 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoXaRt: Audio-Visual Object-Guided Sound Interaction for XR
Mar 11, 2026In Extended Reality (XR), complex acoustic environments often overwhelm users, compromising both scene awareness and social engagement due to entangled sound sources. We introduce MoXaRt, a real-time XR system that uses audio-visual cues to separate these sources and enable fine-grained sound interaction. MoXaRt's core is a cascaded architecture that performs coarse, audio-only separation in parallel with visual detection of sources (e.g., faces, instruments). These visual anchors then guide refinement networks to isolate individual sources, separating complex mixes of up to 5 concurrent sources (e.g., 2 voices + 3 instruments) with ~2 second processing latency. We validate MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study. Empirical results indicate that our system significantly enhances speech intelligibility, yielding a 36.2% (p < 0.01) increase in listening comprehension within adversarial acoustic environments while substantially reducing cognitive load (p < 0.001), thereby paving the way for more perceptive and socially adept XR experiences.
Learned Monocular Depth Priors in Visual-Inertial Initialization
Apr 20, 2022
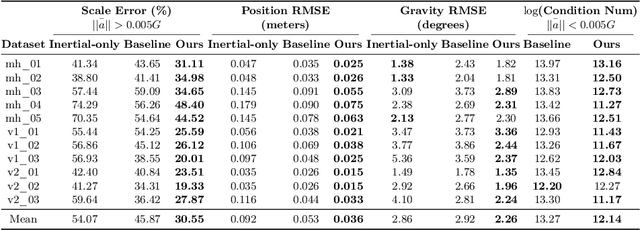
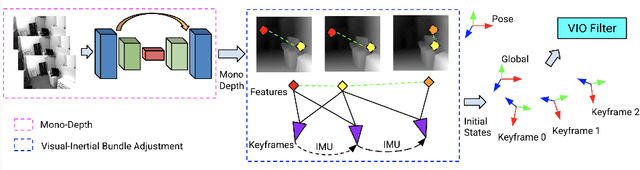
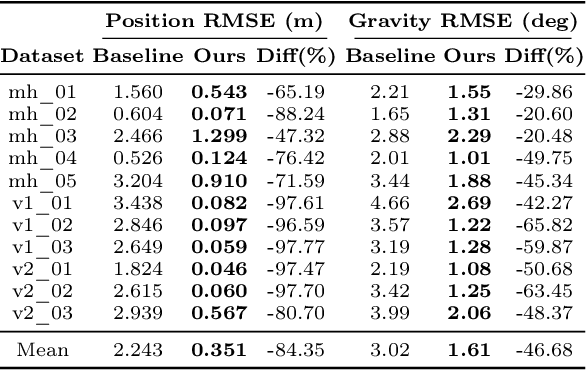
Visual-inertial odometry (VIO) is the pose estimation backbone for most AR/VR and autonomous robotic systems today, in both academia and industry. However, these systems are highly sensitive to the initialization of key parameters such as sensor biases, gravity direction, and metric scale. In practical scenarios where high-parallax or variable acceleration assumptions are rarely met (e.g. hovering aerial robot, smartphone AR user not gesticulating with phone), classical visual-inertial initialization formulations often become ill-conditioned and/or fail to meaningfully converge. In this paper we target visual-inertial initialization specifically for these low-excitation scenarios critical to in-the-wild usage. We propose to circumvent the limitations of classical visual-inertial structure-from-motion (SfM) initialization by incorporating a new learning-based measurement as a higher-level input. We leverage learned monocular depth images (mono-depth) to constrain the relative depth of features, and upgrade the mono-depth to metric scale by jointly optimizing for its scale and shift. Our experiments show a significant improvement in problem conditioning compared to a classical formulation for visual-inertial initialization, and demonstrate significant accuracy and robustness improvements relative to the state-of-the-art on public benchmarks, particularly under motion-restricted scenarios. We further extend this improvement to implementation within an existing odometry system to illustrate the impact of our improved initialization method on resulting tracking trajectories.
