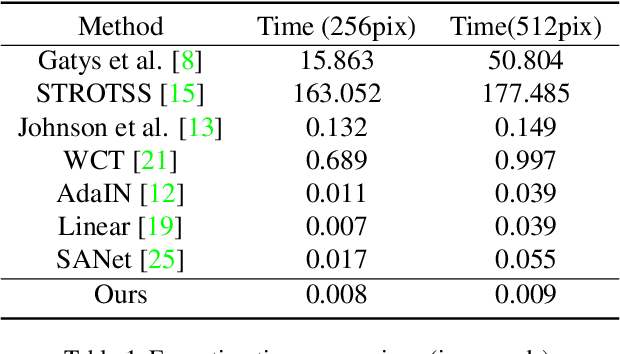
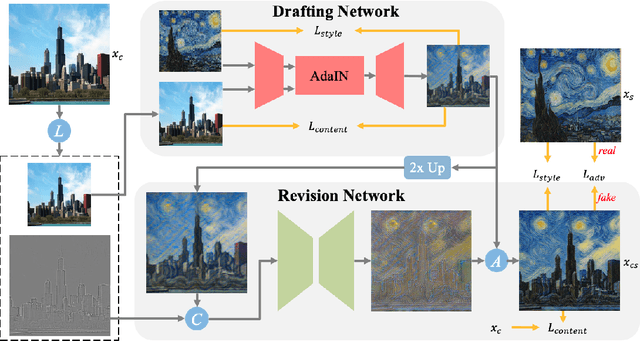
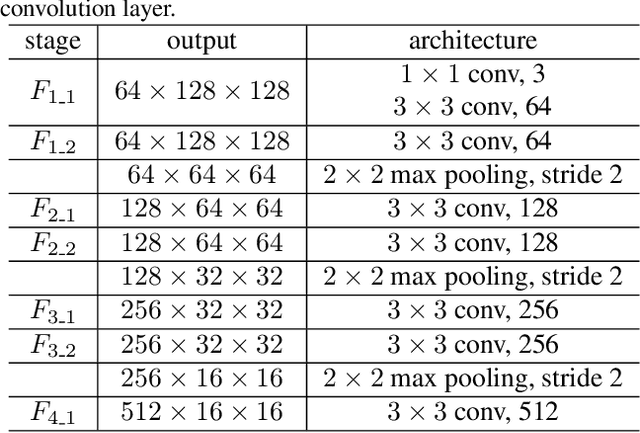
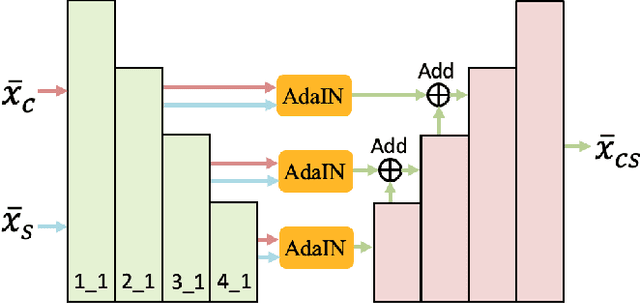
Artistic style transfer aims at migrating the style from an example image to a content image. Currently, optimization-based methods have achieved great stylization quality, but expensive time cost restricts their practical applications. Meanwhile, feed-forward methods still fail to synthesize complex style, especially when holistic global and local patterns exist. Inspired by the common painting process of drawing a draft and revising the details, we introduce a novel feed-forward method named Laplacian Pyramid Network (LapStyle). LapStyle first transfers global style patterns in low-resolution via a Drafting Network. It then revises the local details in high-resolution via a Revision Network, which hallucinates a residual image according to the draft and the image textures extracted by Laplacian filtering. Higher resolution details can be easily generated by stacking Revision Networks with multiple Laplacian pyramid levels. The final stylized image is obtained by aggregating outputs of all pyramid levels. %We also introduce a patch discriminator to better learn local patterns adversarially. Experiments demonstrate that our method can synthesize high quality stylized images in real time, where holistic style patterns are properly transferred.
