 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconDrive: Fast Feed-Forward 4D Gaussian Splatting for Autonomous Driving Scene Reconstruction
Mar 08, 2026High-fidelity visual reconstruction and novel-view synthesis are essential for realistic closed-loop evaluation in autonomous driving. While 4D Gaussian Splatting (4DGS) offers a promising balance of accuracy and efficiency, existing per-scene optimization methods require costly iterative refinement, rendering them unscalable for extensive urban environments. Conversely, current feed-forward approaches often suffer from degraded photometric quality. To address these limitations, we propose ReconDrive, a feed-forward framework that leverages and extends the 3D foundation model VGGT for rapid, high-fidelity 4DGS generation. Our architecture introduces two core adaptations to tailor the foundation model to dynamic driving scenes: (1) Hybrid Gaussian Prediction Heads, which decouple the regression of spatial coordinates and appearance attributes to overcome the photometric deficiencies inherent in generalized foundation features; and (2) a Static-Dynamic 4D Composition strategy that explicitly captures temporal motion via velocity modeling to represent complex dynamic environments. Benchmarked on nuScenes, ReconDrive significantly outperforms existing feed-forward baselines in reconstruction, novel-view synthesis, and 3D perception. It achieves performance competitive with per-scene optimization while being orders of magnitude faster, providing a scalable and practical solution for realistic driving simulation.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
AD-AGENT: A Multi-agent Framework for End-to-end Anomaly Detection
May 19, 2025



Anomaly detection (AD) is essential in areas such as fraud detection, network monitoring, and scientific research. However, the diversity of data modalities and the increasing number of specialized AD libraries pose challenges for non-expert users who lack in-depth library-specific knowledge and advanced programming skills. To tackle this, we present AD-AGENT, an LLM-driven multi-agent framework that turns natural-language instructions into fully executable AD pipelines. AD-AGENT coordinates specialized agents for intent parsing, data preparation, library and model selection, documentation mining, and iterative code generation and debugging. Using a shared short-term workspace and a long-term cache, the agents integrate popular AD libraries like PyOD, PyGOD, and TSLib into a unified workflow. Experiments demonstrate that AD-AGENT produces reliable scripts and recommends competitive models across libraries. The system is open-sourced to support further research and practical applications in AD.
When Human Pose Estimation Meets Robustness: Adversarial Algorithms and Benchmarks
May 13, 2021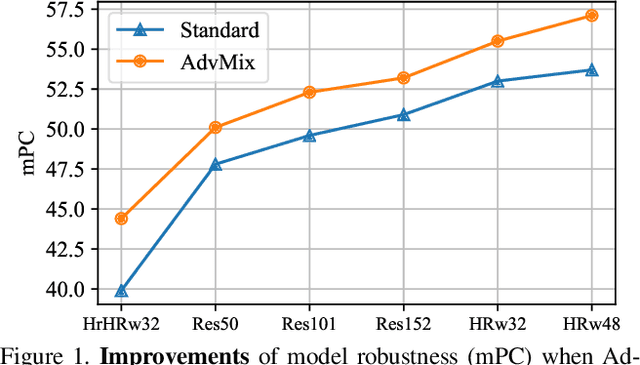

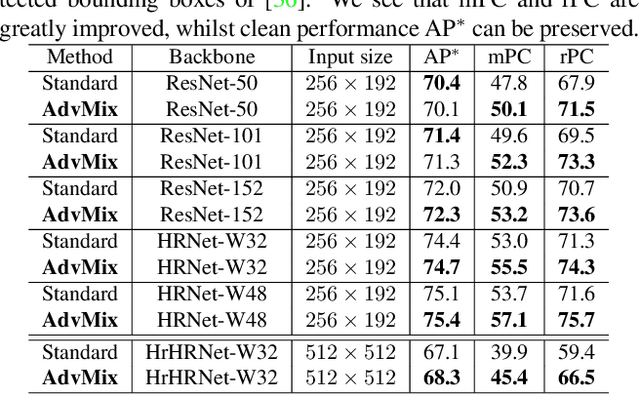