Multimodal active speaker detection and virtual cinematography for video conferencing
Feb 12, 2020
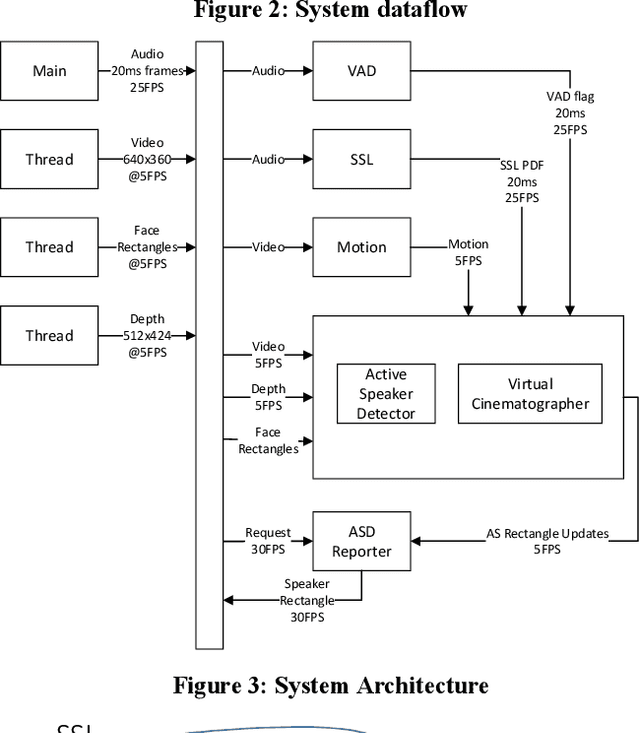
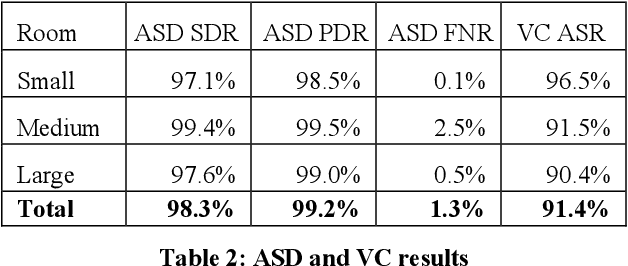
Active speaker detection (ASD) and virtual cinematography (VC) can significantly improve the remote user experience of a video conference by automatically panning, tilting and zooming of a video conferencing camera: users subjectively rate an expert video cinematographer's video significantly higher than unedited video. We describe a new automated ASD and VC that performs within 0.3 MOS of an expert cinematographer based on subjective ratings with a 1-5 scale. This system uses a 4K wide-FOV camera, a depth camera, and a microphone array; it extracts features from each modality and trains an ASD using an AdaBoost machine learning system that is very efficient and runs in real-time. A VC is similarly trained using machine learning to optimize the subjective quality of the overall experience. To avoid distracting the room participants and reduce switching latency the system has no moving parts -- the VC works by cropping and zooming the 4K wide-FOV video stream. The system was tuned and evaluated using extensive crowdsourcing techniques and evaluated on a dataset with N=100 meetings, each 2-5 minutes in length.
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018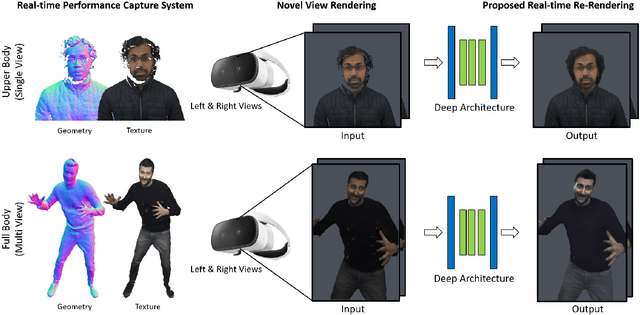



Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
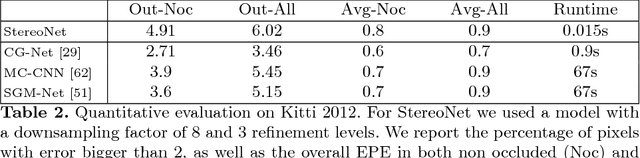
StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
Jul 24, 2018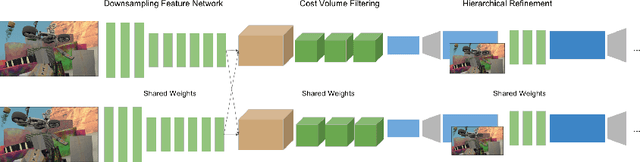
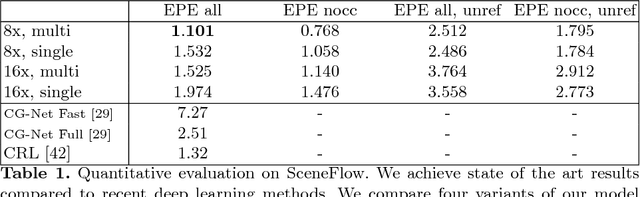
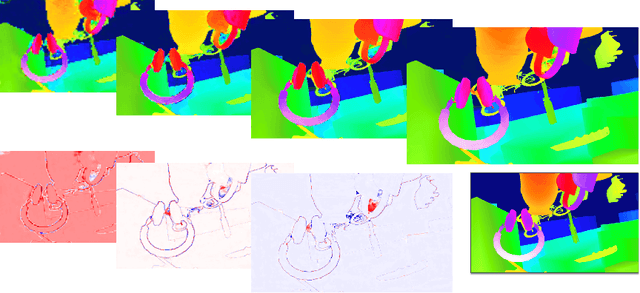
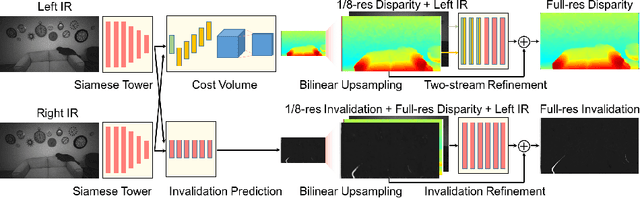
This paper presents StereoNet, the first end-to-end deep architecture for real-time stereo matching that runs at 60 fps on an NVidia Titan X, producing high-quality, edge-preserved, quantization-free disparity maps. A key insight of this paper is that the network achieves a sub-pixel matching precision than is a magnitude higher than those of traditional stereo matching approaches. This allows us to achieve real-time performance by using a very low resolution cost volume that encodes all the information needed to achieve high disparity precision. Spatial precision is achieved by employing a learned edge-aware upsampling function. Our model uses a Siamese network to extract features from the left and right image. A first estimate of the disparity is computed in a very low resolution cost volume, then hierarchically the model re-introduces high-frequency details through a learned upsampling function that uses compact pixel-to-pixel refinement networks. Leveraging color input as a guide, this function is capable of producing high-quality edge-aware output. We achieve compelling results on multiple benchmarks, showing how the proposed method offers extreme flexibility at an acceptable computational budget.
