 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sim-to-Real Gap of Foundation Model Agents: A Unified MDP Perspective
Jun 05, 2026Foundation model agents are increasingly deployed for real-world decision-making, but suffer from the sim-to-real gap. While robotics and classical control have mature frameworks to address this gap, the foundation model community is treating agent robustness as an entirely novel phenomenon. Our paper proposes formalizing the foundation model agent evaluation and training gap as a classical sim-to-real problem structured entirely around the four elements of a Markov Decision Process, including Observation, Action, Transition, and Reward. In this paper, we set a comprehensive research agenda that translates classical discrepancies into the foundation model domain and advocates for adopting established solutions like domain randomization. We provide concrete examples, such as a multilingual tool calling to demonstrate how severe observation space gaps lead to operationally invalid actions despite correct semantic intent. Ultimately, this agenda aims to drive a paradigm shift, yielding a unified vocabulary and standardized stress test benchmarks to foster a new generation of highly trustworthy agents for reliable real-world applications.
GEO-Bench: Benchmarking Ranking Manipulation in Generative Engine Optimization
May 27, 2026Large language models (LLMs) increasingly rank products, documents, and recommendations for user queries, which makes manipulating these rankings a growing concern for fairness and information integrity. Research on generative engine optimization (GEO) has produced many manipulation methods, but each is evaluated on its own dataset with its own metrics, so their relative strength and detectability stay unclear. We present GEO-Bench, a benchmark that evaluates GEO ranking-manipulation attacks under one protocol. It unifies black-box prompt-based attacks (TAP, Zero-Shot), white-box gradient-based attacks (STS, RAF, StealthRank), and ten white-hat C-SEO strategies. We score every method on five datasets against a fixed open-weight ranker (Llama-3.1-8B-Instruct), using metrics for both effectiveness (NRG, Success@α, Promote@α) and stealth (keyword violation rate, perplexity ratio). Our evaluation shows that effectiveness and stealth trade off across adversarial attacks, that black-box content rewriting matches or exceeds gradient-based attacks on rank promotion while producing more fluent text and can evade both keyword- and perplexity-based detection on some domains, and that the access model does not predict attack strength. By standardizing datasets, attack implementations, and metrics, GEO-Bench enables the first direct comparison across these attack paradigms and supports the development of detection methods.
When Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents
May 12, 2026Tool-use language agents are evaluated on benchmarks that assume clean inputs, unambiguous tool registries, and reliable APIs. Real deployments violate all these assumptions: user typos propagate into hallucinated tool names, a misconfigured request timeout can stall an agent indefinitely, and duplicate tool names across servers can freeze an SDK. We study these failures as a sim-to-real gap in the tool-use partially observable Markov decision process (POMDP), where deployment noise enters through the observation, action space, reward-relevant metadata, or transition dynamics. We introduce RobustBench-TC, a benchmark with 22 perturbation types organized by these four POMDP components, each grounded in a verified GitHub issue or documented tool-calling failure. Across 21 models from 1.5B to 32B parameters (including the closed-source o4-mini), the robustness profile is sharply uneven: observation perturbations reduce accuracy by less than 5%, while reward-relevant and transition perturbations reduce accuracy by roughly 40% and 30%, respectively; scale alone does not close these gaps. We then propose ToolRL-DR, a domain-randomization reinforcement learning (RL) recipe that trains a tool-use agent on perturbation-augmented trajectories spanning the three statically encodable POMDP components. On a 3B backbone, ToolRL-DR-Full retains roughly three-quarters of clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini. It closes approximately 27% of the Transition gap despite never seeing transition perturbations in training, suggesting that RL on adversarial static tool-use inputs induces a more persistent retry policy that transfers to unseen runtime failures. The dataset, code and benchmark leaderboard are publicly available.
Counterfactual Trace Auditing of LLM Agent Skills
May 12, 2026Large Language Model agents are increasingly augmented with agent skills. Current evaluation methods for skills remain limited. Most deployed benchmarks report only pass rate before and after a skill is attached, treating the skill as a black box change to agent behavior. We introduce Counterfactual Trace Auditing (CTA), a framework for measuring how a skill changes agent behavior. CTA pairs each with skill agent trace with a without skill counterpart on the same task, segments both traces into goal directed phases, aligns the phases, and emits structured Skill Influence Pattern (SIP) annotations. These annotations describe the behavioral effect of a skill rather than only its task outcome. We instantiate CTA on SWE-Skills-Bench with Claude across 49 software engineering tasks. The resulting audit reveals a clear evaluation gap. Pass rate changes by only +0.3 percentage points on average, suggesting little aggregate effect. Yet CTA identifies 522 SIP instances across the same paired traces, showing that the skills substantially reshape agent behavior even when pass rate is nearly unchanged. The audit also separates several recurring effects that pass rate cannot detect, including literal template copying, off task artifact creation, excess planning, and task recovery. Three findings emerge. First, high baseline tasks contain most of the observed skill effects, although their pass rate is already saturated and therefore cannot reflect those effects. Second, tasks with moderate baseline performance show the most recoverable gain, but often at substantially higher token cost. Third, the dominant SIP type can be identified by baseline bucket: surface anchoring is most common on ceiling tasks and edge-case prompting is most common on mid-range and floor tasks. These regularities turn informal failure mode observations into reproducible behavioral measurements.