Learning Semantic Person Image Generation by Region-Adaptive Normalization
Apr 14, 2021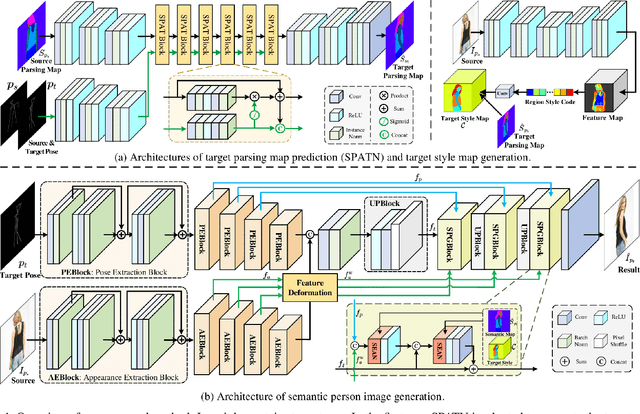
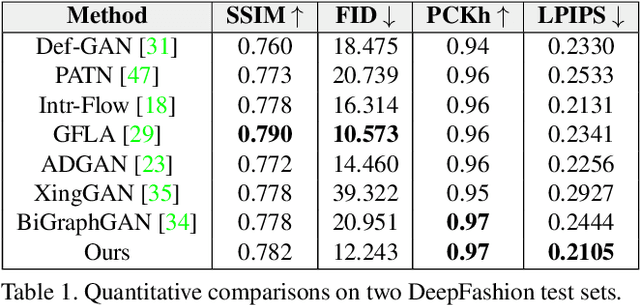
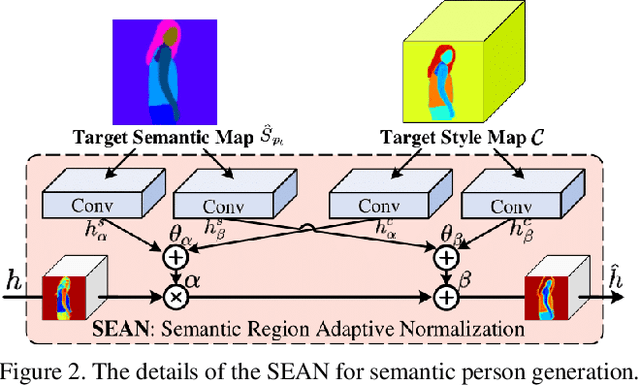

Human pose transfer has received great attention due to its wide applications, yet is still a challenging task that is not well solved. Recent works have achieved great success to transfer the person image from the source to the target pose. However, most of them cannot well capture the semantic appearance, resulting in inconsistent and less realistic textures on the reconstructed results. To address this issue, we propose a new two-stage framework to handle the pose and appearance translation. In the first stage, we predict the target semantic parsing maps to eliminate the difficulties of pose transfer and further benefit the latter translation of per-region appearance style. In the second one, with the predicted target semantic maps, we suggest a new person image generation method by incorporating the region-adaptive normalization, in which it takes the per-region styles to guide the target appearance generation. Extensive experiments show that our proposed SPGNet can generate more semantic, consistent, and photo-realistic results and perform favorably against the state of the art methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SPGNet.git.
Beyond Self-Supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones
Mar 10, 2021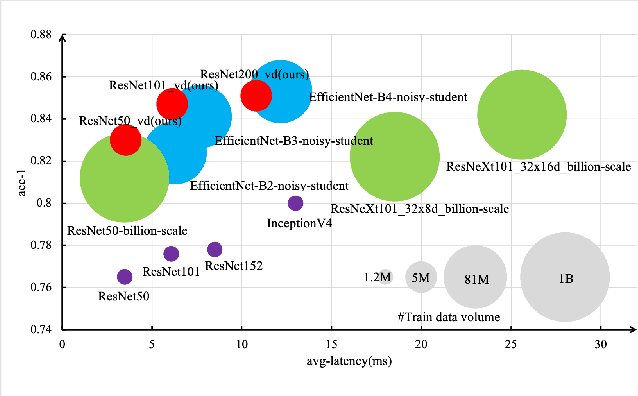
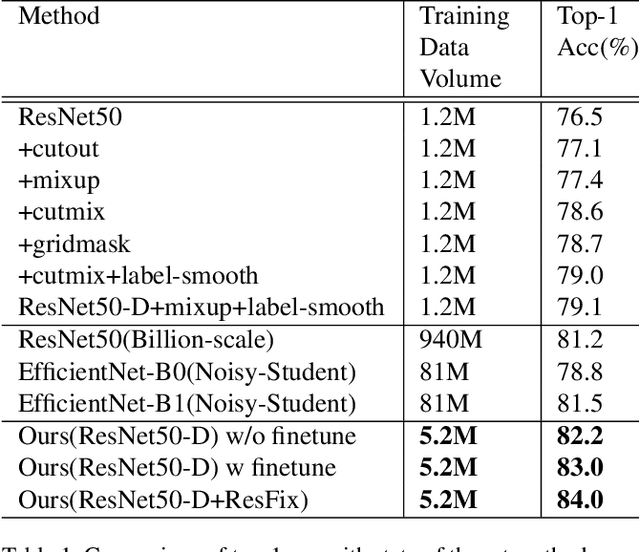
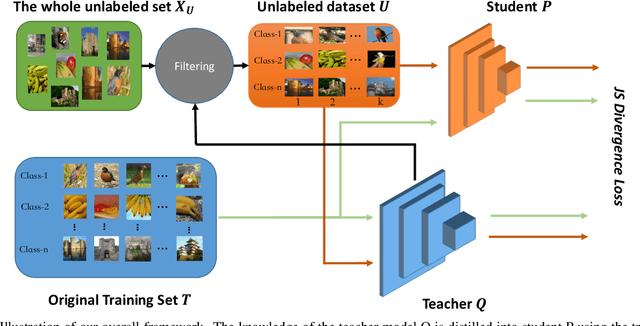
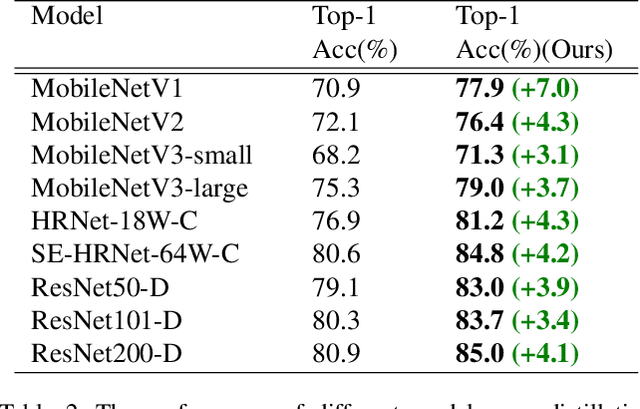
