 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-DeepThinker: Progressive Reasoning-Aware Reinforcement Learning for High-Quality Chain-of-Thought Emergence in Audio Language Models
Apr 20, 2026Large Audio-Language Models (LALMs) have made significant progress in audio understanding, yet they primarily operate as perception-and-answer systems without explicit reasoning processes. Existing methods for enhancing audio reasoning rely either on supervised chain-of-thought (CoT) fine-tuning, which is limited by training data quality, or on reinforcement learning (RL) with coarse rewards that do not directly evaluate reasoning quality. As a result, the generated reasoning chains often appear well-structured yet lack specific acoustic grounding. We propose Audio-DeepThinker, a framework built on two core ideas. First, we introduce a hybrid reasoning similarity reward that directly supervises the quality of generated reasoning chains by combining an LLM evaluator assessing logical path alignment, key step coverage, and analytical depth with an embedding similarity component enforcing semantic alignment with reference reasoning chains. Second, we propose a progressive two-stage curriculum that enables high-quality CoT reasoning to emerge through pure RL exploration, without any supervised reasoning fine-tuning, from an instruction-tuned model that possesses no prior chain-of-thought capability. Stage 1 trains on foundational audio QA with the hybrid reward to foster basic reasoning patterns, while Stage 2 shifts to acoustically challenging boundary cases with an LLM-only reward for greater reasoning diversity. Audio-DeepThinker achieves state-of-the-art results on MMAR (74.0%), MMAU-test-mini (78.5%), and MMSU (77.26%), winning 1st Place in the Interspeech 2026 Audio Reasoning Challenge (Single Model Track). Interpretability analyses further reveal that RL training primarily reshapes upper-layer MoE gating mechanisms and that reasoning tokens crystallize progressively in the upper transformer layers, offering mechanistic insights into how audio reasoning emerges through exploration.
Covo-Audio Technical Report
Feb 10, 2026In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Audio-Thinker: Guiding Audio Language Model When and How to Think via Reinforcement Learning
Aug 12, 2025Recent advancements in large language models, multimodal large language models, and large audio language models (LALMs) have significantly improved their reasoning capabilities through reinforcement learning with rule-based rewards. However, the explicit reasoning process has yet to show significant benefits for audio question answering, and effectively leveraging deep reasoning remains an open challenge, with LALMs still falling short of human-level auditory-language reasoning. To address these limitations, we propose Audio-Thinker, a reinforcement learning framework designed to enhance the reasoning capabilities of LALMs, with a focus on improving adaptability, consistency, and effectiveness. Our approach introduces an adaptive think accuracy reward, enabling the model to adjust its reasoning strategies based on task complexity dynamically. Furthermore, we incorporate an external reward model to evaluate the overall consistency and quality of the reasoning process, complemented by think-based rewards that help the model distinguish between valid and flawed reasoning paths during training. Experimental results demonstrate that our Audio-Thinker model outperforms existing reasoning-oriented LALMs across various benchmark tasks, exhibiting superior reasoning and generalization capabilities.
Towards Open-set Camera 3D Object Detection
Jun 25, 2024



Traditional camera 3D object detectors are typically trained to recognize a predefined set of known object classes. In real-world scenarios, these detectors may encounter unknown objects outside the training categories and fail to identify them correctly. To address this gap, we present OS-Det3D (Open-set Camera 3D Object Detection), a two-stage training framework enhancing the ability of camera 3D detectors to identify both known and unknown objects. The framework involves our proposed 3D Object Discovery Network (ODN3D), which is specifically trained using geometric cues such as the location and scale of 3D boxes to discover general 3D objects. ODN3D is trained in a class-agnostic manner, and the provided 3D object region proposals inherently come with data noise. To boost accuracy in identifying unknown objects, we introduce a Joint Objectness Selection (JOS) module. JOS selects the pseudo ground truth for unknown objects from the 3D object region proposals of ODN3D by combining the ODN3D objectness and camera feature attention objectness. Experiments on the nuScenes and KITTI datasets demonstrate the effectiveness of our framework in enabling camera 3D detectors to successfully identify unknown objects while also improving their performance on known objects.
