 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
Sep 19, 2025Large language models are increasingly capable of handling long-context inputs, but the memory overhead of key-value (KV) cache remains a major bottleneck for general-purpose deployment. While various compression strategies have been explored, sequence-level compression, which drops the full KV caches for certain tokens, is particularly challenging as it can lead to the loss of important contextual information. To address this, we introduce UniGist, a sequence-level long-context compression framework that efficiently preserves context information by replacing raw tokens with special compression tokens (gists) in a fine-grained manner. We adopt a chunk-free training strategy and design an efficient kernel with a gist shift trick, enabling optimized GPU training. Our scheme also supports flexible inference by allowing the actual removal of compressed tokens, resulting in real-time memory savings. Experiments across multiple long-context tasks demonstrate that UniGist significantly improves compression quality, with especially strong performance in detail-recalling tasks and long-range dependency modeling.
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
Sep 16, 2025Large Language Models (LLMs) have recently advanced the field of Automated Theorem Proving (ATP), attaining substantial performance gains through widely adopted test-time scaling strategies, notably reflective Chain-of-Thought (CoT) reasoning and increased sampling passes. However, they both introduce significant computational overhead for inference. Moreover, existing cost analyses typically regulate only the number of sampling passes, while neglecting the substantial disparities in sampling costs introduced by different scaling strategies. In this paper, we systematically compare the efficiency of different test-time scaling strategies for ATP models and demonstrate the inefficiency of the current state-of-the-art (SOTA) open-source approaches. We then investigate approaches to significantly reduce token usage and sample passes while maintaining the original performance. Specifically, we propose two complementary methods that can be integrated into a unified EconRL pipeline for amplified benefits: (1) a dynamic Chain-of-Thought (CoT) switching mechanism designed to mitigate unnecessary token consumption, and (2) Diverse parallel-scaled reinforcement learning (RL) with trainable prefixes to enhance pass rates under constrained sampling passes. Experiments on miniF2F and ProofNet demonstrate that our EconProver achieves comparable performance to baseline methods with only 12% of the computational cost. This work provides actionable insights for deploying lightweight ATP models without sacrificing performance.
CDE: Curiosity-Driven Exploration for Efficient Reinforcement Learning in Large Language Models
Sep 11, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) is a powerful paradigm for enhancing the reasoning ability of Large Language Models (LLMs). Yet current RLVR methods often explore poorly, leading to premature convergence and entropy collapse. To address this challenge, we introduce Curiosity-Driven Exploration (CDE), a framework that leverages the model's own intrinsic sense of curiosity to guide exploration. We formalize curiosity with signals from both the actor and the critic: for the actor, we use perplexity over its generated response, and for the critic, we use the variance of value estimates from a multi-head architecture. Both signals serve as an exploration bonus within the RLVR framework to guide the model. Our theoretical analysis shows that the actor-wise bonus inherently penalizes overconfident errors and promotes diversity among correct responses; moreover, we connect the critic-wise bonus to the well-established count-based exploration bonus in RL. Empirically, our method achieves an approximate +3 point improvement over standard RLVR using GRPO/PPO on AIME benchmarks. Further analysis identifies a calibration collapse mechanism within RLVR, shedding light on common LLM failure modes.
Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
Sep 09, 2025Parallel thinking has emerged as a novel approach for enhancing the reasoning capabilities of large language models (LLMs) by exploring multiple reasoning paths concurrently. However, activating such capabilities through training remains challenging, as existing methods predominantly rely on supervised fine-tuning (SFT) over synthetic data, which encourages teacher-forced imitation rather than exploration and generalization. Different from them, we propose \textbf{Parallel-R1}, the first reinforcement learning (RL) framework that enables parallel thinking behaviors for complex real-world reasoning tasks. Our framework employs a progressive curriculum that explicitly addresses the cold-start problem in training parallel thinking with RL. We first use SFT on prompt-generated trajectories from easier tasks to instill the parallel thinking ability, then transition to RL to explore and generalize this skill on harder problems. Experiments on various math benchmarks, including MATH, AMC23, and AIME, show that Parallel-R1 successfully instills parallel thinking, leading to 8.4% accuracy improvements over the sequential thinking model trained directly on challenging tasks with RL. Further analysis reveals a clear shift in the model's thinking behavior: at an early stage, it uses parallel thinking as an exploration strategy, while in a later stage, it uses the same capability for multi-perspective verification. Most significantly, we validate parallel thinking as a \textbf{mid-training exploration scaffold}, where this temporary exploratory phase unlocks a higher performance ceiling after RL, yielding a 42.9% improvement over the baseline on AIME25. Our model, data, and code will be open-source at https://github.com/zhengkid/Parallel-R1.
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Aug 27, 2025