Recently, research efforts have been concentrated on revealing how pre-trained model makes a difference in neural network performance. Self-supervision and semi-supervised learning technologies have been extensively explored by the community and are proven to be of great potential in obtaining a powerful pre-trained model. However, these models require huge training costs (i.e., hundreds of millions of images or training iterations). In this paper, we propose to improve existing baseline networks via knowledge distillation from off-the-shelf pre-trained big powerful models. Different from existing knowledge distillation frameworks which require student model to be consistent with both soft-label generated by teacher model and hard-label annotated by humans, our solution performs distillation by only driving prediction of the student model consistent with that of the teacher model. Therefore, our distillation setting can get rid of manually labeled data and can be trained with extra unlabeled data to fully exploit capability of teacher model for better learning. We empirically find that such simple distillation settings perform extremely effective, for example, the top-1 accuracy on ImageNet-1k validation set of MobileNetV3-large and ResNet50-D can be significantly improved from 75.2% to 79% and 79.1% to 83%, respectively. We have also thoroughly analyzed what are dominant factors that affect the distillation performance and how they make a difference. Extensive downstream computer vision tasks, including transfer learning, object detection and semantic segmentation, can significantly benefit from the distilled pretrained models. All our experiments are implemented based on PaddlePaddle, codes and a series of improved pretrained models with ssld suffix are available in PaddleClas.
