 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneric Event Boundary Detection Challenge at CVPR 2021 Technical Report: Cascaded Temporal Attention Network (CASTANET)
Jul 01, 2021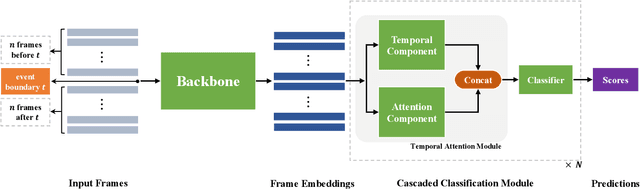
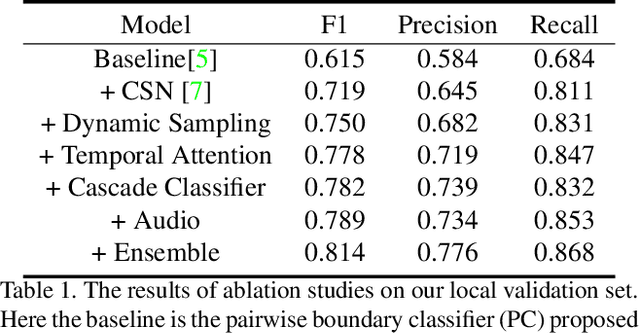
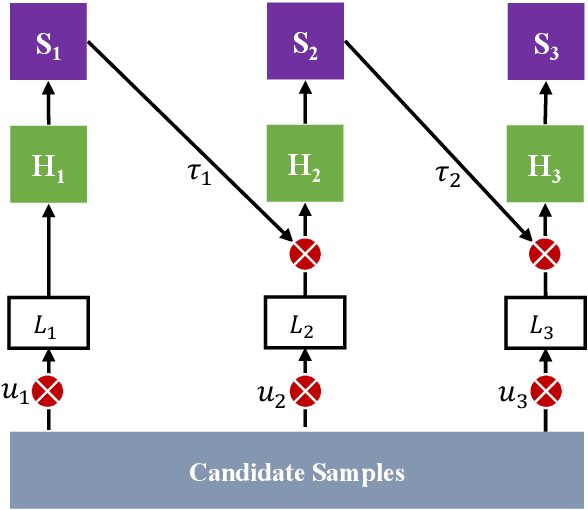
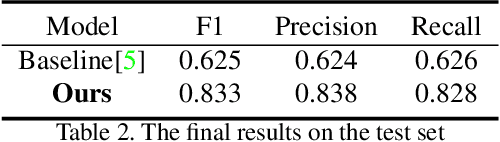
This report presents the approach used in the submission of Generic Event Boundary Detection (GEBD) Challenge at CVPR21. In this work, we design a Cascaded Temporal Attention Network (CASTANET) for GEBD, which is formed by three parts, the backbone network, the temporal attention module, and the classification module. Specifically, the Channel-Separated Convolutional Network (CSN) is used as the backbone network to extract features, and the temporal attention module is designed to enforce the network to focus on the discriminative features. After that, the cascaded architecture is used in the classification module to generate more accurate boundaries. In addition, the ensemble strategy is used to further improve the performance of the proposed method. The proposed method achieves 83.30% F1 score on Kinetics-GEBD test set, which improves 20.5% F1 score compared to the baseline method. Code is available at https://github.com/DexiangHong/Cascade-PC.