DSNet for Real-Time Driving Scene Semantic Segmentation
Dec 06, 2018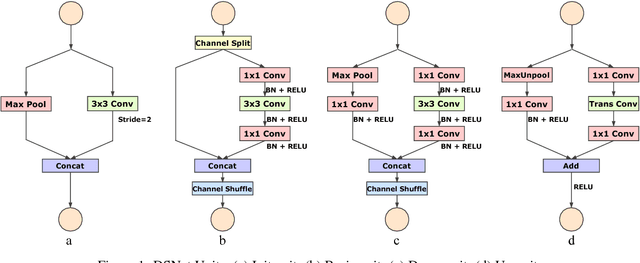
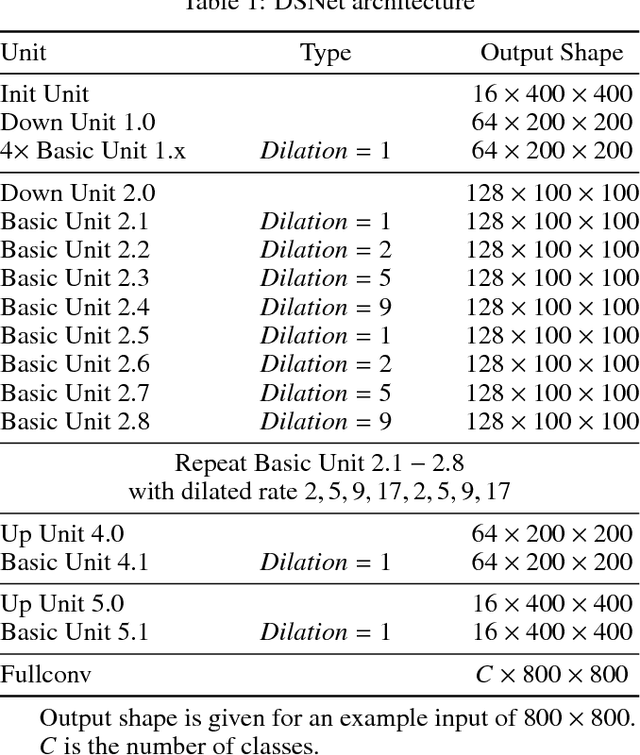
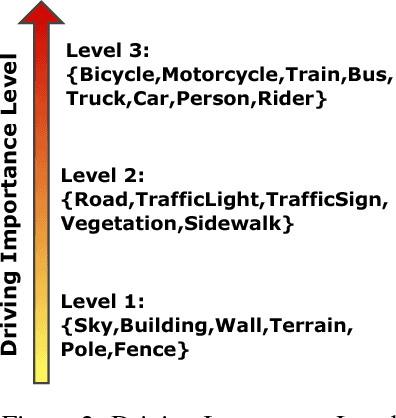
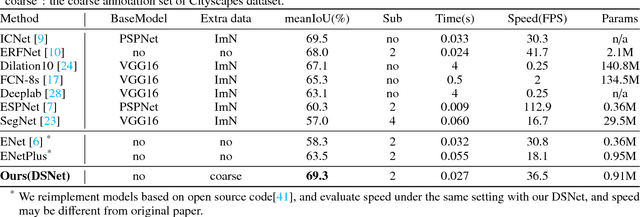
We focus on the very challenging task of semantic segmentation for autonomous driving system. It must deliver decent semantic segmentation result for traffic critical objects real-time. In this paper, we propose a very efficient yet powerful deep neural network for driving scene semantic segmentation termed as Driving Segmentation Network (DSNet). DSNet achieves state-of-the-art balance between accuracy and inference speed through efficient units and architecture design inspired by ShuffleNet V2 and ENet. More importantly, DSNet highlights classes most critical with driving decision making through our novel Driving Importance-weighted Loss. We evaluate DSNet on Cityscapes dataset, our DSNet achieves 71.8% mean Intersection-over-Union (IoU) on validation set and 69.3% on test set. Class-wise IoU scores show that Driving Importance-weighted Loss could improve most driving critical classes by a large margin. Compared with ENet, DSNet is 18.9% more accurate and 1.1+ times faster which implies great potential for autonomous driving application.
