 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDen-1K: A Density Field Dataset of Real-World Objects
Dec 11, 2025A deep understanding of the physical world is a central goal for embodied AI and realistic simulation. While current models excel at capturing an object's surface geometry and appearance, they largely neglect its internal physical properties. This omission is critical, as properties like volumetric density are fundamental for predicting an object's center of mass, stability, and interaction dynamics in applications ranging from robotic manipulation to physical simulation. The primary bottleneck has been the absence of large-scale, real-world data. To bridge this gap, we introduce XDen-1K, the first large-scale, multi-modal dataset designed for real-world physical property estimation, with a particular focus on volumetric density. The core of this dataset consists of 1,000 real-world objects across 148 categories, for which we provide comprehensive multi-modal data, including a high-resolution 3D geometric model with part-level annotations and a corresponding set of real-world biplanar X-ray scans. Building upon this data, we introduce a novel optimization framework that recovers a high-fidelity volumetric density field of each object from its sparse X-ray views. To demonstrate its practical value, we add X-ray images as a conditioning signal to an existing segmentation network and perform volumetric segmentation. Furthermore, we conduct experiments on downstream robotics tasks. The results show that leveraging the dataset can effectively improve the accuracy of center-of-mass estimation and the success rate of robotic manipulation. We believe XDen-1K will serve as a foundational resource and a challenging new benchmark, catalyzing future research in physically grounded visual inference and embodied AI.
CogMath: Assessing LLMs' Authentic Mathematical Ability from a Human Cognitive Perspective
Jun 04, 2025Although large language models (LLMs) show promise in solving complex mathematical tasks, existing evaluation paradigms rely solely on a coarse measure of overall answer accuracy, which are insufficient for assessing their authentic capabilities. In this paper, we propose \textbf{CogMath}, which comprehensively assesses LLMs' mathematical abilities through the lens of human cognition. Specifically, inspired by psychological theories, CogMath formalizes human reasoning process into 3 stages: \emph{problem comprehension}, \emph{problem solving}, and \emph{solution summarization}. Within these stages, we investigate perspectives such as numerical calculation, knowledge, and counterfactuals, and design a total of 9 fine-grained evaluation dimensions. In each dimension, we develop an ``\emph{Inquiry}-\emph{Judge}-\emph{Reference}'' multi-agent system to generate inquiries that assess LLMs' mastery from this dimension. An LLM is considered to truly master a problem only when excelling in all inquiries from the 9 dimensions. By applying CogMath on three benchmarks, we reveal that the mathematical capabilities of 7 mainstream LLMs are overestimated by 30\%-40\%. Moreover, we locate their strengths and weaknesses across specific stages/dimensions, offering in-depth insights to further enhance their reasoning abilities.
Learning to Solve Geometry Problems via Simulating Human Dual-Reasoning Process
May 10, 2024



Geometry Problem Solving (GPS), which is a classic and challenging math problem, has attracted much attention in recent years. It requires a solver to comprehensively understand both text and diagram, master essential geometry knowledge, and appropriately apply it in reasoning. However, existing works follow a paradigm of neural machine translation and only focus on enhancing the capability of encoders, which neglects the essential characteristics of human geometry reasoning. In this paper, inspired by dual-process theory, we propose a Dual-Reasoning Geometry Solver (DualGeoSolver) to simulate the dual-reasoning process of humans for GPS. Specifically, we construct two systems in DualGeoSolver, namely Knowledge System and Inference System. Knowledge System controls an implicit reasoning process, which is responsible for providing diagram information and geometry knowledge according to a step-wise reasoning goal generated by Inference System. Inference System conducts an explicit reasoning process, which specifies the goal in each reasoning step and applies the knowledge to generate program tokens for resolving it. The two systems carry out the above process iteratively, which behaves more in line with human cognition. We conduct extensive experiments on two benchmark datasets, GeoQA and GeoQA+. The results demonstrate the superiority of DualGeoSolver in both solving accuracy and robustness from explicitly modeling human reasoning process and knowledge application.
Experience-Learning Inspired Two-Step Reward Method for Efficient Legged Locomotion Learning Towards Natural and Robust Gaits
Jan 22, 2024



Multi-legged robots offer enhanced stability in complex terrains, yet autonomously learning natural and robust motions in such environments remains challenging. Drawing inspiration from animals' progressive learning patterns, from simple to complex tasks, we introduce a universal two-stage learning framework with two-step reward setting based on self-acquired experience, which efficiently enables legged robots to incrementally learn natural and robust movements. In the first stage, robots learn through gait-related rewards to track velocity on flat terrain, acquiring natural, robust movements and generating effective motion experience data. In the second stage, mirroring animal learning from existing experiences, robots learn to navigate challenging terrains with natural and robust movements using adversarial imitation learning. To demonstrate our method's efficacy, we trained both quadruped robots and a hexapod robot, and the policy were successfully transferred to a physical quadruped robot GO1, which exhibited natural gait patterns and remarkable robustness in various terrains.
Learning Multiple Gaits within Latent Space for Quadruped Robots
Aug 06, 2023