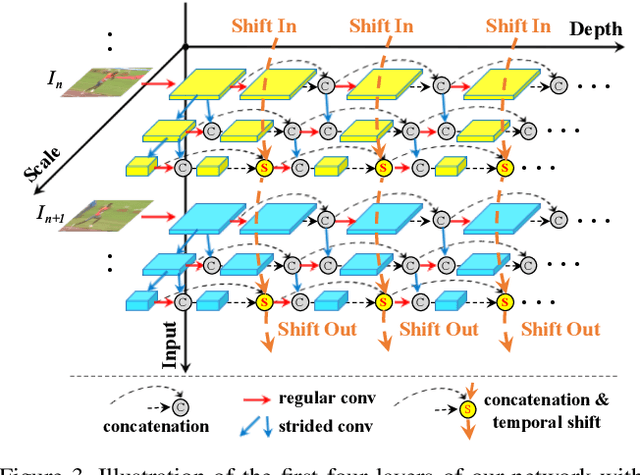
MVFNet: Multi-View Fusion Network for Efficient Video Recognition
Jan 05, 2021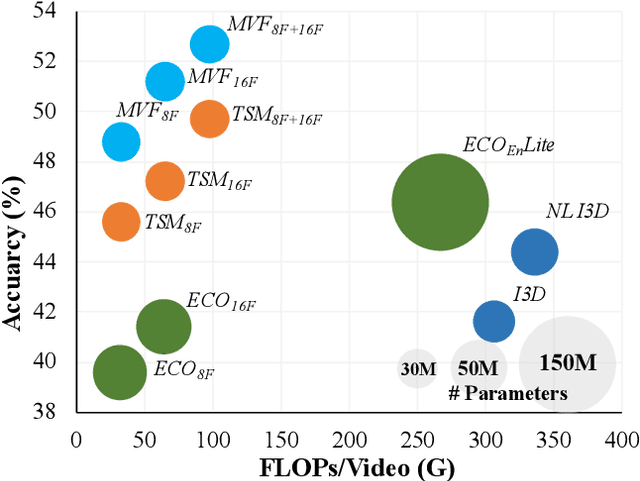
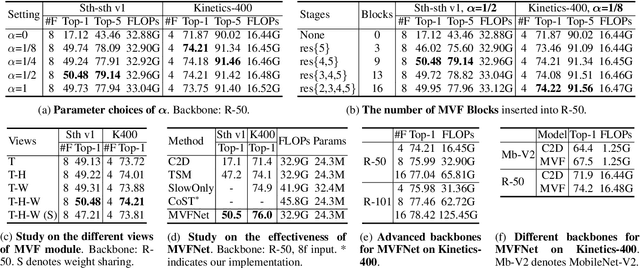
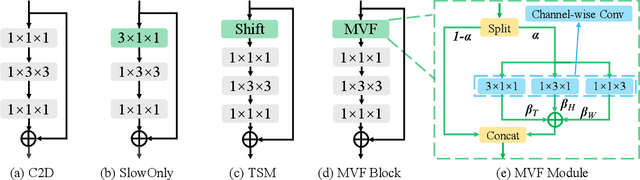
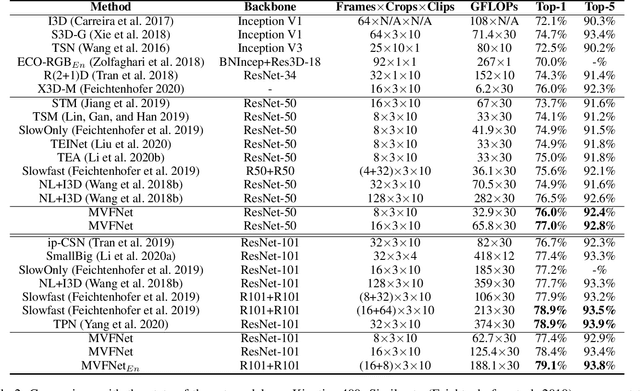
Conventionally, spatiotemporal modeling network and its complexity are the two most concentrated research topics in video action recognition. Existing state-of-the-art methods have achieved excellent accuracy regardless of the complexity meanwhile efficient spatiotemporal modeling solutions are slightly inferior in performance. In this paper, we attempt to acquire both efficiency and effectiveness simultaneously. First of all, besides traditionally treating H x W x T video frames as space-time signal (viewing from the Height-Width spatial plane), we propose to also model video from the other two Height-Time and Width-Time planes, to capture the dynamics of video thoroughly. Secondly, our model is designed based on 2D CNN backbones and model complexity is well kept in mind by design. Specifically, we introduce a novel multi-view fusion (MVF) module to exploit video dynamics using separable convolution for efficiency. It is a plug-and-play module and can be inserted into off-the-shelf 2D CNNs to form a simple yet effective model called MVFNet. Moreover, MVFNet can be thought of as a generalized video modeling framework and it can specialize to be existing methods such as C2D, SlowOnly, and TSM under different settings. Extensive experiments are conducted on popular benchmarks (i.e., Something-Something V1 & V2, Kinetics, UCF-101, and HMDB-51) to show its superiority. The proposed MVFNet can achieve state-of-the-art performance with 2D CNN's complexity.
HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
Oct 15, 2020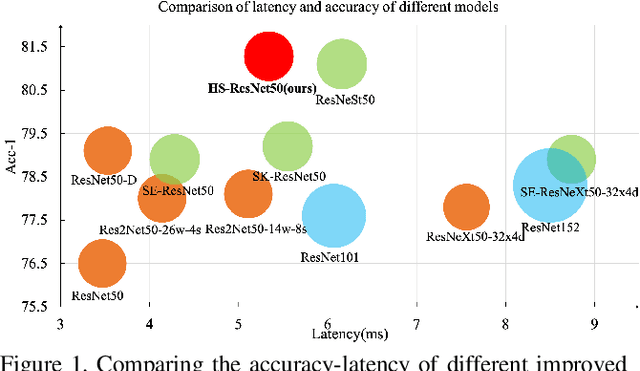
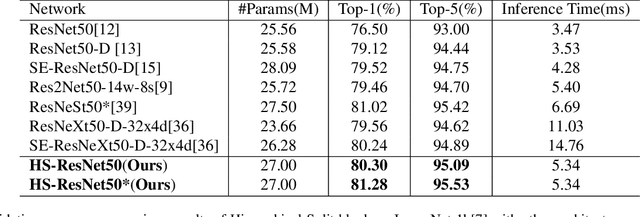
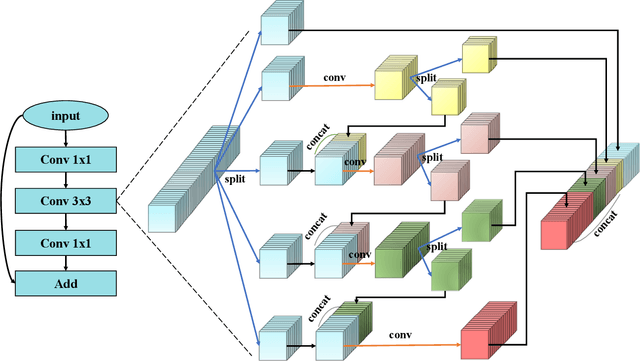

This paper addresses representational block named Hierarchical-Split Block, which can be taken as a plug-and-play block to upgrade existing convolutional neural networks, improves model performance significantly in a network. Hierarchical-Split Block contains many hierarchical split and concatenate connections within one single residual block. We find multi-scale features is of great importance for numerous vision tasks. Moreover, Hierarchical-Split block is very flexible and efficient, which provides a large space of potential network architectures for different applications. In this work, we present a common backbone based on Hierarchical-Split block for tasks: image classification, object detection, instance segmentation and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baseline. As shown in Figure1, for image classification, our 50-layers network(HS-ResNet50) achieves 81.28% top-1 accuracy with competitive latency on ImageNet-1k dataset. It also outperforms most state-of-the-art models. The source code and models will be available on: https://github.com/PaddlePaddle/PaddleClas
NTIRE 2020 Challenge on Video Quality Mapping: Methods and Results
May 06, 2020

This paper reviews the NTIRE 2020 challenge on video quality mapping (VQM), which addresses the issues of quality mapping from source video domain to target video domain. The challenge includes both a supervised track (track 1) and a weakly-supervised track (track 2) for two benchmark datasets. In particular, track 1 offers a new Internet video benchmark, requiring algorithms to learn the map from more compressed videos to less compressed videos in a supervised training manner. In track 2, algorithms are required to learn the quality mapping from one device to another when their quality varies substantially and weakly-aligned video pairs are available. For track 1, in total 7 teams competed in the final test phase, demonstrating novel and effective solutions to the problem. For track 2, some existing methods are evaluated, showing promising solutions to the weakly-supervised video quality mapping problem.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
