 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypergraph Enterprise Agentic Reasoner over Heterogeneous Business Systems
May 14, 2026Applying Large Language Models (LLMs) to heterogeneous enterprise systems is hindered by hallucinations and failures in multi-hop, n-ary reasoning. Existing paradigms (e.g., GraphRAG, NL2SQL) lack the semantic grounding and auditable execution required for these complex environments. We introduce HEAR, an enterprise agentic reasoner built on a Stratified Hypergraph Ontology. Its base Graph Layer virtualizes provenance-aware data interfaces, while the Hyperedge Layer encodes n-ary business rules and procedural protocols. Operating an evidence-driven reasoning loop, HEAR dynamically orchestrates ontology tools for structured multi-hop analysis without requiring LLM retraining. Evaluations on supply-chain tasks, including order fulfillment blockage root cause analysis (RCA), show HEAR achieves up to 94.7% accuracy. Crucially, HEAR demonstrates adaptive efficiency: utilizing procedural hyperedges to minimize token costs, while leveraging topological exploration for rigorous correctness on complex queries. By matching proprietary model performance with open-weight backbones and automating manual diagnostics, HEAR establishes a scalable, auditable foundation for enterprise intelligence.
Spectral-Geometric Neural Fields for Pose-Free LiDAR View Synthesis
Mar 13, 2026Neural Radiance Fields (NeRF) have shown remarkable success in image novel view synthesis (NVS), inspiring extensions to LiDAR NVS. However, most methods heavily rely on accurate camera poses for scene reconstruction. The sparsity and textureless nature of LiDAR data also present distinct challenges, leading to geometric holes and discontinuous surfaces. To address these issues, we propose SG-NLF, a pose-free LiDAR NeRF framework that integrates spectral information with geometric consistency. Specifically, we design a hybrid representation based on spectral priors to reconstruct smooth geometry. For pose optimization, we construct a confidence-aware graph based on feature compatibility to achieve global alignment. In addition, an adversarial learning strategy is introduced to enforce cross-frame consistency, thereby enhancing reconstruction quality. Comprehensive experiments demonstrate the effectiveness of our framework, especially in challenging low-frequency scenarios. Compared to previous state-of-the-art methods, SG-NLF improves reconstruction quality and pose accuracy by over 35.8% and 68.8%. Our work can provide a novel perspective for LiDAR view synthesis.
Dual-Horizon Hybrid Internal Model for Low-Gravity Quadrupedal Jumping with Hardware-in-the-Loop Validation
Mar 09, 2026Locomotion under reduced gravity is commonly realized through jumping, yet continuous pronking in lunar gravity remains challenging due to prolonged flight phases and sparse ground contact. The extended aerial duration increases landing impact sensitivity and makes stable attitude regulation over rough planetary terrain difficult. Existing approaches primarily address single jumps on flat surfaces and lack both continuous-terrain solutions and realistic hardware validation. This work presents a Dual-Horizon Hybrid Internal Model for continuous quadrupedal jumping under lunar gravity using proprioceptive sensing only. Two temporal encoders capture complementary time scales: a short-horizon branch models rapid vertical dynamics with explicit vertical velocity estimation, while a long-horizon branch models horizontal motion trends and center-of-mass height evolution across the jump cycle. The fused representation enables stable and continuous jumping under extended aerial phases characteristic of lunar gravity. To provide hardware-in-the-loop validation, we develop the MATRIX (Mixed-reality Adaptive Testbed for Robotic Integrated eXploration) platform, a digital-twin-driven system that offloads gravity through a pulley-counterweight mechanism and maps Unreal Engine lunar terrain to a motion platform and treadmill in real time. Using MATRIX, we demonstrate continuous jumping of a quadruped robot under lunar-gravity emulation across cratered lunar-like terrain.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Conjugate Relation Modeling for Few-Shot Knowledge Graph Completion
Oct 26, 2025Few-shot Knowledge Graph Completion (FKGC) infers missing triples from limited support samples, tackling long-tail distribution challenges. Existing methods, however, struggle to capture complex relational patterns and mitigate data sparsity. To address these challenges, we propose a novel FKGC framework for conjugate relation modeling (CR-FKGC). Specifically, it employs a neighborhood aggregation encoder to integrate higher-order neighbor information, a conjugate relation learner combining an implicit conditional diffusion relation module with a stable relation module to capture stable semantics and uncertainty offsets, and a manifold conjugate decoder for efficient evaluation and inference of missing triples in manifold space. Experiments on three benchmarks demonstrate that our method achieves superior performance over state-of-the-art methods.