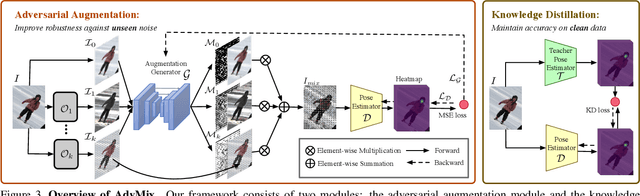
Human pose estimation is a fundamental yet challenging task in computer vision, which aims at localizing human anatomical keypoints. However, unlike human vision that is robust to various data corruptions such as blur and pixelation, current pose estimators are easily confused by these corruptions. This work comprehensively studies and addresses this problem by building rigorous robust benchmarks, termed COCO-C, MPII-C, and OCHuman-C, to evaluate the weaknesses of current advanced pose estimators, and a new algorithm termed AdvMix is proposed to improve their robustness in different corruptions. Our work has several unique benefits. (1) AdvMix is model-agnostic and capable in a wide-spectrum of pose estimation models. (2) AdvMix consists of adversarial augmentation and knowledge distillation. Adversarial augmentation contains two neural network modules that are trained jointly and competitively in an adversarial manner, where a generator network mixes different corrupted images to confuse a pose estimator, improving the robustness of the pose estimator by learning from harder samples. To compensate for the noise patterns by adversarial augmentation, knowledge distillation is applied to transfer clean pose structure knowledge to the target pose estimator. (3) Extensive experiments show that AdvMix significantly increases the robustness of pose estimations across a wide range of corruptions, while maintaining accuracy on clean data in various challenging benchmark datasets.
Down to the Last Detail: Virtual Try-on with Detail Carving
Jan 03, 2020
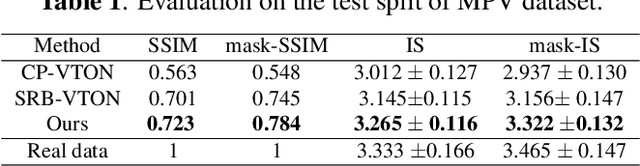
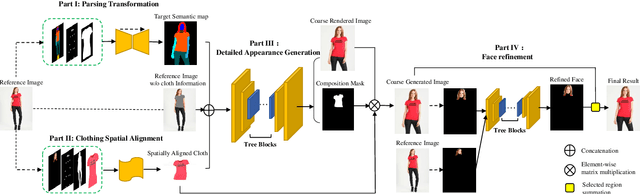
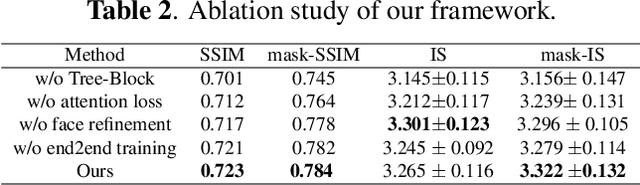
Virtual try-on under arbitrary poses has attracted lots of research attention due to its huge potential applications. However, existing methods can hardly preserve the details in clothing texture and facial identity (face, hair) while fitting novel clothes and poses onto a person. In this paper, we propose a novel multi-stage framework to synthesize person images, where rich details in salient regions can be well preserved. Specifically, a multi-stage framework is proposed to decompose the generation into spatial alignment followed by a coarse-to-fine generation. To better preserve the details in salient areas such as clothing and facial areas, we propose a Tree-Block (tree dilated fusion block) to harness multi-scale features in the generator networks. With end-to-end training of multiple stages, the whole framework can be jointly optimized for results with significantly better visual fidelity and richer details. Extensive experiments on standard datasets demonstrate that our proposed framework achieves the state-of-the-art performance, especially in preserving the visual details in clothing texture and facial identity. Our implementation will be publicly available soon.