A Scoring Method for Driving Safety Credit Using Trajectory Data
Nov 28, 2018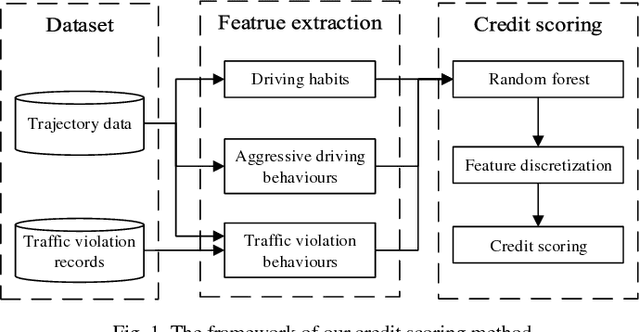
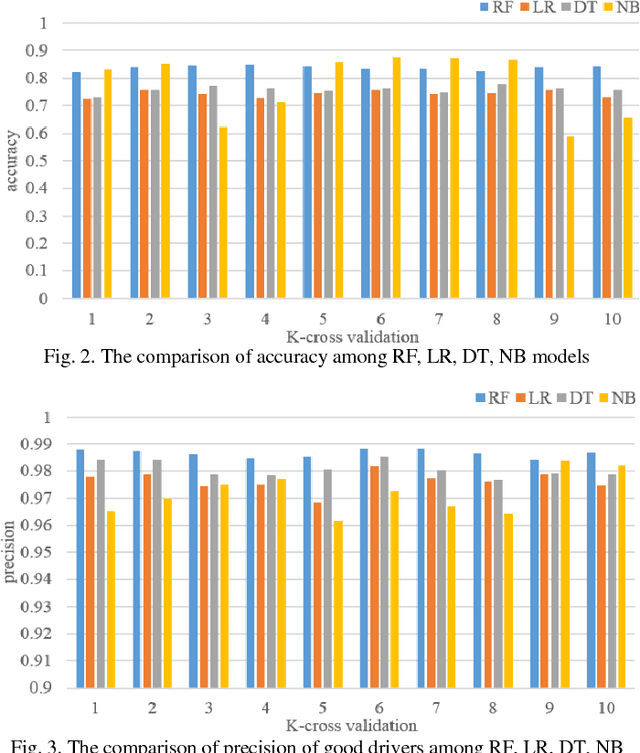
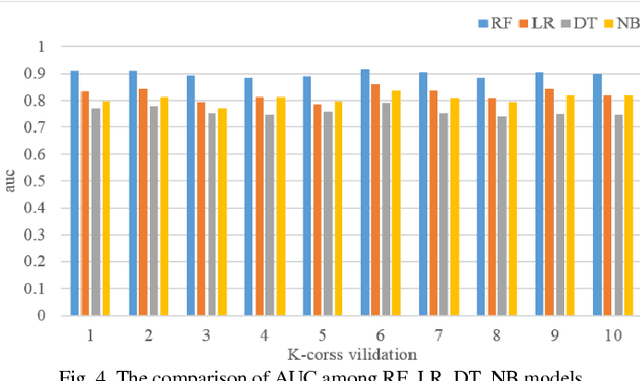
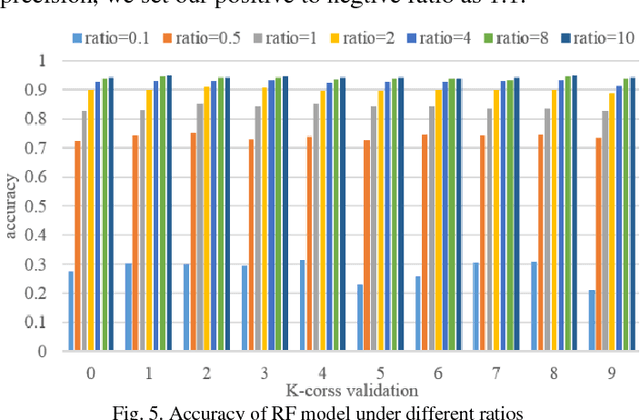
Urban traffic systems worldwide are suffering from severe traffic safety problems. Traffic safety is affected by many complex factors, and heavily related to all drivers' behaviors involved in traffic system. Drivers with aggressive driving behaviors increase the risk of traffic accidents. In order to manage the safety level of traffic system, we propose Driving Safety Credit inspired by credit score in financial security field, and design a scoring method using trajectory data and violation records. First, we extract driving habits, aggressive driving behaviors and traffic violation behaviors from driver's trajectories and traffic violation records. Next, we train a classification model to filtered out irrelevant features. And at last, we score each driver with selected features. We verify our proposed scoring method using 40 days of traffic simulation, and proves the effectiveness of our scoring method.