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025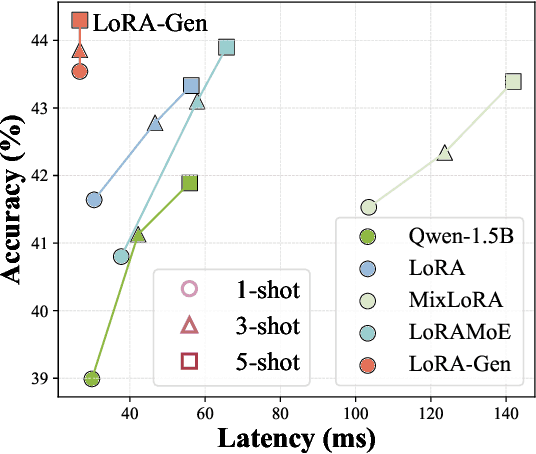

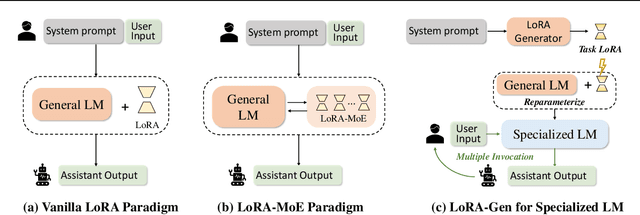
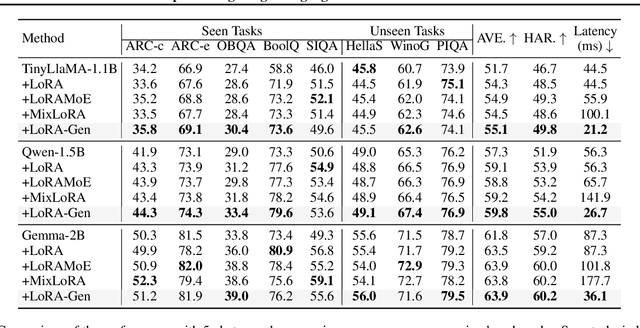
Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.
CogMath: Assessing LLMs' Authentic Mathematical Ability from a Human Cognitive Perspective
Jun 04, 2025Although large language models (LLMs) show promise in solving complex mathematical tasks, existing evaluation paradigms rely solely on a coarse measure of overall answer accuracy, which are insufficient for assessing their authentic capabilities. In this paper, we propose \textbf{CogMath}, which comprehensively assesses LLMs' mathematical abilities through the lens of human cognition. Specifically, inspired by psychological theories, CogMath formalizes human reasoning process into 3 stages: \emph{problem comprehension}, \emph{problem solving}, and \emph{solution summarization}. Within these stages, we investigate perspectives such as numerical calculation, knowledge, and counterfactuals, and design a total of 9 fine-grained evaluation dimensions. In each dimension, we develop an ``\emph{Inquiry}-\emph{Judge}-\emph{Reference}'' multi-agent system to generate inquiries that assess LLMs' mastery from this dimension. An LLM is considered to truly master a problem only when excelling in all inquiries from the 9 dimensions. By applying CogMath on three benchmarks, we reveal that the mathematical capabilities of 7 mainstream LLMs are overestimated by 30\%-40\%. Moreover, we locate their strengths and weaknesses across specific stages/dimensions, offering in-depth insights to further enhance their reasoning abilities.
Towards Foundation Model on Temporal Knowledge Graph Reasoning
Jun 04, 2025Temporal Knowledge Graphs (TKGs) store temporal facts with quadruple formats (s, p, o, t). Existing Temporal Knowledge Graph Embedding (TKGE) models perform link prediction tasks in transductive or semi-inductive settings, which means the entities, relations, and temporal information in the test graph are fully or partially observed during training. Such reliance on seen elements during inference limits the models' ability to transfer to new domains and generalize to real-world scenarios. A central limitation is the difficulty in learning representations for entities, relations, and timestamps that are transferable and not tied to dataset-specific vocabularies. To overcome these limitations, we introduce the first fully-inductive approach to temporal knowledge graph link prediction. Our model employs sinusoidal positional encodings to capture fine-grained temporal patterns and generates adaptive entity and relation representations using message passing conditioned on both local and global temporal contexts. Our model design is agnostic to temporal granularity and time span, effectively addressing temporal discrepancies across TKGs and facilitating time-aware structural information transfer. As a pretrained, scalable, and transferable model, POSTRA demonstrates strong zero-shot performance on unseen temporal knowledge graphs, effectively generalizing to novel entities, relations, and timestamps. Extensive theoretical analysis and empirical results show that a single pretrained model can improve zero-shot performance on various inductive temporal reasoning scenarios, marking a significant step toward a foundation model for temporal KGs.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
TensorAR: Refinement is All You Need in Autoregressive Image Generation
May 22, 2025



Autoregressive (AR) image generators offer a language-model-friendly approach to image generation by predicting discrete image tokens in a causal sequence. However, unlike diffusion models, AR models lack a mechanism to refine previous predictions, limiting their generation quality. In this paper, we introduce TensorAR, a new AR paradigm that reformulates image generation from next-token prediction to next-tensor prediction. By generating overlapping windows of image patches (tensors) in a sliding fashion, TensorAR enables iterative refinement of previously generated content. To prevent information leakage during training, we propose a discrete tensor noising scheme, which perturbs input tokens via codebook-indexed noise. TensorAR is implemented as a plug-and-play module compatible with existing AR models. Extensive experiments on LlamaGEN, Open-MAGVIT2, and RAR demonstrate that TensorAR significantly improves the generation performance of autoregressive models.