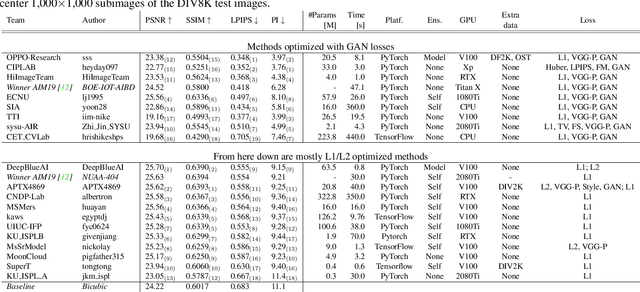

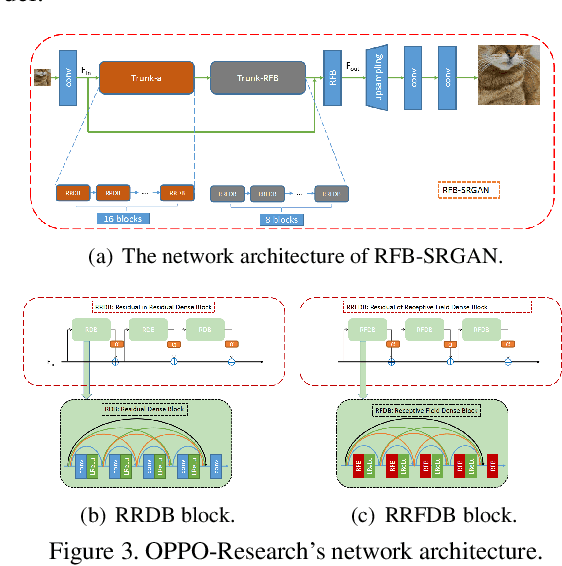
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Dynamic Inference: A New Approach Toward Efficient Video Action Recognition
Feb 09, 2020
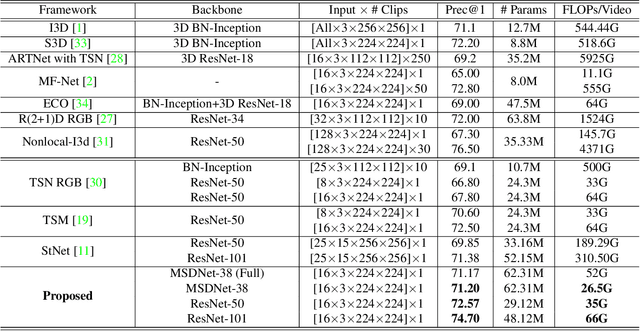
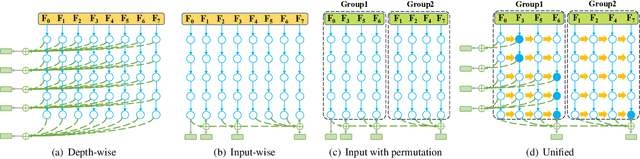
Though action recognition in videos has achieved great success recently, it remains a challenging task due to the massive computational cost. Designing lightweight networks is a possible solution, but it may degrade the recognition performance. In this paper, we innovatively propose a general dynamic inference idea to improve inference efficiency by leveraging the variation in the distinguishability of different videos. The dynamic inference approach can be achieved from aspects of the network depth and the number of input video frames, or even in a joint input-wise and network depth-wise manner. In a nutshell, we treat input frames and network depth of the computational graph as a 2-dimensional grid, and several checkpoints are placed on this grid in advance with a prediction module. The inference is carried out progressively on the grid by following some predefined route, whenever the inference process comes across a checkpoint, an early prediction can be made depending on whether the early stop criteria meets. For the proof-of-concept purpose, we instantiate three dynamic inference frameworks using two well-known backbone CNNs. In these instances, we overcome the drawback of limited temporal coverage resulted from an early prediction by a novel frame permutation scheme, and alleviate the conflict between progressive computation and video temporal relation modeling by introducing an online temporal shift module. Extensive experiments are conducted to thoroughly analyze the effectiveness of our ideas and to inspire future research efforts. Results on various datasets also evident the superiority of our approach.