FORTIS: Benchmarking Over-Privilege in Agent Skills
May 09, 2026Large language model agents increasingly operate through an intermediate skill layer that mediates between user intent and concrete task execution. This layer is widely treated as an organizational abstraction, but we argue it is also a privilege boundary that current models routinely exceed. We present \textbf{FORTIS}, a benchmark that evaluates over-privilege in agent skills across two stages: whether a model selects the minimally sufficient skill from a large overlapping library, and whether it executes that skill without expanding into broader tools or actions than the skill permits. Across ten frontier models and three domains, we find that over-privileged behavior is the norm rather than the exception. Models consistently reach for higher-privilege skills and tools than the task requires, failing at both stages at rates that remain high even for the strongest available models. Failure is especially severe under the ordinary conditions of real user interaction: incomplete specification, convenience framing, and proximity to skill boundaries. None of these requires adversarial construction. The results indicate that the skill layer, far from containing agent behavior, is itself a primary source of privilege escalation in current systems.
Do Vision Language Models Understand Human Engagement in Games?
Mar 19, 2026Inferring human engagement from gameplay video is important for game design and player-experience research, yet it remains unclear whether vision--language models (VLMs) can infer such latent psychological states from visual cues alone. Using the GameVibe Few-Shot dataset across nine first-person shooter games, we evaluate three VLMs under six prompting strategies, including zero-shot prediction, theory-guided prompts grounded in Flow, GameFlow, Self-Determination Theory, and MDA, and retrieval-augmented prompting. We consider both pointwise engagement prediction and pairwise prediction of engagement change between consecutive windows. Results show that zero-shot VLM predictions are generally weak and often fail to outperform simple per-game majority-class baselines. Memory- or retrieval-augmented prompting improves pointwise prediction in some settings, whereas pairwise prediction remains consistently difficult across strategies. Theory-guided prompting alone does not reliably help and can instead reinforce surface-level shortcuts. These findings suggest a perception--understanding gap in current VLMs: although they can recognize visible gameplay cues, they still struggle to robustly infer human engagement across games.
Fairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
Jan 20, 2026Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.
Multimodal Generative Engine Optimization: Rank Manipulation for Vision-Language Model Rankers
Jan 18, 2026Vision-Language Models (VLMs) are rapidly replacing unimodal encoders in modern retrieval and recommendation systems. While their capabilities are well-documented, their robustness against adversarial manipulation in competitive ranking scenarios remains largely unexplored. In this paper, we uncover a critical vulnerability in VLM-based product search: multimodal ranking attacks. We present Multimodal Generative Engine Optimization (MGEO), a novel adversarial framework that enables a malicious actor to unfairly promote a target product by jointly optimizing imperceptible image perturbations and fluent textual suffixes. Unlike existing attacks that treat modalities in isolation, MGEO employs an alternating gradient-based optimization strategy to exploit the deep cross-modal coupling within the VLM. Extensive experiments on real-world datasets using state-of-the-art models demonstrate that our coordinated attack significantly outperforms text-only and image-only baselines. These findings reveal that multimodal synergy, typically a strength of VLMs, can be weaponized to compromise the integrity of search rankings without triggering conventional content filters.
Value-Action Alignment in Large Language Models under Privacy-Prosocial Conflict
Jan 07, 2026Large language models (LLMs) are increasingly used to simulate decision-making tasks involving personal data sharing, where privacy concerns and prosocial motivations can push choices in opposite directions. Existing evaluations often measure privacy-related attitudes or sharing intentions in isolation, which makes it difficult to determine whether a model's expressed values jointly predict its downstream data-sharing actions as in real human behaviors. We introduce a context-based assessment protocol that sequentially administers standardized questionnaires for privacy attitudes, prosocialness, and acceptance of data sharing within a bounded, history-carrying session. To evaluate value-action alignments under competing attitudes, we use multi-group structural equation modeling (MGSEM) to identify relations from privacy concerns and prosocialness to data sharing. We propose Value-Action Alignment Rate (VAAR), a human-referenced directional agreement metric that aggregates path-level evidence for expected signs. Across multiple LLMs, we observe stable but model-specific Privacy-PSA-AoDS profiles, and substantial heterogeneity in value-action alignment.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
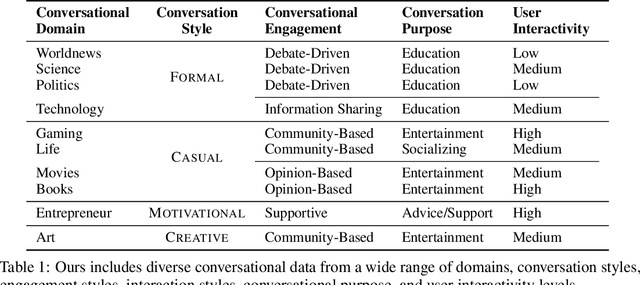


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.