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems
Jul 16, 2018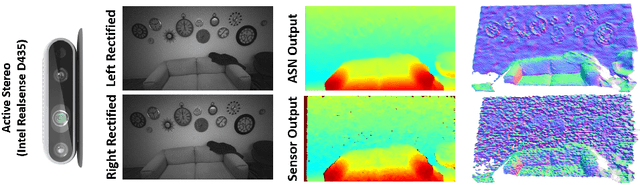

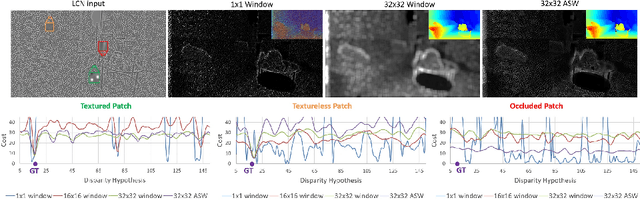
In this paper we present ActiveStereoNet, the first deep learning solution for active stereo systems. Due to the lack of ground truth, our method is fully self-supervised, yet it produces precise depth with a subpixel precision of $1/30th$ of a pixel; it does not suffer from the common over-smoothing issues; it preserves the edges; and it explicitly handles occlusions. We introduce a novel reconstruction loss that is more robust to noise and texture-less patches, and is invariant to illumination changes. The proposed loss is optimized using a window-based cost aggregation with an adaptive support weight scheme. This cost aggregation is edge-preserving and smooths the loss function, which is key to allow the network to reach compelling results. Finally we show how the task of predicting invalid regions, such as occlusions, can be trained end-to-end without ground-truth. This component is crucial to reduce blur and particularly improves predictions along depth discontinuities. Extensive quantitatively and qualitatively evaluations on real and synthetic data demonstrate state of the art results in many challenging scenes.
Towards Holistic Scene Understanding: Feedback Enabled Cascaded Classification Models
Oct 24, 2011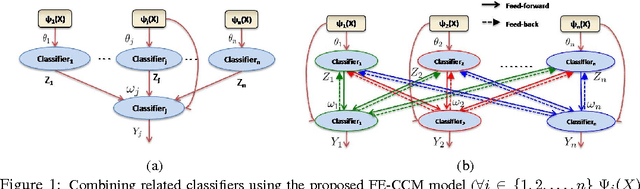
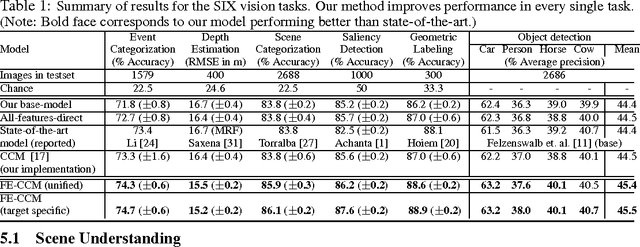

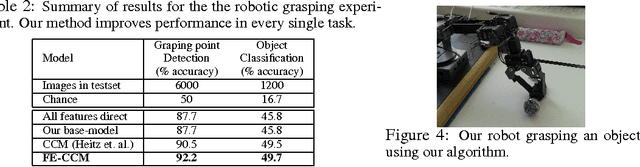
Scene understanding includes many related sub-tasks, such as scene categorization, depth estimation, object detection, etc. Each of these sub-tasks is often notoriously hard, and state-of-the-art classifiers already exist for many of them. These classifiers operate on the same raw image and provide correlated outputs. It is desirable to have an algorithm that can capture such correlation without requiring any changes to the inner workings of any classifier. We propose Feedback Enabled Cascaded Classification Models (FE-CCM), that jointly optimizes all the sub-tasks, while requiring only a `black-box' interface to the original classifier for each sub-task. We use a two-layer cascade of classifiers, which are repeated instantiations of the original ones, with the output of the first layer fed into the second layer as input. Our training method involves a feedback step that allows later classifiers to provide earlier classifiers information about which error modes to focus on. We show that our method significantly improves performance in all the sub-tasks in the domain of scene understanding, where we consider depth estimation, scene categorization, event categorization, object detection, geometric labeling and saliency detection. Our method also improves performance in two robotic applications: an object-grasping robot and an object-finding robot.