Vision-Language Models (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
Audio-Thinker: Guiding Audio Language Model When and How to Think via Reinforcement Learning
Aug 12, 2025Recent advancements in large language models, multimodal large language models, and large audio language models (LALMs) have significantly improved their reasoning capabilities through reinforcement learning with rule-based rewards. However, the explicit reasoning process has yet to show significant benefits for audio question answering, and effectively leveraging deep reasoning remains an open challenge, with LALMs still falling short of human-level auditory-language reasoning. To address these limitations, we propose Audio-Thinker, a reinforcement learning framework designed to enhance the reasoning capabilities of LALMs, with a focus on improving adaptability, consistency, and effectiveness. Our approach introduces an adaptive think accuracy reward, enabling the model to adjust its reasoning strategies based on task complexity dynamically. Furthermore, we incorporate an external reward model to evaluate the overall consistency and quality of the reasoning process, complemented by think-based rewards that help the model distinguish between valid and flawed reasoning paths during training. Experimental results demonstrate that our Audio-Thinker model outperforms existing reasoning-oriented LALMs across various benchmark tasks, exhibiting superior reasoning and generalization capabilities.
Towards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Aug 07, 2025
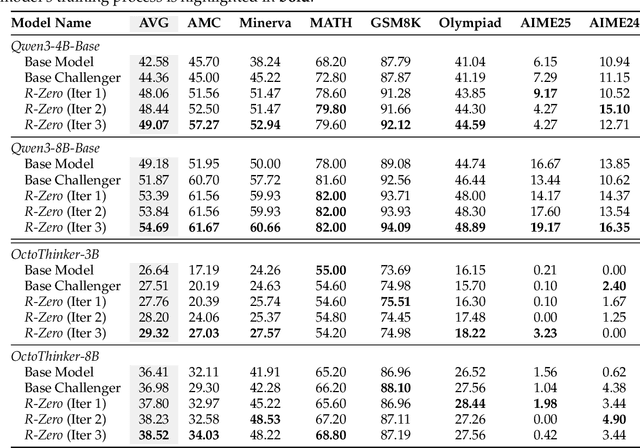

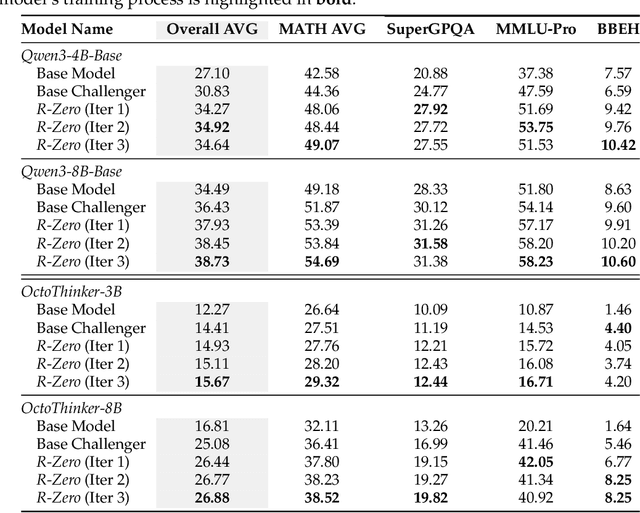
Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.
Efficient Scaling for LLM-based ASR
Aug 06, 2025



Large language model (LLM)-based automatic speech recognition (ASR) achieves strong performance but often incurs high computational costs. This work investigates how to obtain the best LLM-ASR performance efficiently. Through comprehensive and controlled experiments, we find that pretraining the speech encoder before integrating it with the LLM leads to significantly better scaling efficiency than the standard practice of joint post-training of LLM-ASR. Based on this insight, we propose a new multi-stage LLM-ASR training strategy, EFIN: Encoder First Integration. Among all training strategies evaluated, EFIN consistently delivers better performance (relative to 21.1% CERR) with significantly lower computation budgets (49.9% FLOPs). Furthermore, we derive a scaling law that approximates ASR error rates as a computation function, providing practical guidance for LLM-ASR scaling.