TNT: Target-driveN Trajectory Prediction
Aug 21, 2020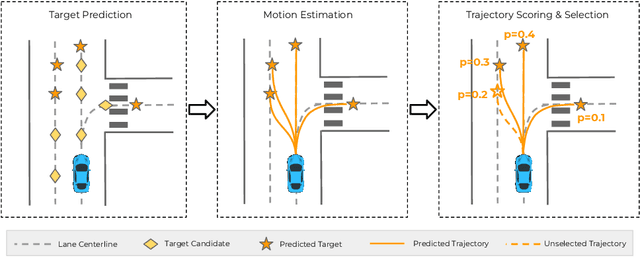
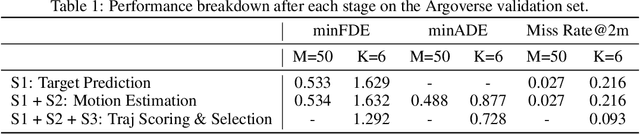
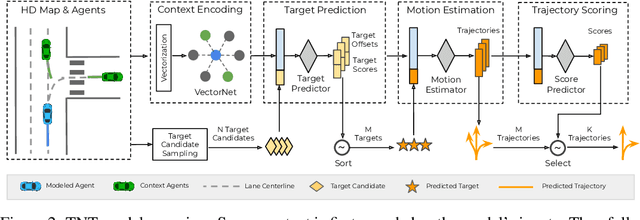
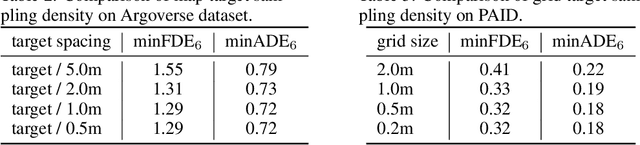
Predicting the future behavior of moving agents is essential for real world applications. It is challenging as the intent of the agent and the corresponding behavior is unknown and intrinsically multimodal. Our key insight is that for prediction within a moderate time horizon, the future modes can be effectively captured by a set of target states. This leads to our target-driven trajectory prediction (TNT) framework. TNT has three stages which are trained end-to-end. It first predicts an agent's potential target states $T$ steps into the future, by encoding its interactions with the environment and the other agents. TNT then generates trajectory state sequences conditioned on targets. A final stage estimates trajectory likelihoods and a final compact set of trajectory predictions is selected. This is in contrast to previous work which models agent intents as latent variables, and relies on test-time sampling to generate diverse trajectories. We benchmark TNT on trajectory prediction of vehicles and pedestrians, where we outperform state-of-the-art on Argoverse Forecasting, INTERACTION, Stanford Drone and an in-house Pedestrian-at-Intersection dataset.
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
May 08, 2020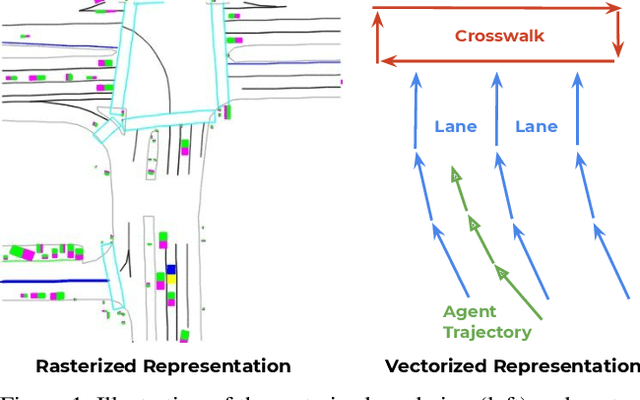
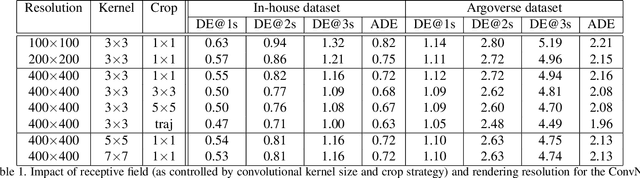
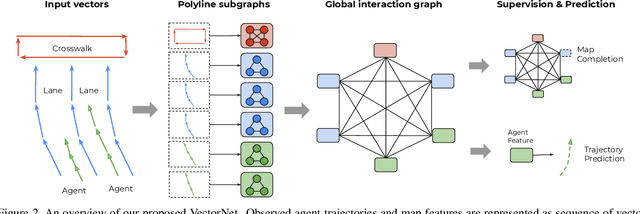
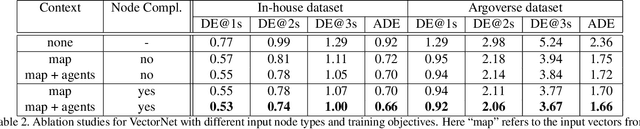
Behavior prediction in dynamic, multi-agent systems is an important problem in the context of self-driving cars, due to the complex representations and interactions of road components, including moving agents (e.g. pedestrians and vehicles) and road context information (e.g. lanes, traffic lights). This paper introduces VectorNet, a hierarchical graph neural network that first exploits the spatial locality of individual road components represented by vectors and then models the high-order interactions among all components. In contrast to most recent approaches, which render trajectories of moving agents and road context information as bird-eye images and encode them with convolutional