Multi-Label Classification with Label Graph Superimposing
Nov 21, 2019
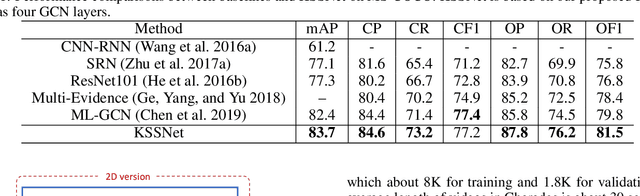
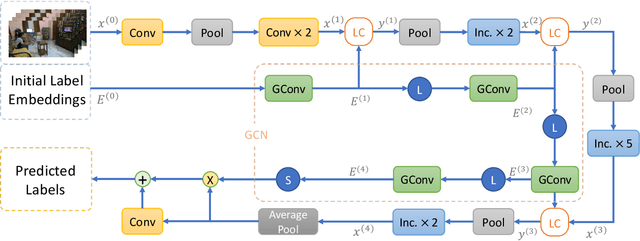

Images or videos always contain multiple objects or actions. Multi-label recognition has been witnessed to achieve pretty performance attribute to the rapid development of deep learning technologies. Recently, graph convolution network (GCN) is leveraged to boost the performance of multi-label recognition. However, what is the best way for label correlation modeling and how feature learning can be improved with label system awareness are still unclear. In this paper, we propose a label graph superimposing framework to improve the conventional GCN+CNN framework developed for multi-label recognition in the following two aspects. Firstly, we model the label correlations by superimposing label graph built from statistical co-occurrence information into the graph constructed from knowledge priors of labels, and then multi-layer graph convolutions are applied on the final superimposed graph for label embedding abstraction. Secondly, we propose to leverage embedding of the whole label system for better representation learning. In detail, lateral connections between GCN and CNN are added at shallow, middle and deep layers to inject information of label system into backbone CNN for label-awareness in the feature learning process. Extensive experiments are carried out on MS-COCO and Charades datasets, showing that our proposed solution can greatly improve the recognition performance and achieves new state-of-the-art recognition performance.
TruNet: Short Videos Generation from Long Videos via Story-Preserving Truncation
Oct 14, 2019
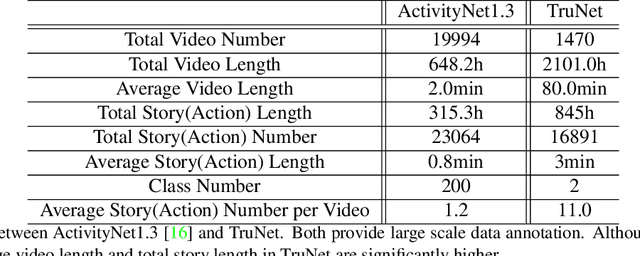
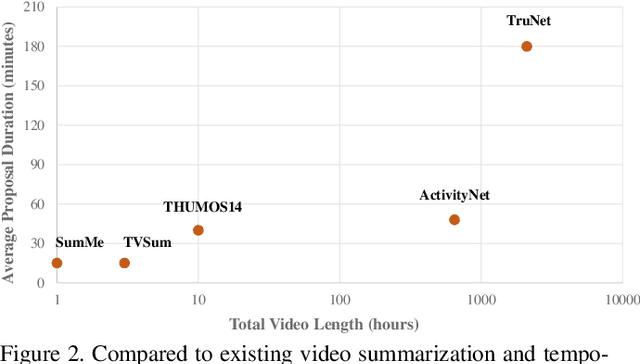
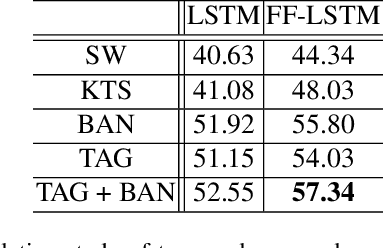
In this work, we introduce a new problem, named as {\em story-preserving long video truncation}, that requires an algorithm to automatically truncate a long-duration video into multiple short and attractive sub-videos with each one containing an unbroken story. This differs from traditional video highlight detection or video summarization problems in that each sub-video is required to maintain a coherent and integral story, which is becoming particularly important for resource-production video sharing platforms such as Youtube, Facebook, TikTok, Kwai, etc. To address the problem, we collect and annotate a new large video truncation dataset, named as TruNet, which contains 1470 videos with on average 11 short stories per video. With the new dataset, we further develop and train a neural architecture for video truncation that consists of two components: a Boundary Aware Network (BAN) and a Fast-Forward Long Short-Term Memory (FF-LSTM). We first use the BAN to generate high quality temporal proposals by jointly considering frame-level attractiveness and boundaryness. We then apply the FF-LSTM, which tends to capture high-order dependencies among a sequence of frames, to decide whether a temporal proposal is a coherent and integral story. We show that our proposed framework outperforms existing approaches for the story-preserving long video truncation problem in both quantitative measures and user-study. The dataset is available for public academic research usage at https://ai.baidu.com/broad/download.