Learning multiple gaits is non-trivial for legged robots, especially when encountering different terrains and velocity commands. In this work, we present an end-to-end training framework for learning multiple gaits for quadruped robots, tailored to the needs of robust locomotion, agile locomotion, and user's commands. A latent space is constructed concurrently by a gait encoder and a gait generator, which helps the agent to reuse multiple gait skills to achieve adaptive gait behaviors. To learn natural behaviors for multiple gaits, we design gait-dependent rewards that are constructed explicitly from gait parameters and implicitly from conditional adversarial motion priors (CAMP). We demonstrate such multiple gaits control on a quadruped robot Go1 with only proprioceptive sensors.
A Novel Approach for Auto-Formulation of Optimization Problems
Feb 09, 2023



In the Natural Language for Optimization (NL4Opt) NeurIPS 2022 competition, competitors focus on improving the accessibility and usability of optimization solvers, with the aim of subtask 1: recognizing the semantic entities that correspond to the components of the optimization problem; subtask 2: generating formulations for the optimization problem. In this paper, we present the solution of our team. First, we treat subtask 1 as a named entity recognition (NER) problem with the solution pipeline including pre-processing methods, adversarial training, post-processing methods and ensemble learning. Besides, we treat subtask 2 as a generation problem with the solution pipeline including specially designed prompts, adversarial training, post-processing methods and ensemble learning. Our proposed methods have achieved the F1-score of 0.931 in subtask 1 and the accuracy of 0.867 in subtask 2, which won the fourth and third places respectively in this competition. Our code is available at https://github.com/bigdata-ustc/nl4opt.
FedSemi: An Adaptive Federated Semi-Supervised Learning Framework
Dec 06, 2020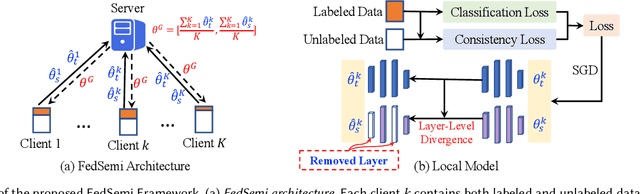
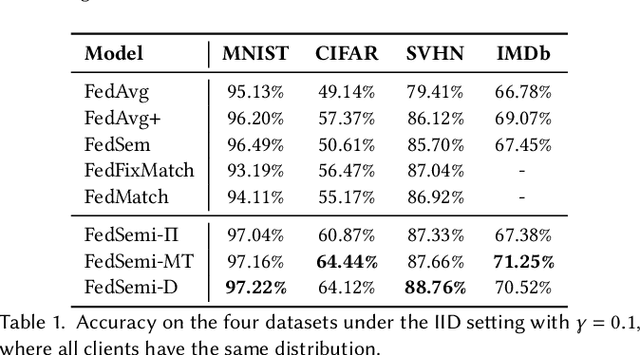
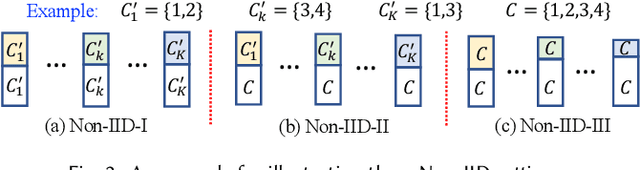
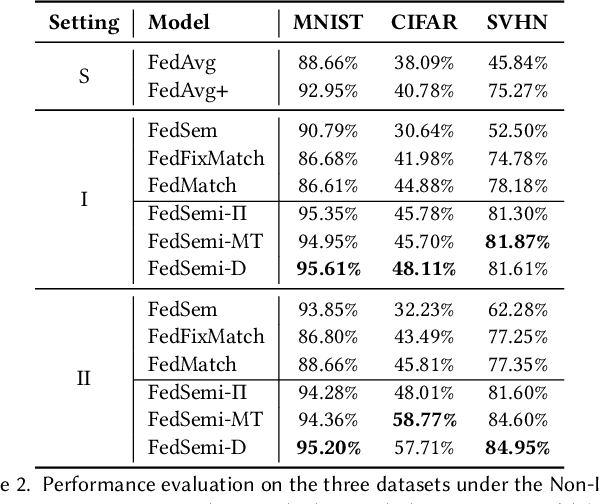
Federated learning (FL) has emerged as an effective technique to co-training machine learning models without actually sharing data and leaking privacy. However, most existing FL methods focus on the supervised setting and ignore the utilization of unlabeled data. Although there are a few existing studies trying to incorporate unlabeled data into FL, they all fail to maintain performance guarantees or generalization ability in various settings. In this paper, we tackle the federated semi-supervised learning problem from the insight of data regularization and analyze the new-raised difficulties. We propose FedSemi, a novel, adaptive, and general framework, which firstly introduces the consistency regularization into FL using a teacher-student model. We further propose a new metric to measure the divergence of local model layers. Based on the divergence, FedSemi can automatically select layer-level parameters to be uploaded to the server in an adaptive manner. Through extensive experimental validation of our method in four datasets, we show that our method achieves performance gain under the IID setting and three Non-IID settings compared to state-of-the-art baselines.