neural networks (ConvNets), our approach operates on a vector representation. By operating on the vectorized high definition (HD) maps and agent trajectories, we avoid lossy rendering and computationally intensive ConvNet encoding steps. To further boost VectorNet's capability in learning context features, we propose a novel auxiliary task to recover the randomly masked out map entities and agent trajectories based on their context. We evaluate VectorNet on our in-house behavior prediction benchmark and the recently released Argoverse forecasting dataset. Our method achieves on par or better performance than the competitive rendering approach on both benchmarks while saving over 70% of the model parameters with an order of magnitude reduction in FLOPs. It also outperforms the state of the art on the Argoverse dataset.
STINet: Spatio-Temporal-Interactive Network for Pedestrian Detection and Trajectory Prediction
May 08, 2020

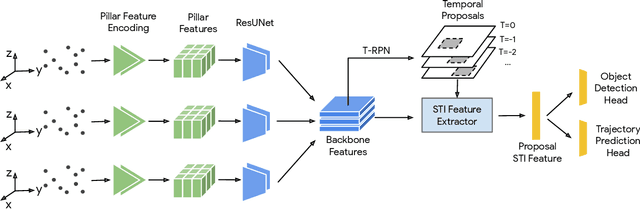
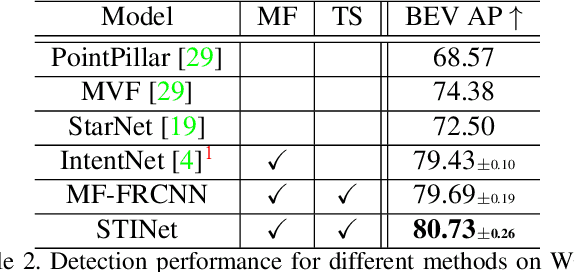
Detecting pedestrians and predicting future trajectories for them are critical tasks for numerous applications, such as autonomous driving. Previous methods either treat the detection and prediction as separate tasks or simply add a trajectory regression head on top of a detector. In this work, we present a novel end-to-end two-stage network: Spatio-Temporal-Interactive Network (STINet). In addition to 3D geometry modeling of pedestrians, we model the temporal information for each of the pedestrians. To do so, our method predicts both current and past locations in the first stage, so that each pedestrian can be linked across frames and the comprehensive spatio-temporal information can be captured in the second stage. Also, we model the interaction among objects with an interaction graph, to gather the information among the neighboring objects. Comprehensive experiments on the Lyft Dataset and the recently released large-scale Waymo Open Dataset for both object detection and future trajectory prediction validate the effectiveness of the proposed method. For the Waymo Open Dataset, we achieve a bird-eyes-view (BEV) detection AP of 80.73 and trajectory prediction average displacement error (ADE) of 33.67cm for pedestrians, which establish the state-of-the-art for both tasks.
Improving 3D Object Detection through Progressive Population Based Augmentation
Apr 02, 2020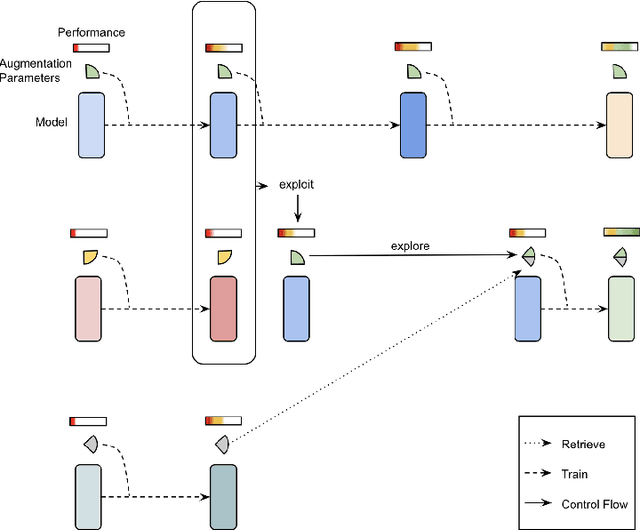
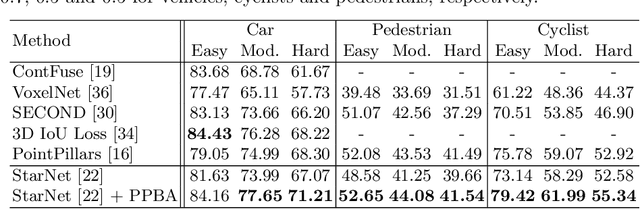

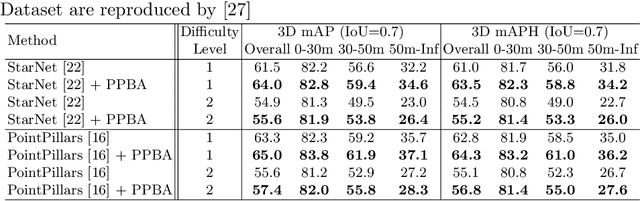
Data augmentation has been widely adopted for object detection in 3D point clouds. All previous efforts have focused on manually designing specific data augmentation methods for individual architectures, however no work has attempted to automate the design of data augmentation in 3D detection problems -- as is common in 2D image-based computer vision. In this work, we present the first attempt to automate the design of data augmentation policies for 3D object detection. We present an algorithm, termed Progressive Population Based Augmentation (PPBA). PPBA learns to optimize augmentation strategies by narrowing down the search space and adopting the best parameters discovered in previous iterations. On the KITTI test set, PPBA improves the StarNet detector by substantial margins on the moderate difficulty category of cars, pedestrians, and cyclists, outperforming all current state-of-the-art single-stage detection models. Additional experiments on the Waymo Open Dataset indicate that PPBA continues to effectively improve 3D object detection on a 20x larger dataset compared to KITTI. The magnitude of the improvements may be comparable to advances in 3D perception architectures and the gains come without an incurred cost at inference time. In subsequent experiments, we find that PPBA may be up to 10x more data efficient than baseline 3D detection models without augmentation, highlighting that 3D detection models may achieve competitive accuracy with far fewer labeled examples.
Spatial Attention Pyramid Network for Unsupervised Domain Adaptation
Mar 29, 2020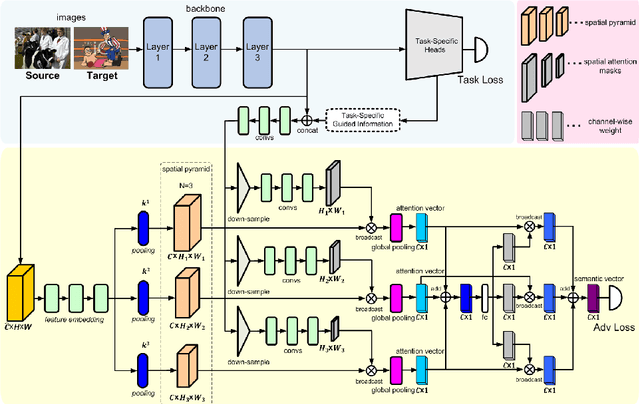
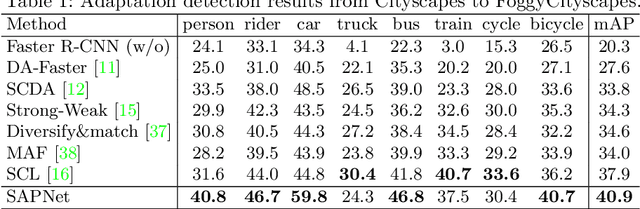
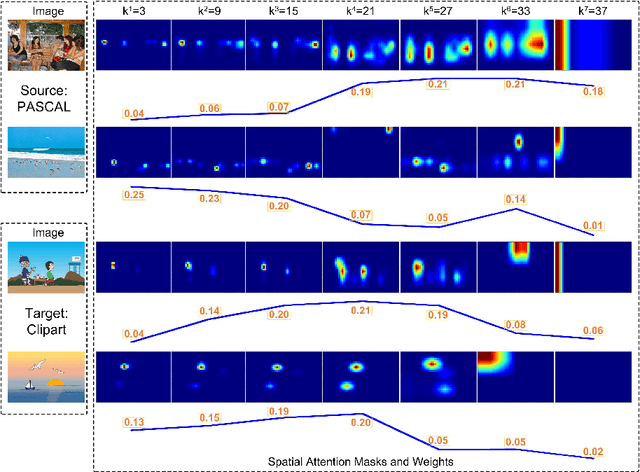
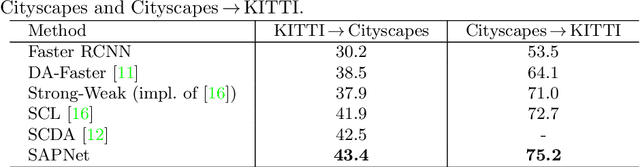
Unsupervised domain adaptation is critical in various computer vision tasks, such as object detection, instance segmentation, and semantic segmentation, which aims to alleviate performance degradation caused by domain-shift. Most of previous methods rely on a single-mode distribution of source and target domains to align them with adversarial learning, leading to inferior results in various scenarios. To that end, in this paper, we design a new spatial attention pyramid network for unsupervised domain adaptation. Specifically, we first build the spatial pyramid representation to capture context information of objects at different scales. Guided by the task-specific information, we combine the dense global structure representation and local texture patterns at each spatial location effectively using the spatial attention mechanism. In this way, the network is enforced to focus on the discriminative regions with context information for domain adaption. We conduct extensive experiments on various challenging datasets for unsupervised domain adaptation on object detection, instance segmentation, and semantic segmentation, which demonstrates that our method performs favorably against the state-of-the-art methods by a large margin. Our source code is available at code_path.
Preventing Information Leakage with Neural Architecture Search
Dec 18, 2019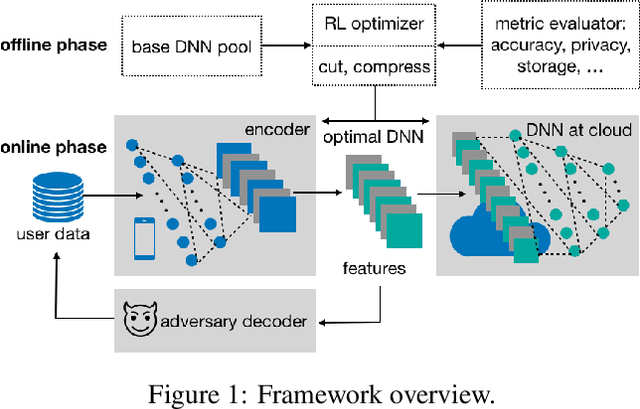
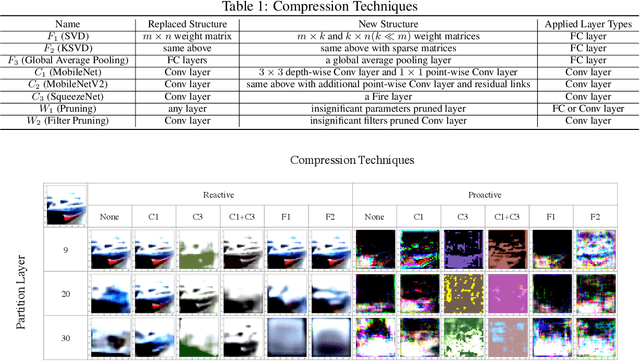
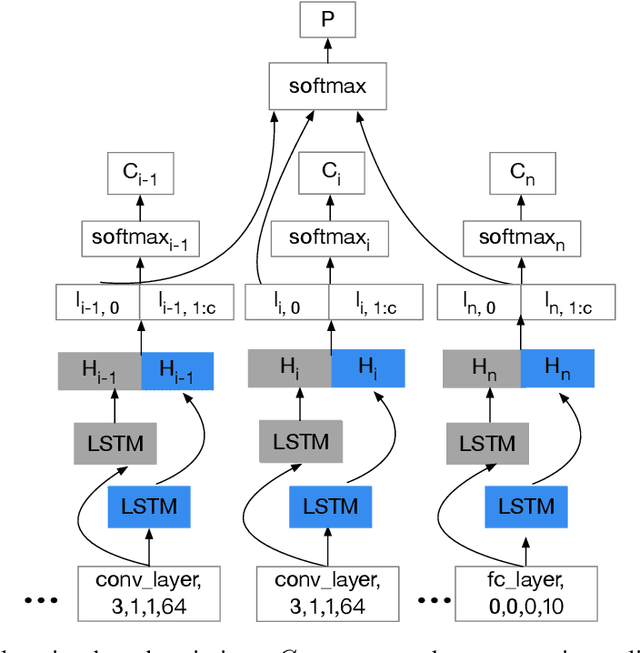
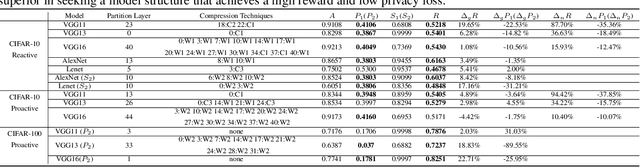
Powered by machine learning services in the cloud, numerous learning-driven mobile applications are gaining popularity in the market. As deep learning tasks are mostly computation-intensive, it has become a trend to process raw data on devices and send the neural network features to the cloud, whereas the part of the neural network residing in the cloud completes the task to return final results. However, there is always the potential for unexpected leakage with the release of features, with which an adversary could infer a significant amount of information about the original data. To address this problem, we propose a privacy-preserving deep learning framework on top of the mobile cloud infrastructure: the trained deep neural network is tailored to prevent information leakage through features while maintaining highly accurate results. In essence, we learn the strategy to prevent leakage by modifying the trained deep neural network against a generic opponent, who infers unintended information from released features and auxiliary data, while preserving the accuracy of the model as much as possible.
Data Priming Network for Automatic Check-Out
Apr 10, 2019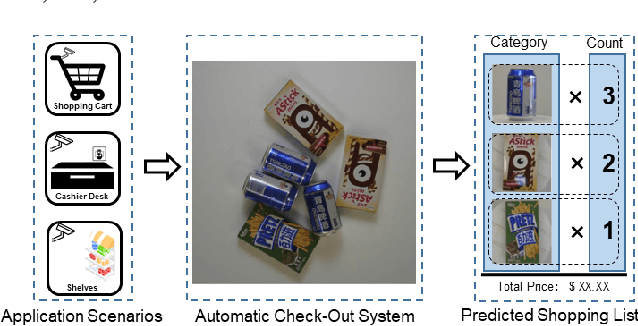
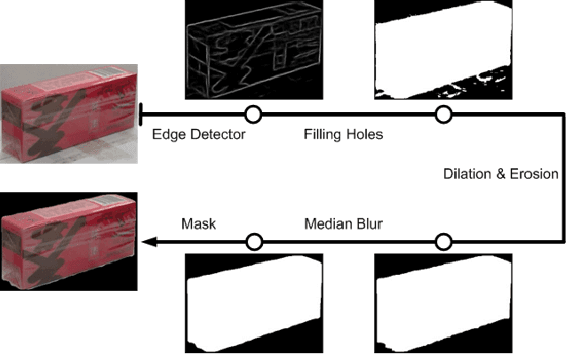

Automatic Check-Out (ACO) receives increased interests in recent years. An important component of the ACO system is the visual item counting, which recognize the categories and counts of the items chosen by the customers. However, the training of such a system is challenged by the domain adaptation problem, in which the training data are images from isolated items while the testing images are for collections of items. Existing methods solve this problem with data augmentation using synthesized images, but the image synthesis leads to unreal images that affect the training process. In this paper, we propose a new data priming method to solve the domain adaptation problem. Specifically, we first use pre-augmentation data priming, in which we remove distracting background from the training images and select images with realistic view angles by the pose pruning method. In the post-augmentation step, we train a data priming network using detection and counting collaborative learning, and select more reliable images from testing data to train the final visual item tallying network. Experiments on the large scale Retail Product Checkout (RPC) dataset demonstrate the superiority of the proposed method, i.e., we achieve 80.51% checkout accuracy compared with 56.68% of the baseline methods.
A probabilistic graphical model approach in 30 m land cover mapping with multiple data sources
Dec 11, 2016
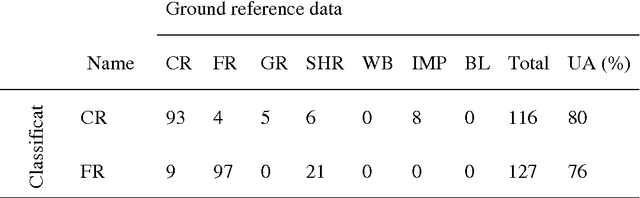
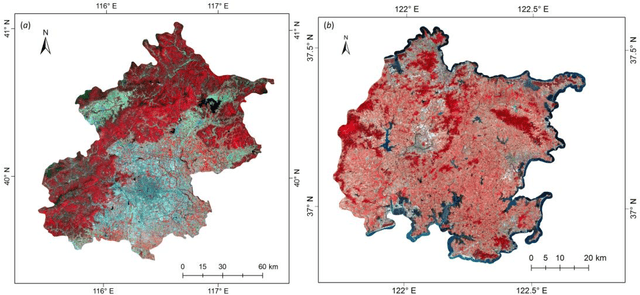
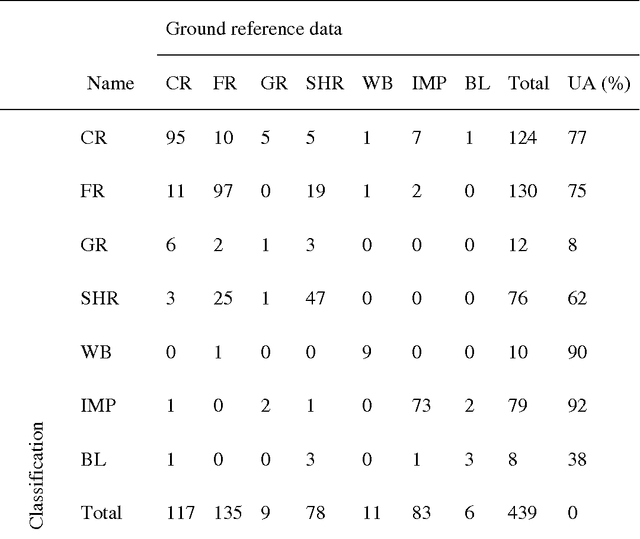
There is a trend to acquire high accuracy land-cover maps using multi-source classification methods, most of which are based on data fusion, especially pixel- or feature-level fusions. A probabilistic graphical model (PGM) approach is proposed in this research for 30 m resolution land-cover mapping with multi-temporal Landsat and MODerate Resolution Imaging Spectroradiometer (MODIS) data. Independent classifiers were applied to two single-date Landsat 8 scenes and the MODIS time-series data, respectively, for probability estimation. A PGM was created for each pixel in Landsat 8 data. Conditional probability distributions were computed based on data quality and reliability by using information selectively. Using the administrative territory of Beijing City (Area-1) and a coastal region of Shandong province, China (Area-2) as study areas, multiple land-cover maps were generated for comparison. Quantitative results show the effectiveness of the proposed method. Overall accuracies promoted from 74.0% (maps acquired from single-temporal Landsat images) to 81.8% (output of the PGM) for Area-1. Improvements can also be seen when using MODIS data and only a single-temporal Landsat image as input (overall accuracy: 78.4% versus 74.0% for Area-1, and 86.8% versus 83.0% for Area-2). Information from MODIS data did not help much when the PGM was applied to cloud free regions of. One of the advantages of the proposed method is that it can be applied where multi-temporal data cannot be simply stacked as a multi-layered image.
Towards Holistic Scene Understanding: Feedback Enabled Cascaded Classification Models
Oct 24, 2011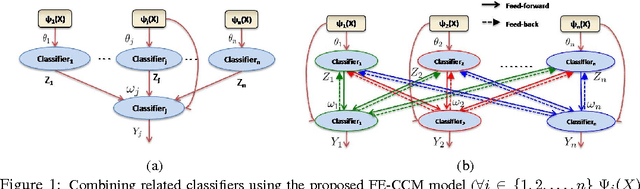
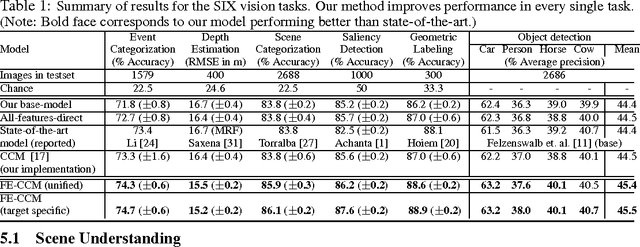

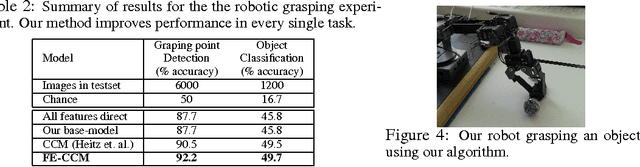
Scene understanding includes many related sub-tasks, such as scene categorization, depth estimation, object detection, etc. Each of these sub-tasks is often notoriously hard, and state-of-the-art classifiers already exist for many of them. These classifiers operate on the same raw image and provide correlated outputs. It is desirable to have an algorithm that can capture such correlation without requiring any changes to the inner workings of any classifier. We propose Feedback Enabled Cascaded Classification Models (FE-CCM), that jointly optimizes all the sub-tasks, while requiring only a `black-box' interface to the original classifier for each sub-task. We use a two-layer cascade of classifiers, which are repeated instantiations of the original ones, with the output of the first layer fed into the second layer as input. Our training method involves a feedback step that allows later classifiers to provide earlier classifiers information about which error modes to focus on. We show that our method significantly improves performance in all the sub-tasks in the domain of scene understanding, where we consider depth estimation, scene categorization, event categorization, object detection, geometric labeling and saliency detection. Our method also improves performance in two robotic applications: an object-grasping robot and an object-finding robot.