 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Large Language Models on Quantum Optimization Problems for Circuit Generation
Apr 15, 2025Large language models (LLM) have achieved remarkable outcomes in addressing complex problems, including math, coding, and analyzing large amounts of scientific reports. Yet few works have explored the potential of LLM in quantum computing. The most challenging problem is how to leverage LLMs to automatically generate quantum circuits at a large scale. In this paper, we address such a challenge by fine-tuning LLMs and injecting the domain-specific knowledge of quantum computing. In particular, we investigate the mechanisms to generate training data sets and construct the end-to-end pipeline to fine-tune pre-trained LLMs that produce parameterized quantum circuits for optimization problems. We have prepared 14,000 quantum circuits covering a substantial part of the quantum optimization landscape: 12 optimization problem instances and their optimized QAOA, VQE, and adaptive VQE circuits. The fine-tuned LLMs can construct syntactically correct parametrized quantum circuits in the most recent OpenQASM 3.0. We have evaluated the quality of the parameters by comparing them to the optimized expectation values and distributions. Our evaluation shows that the fine-tuned LLM outperforms state-of-the-art models and that the parameters are better than random. The LLM-generated parametrized circuits and initial parameters can be used as a starting point for further optimization, \emph{e.g.,} templates in quantum machine learning and the benchmark for compilers and hardware.
Domain Generalization for Face Anti-spoofing via Content-aware Composite Prompt Engineering
Apr 06, 2025The challenge of Domain Generalization (DG) in Face Anti-Spoofing (FAS) is the significant interference of domain-specific signals on subtle spoofing clues. Recently, some CLIP-based algorithms have been developed to alleviate this interference by adjusting the weights of visual classifiers. However, our analysis of this class-wise prompt engineering suffers from two shortcomings for DG FAS: (1) The categories of facial categories, such as real or spoof, have no semantics for the CLIP model, making it difficult to learn accurate category descriptions. (2) A single form of prompt cannot portray the various types of spoofing. In this work, instead of class-wise prompts, we propose a novel Content-aware Composite Prompt Engineering (CCPE) that generates instance-wise composite prompts, including both fixed template and learnable prompts. Specifically, our CCPE constructs content-aware prompts from two branches: (1) Inherent content prompt explicitly benefits from abundant transferred knowledge from the instruction-based Large Language Model (LLM). (2) Learnable content prompts implicitly extract the most informative visual content via Q-Former. Moreover, we design a Cross-Modal Guidance Module (CGM) that dynamically adjusts unimodal features for fusion to achieve better generalized FAS. Finally, our CCPE has been validated for its effectiveness in multiple cross-domain experiments and achieves state-of-the-art (SOTA) results.
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
Mar 31, 2025The use of Multimodal Large Language Models (MLLMs) as an end-to-end solution for Embodied AI and Autonomous Driving has become a prevailing trend. While MLLMs have been extensively studied for visual semantic understanding tasks, their ability to perform precise and quantitative spatial-temporal understanding in real-world applications remains largely unexamined, leading to uncertain prospects. To evaluate models' Spatial-Temporal Intelligence, we introduce STI-Bench, a benchmark designed to evaluate MLLMs' spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects. Our benchmark encompasses a wide range of robot and vehicle operations across desktop, indoor, and outdoor scenarios. The extensive experiments reveals that the state-of-the-art MLLMs still struggle in real-world spatial-temporal understanding, especially in tasks requiring precise distance estimation and motion analysis.
MMCR: Benchmarking Cross-Source Reasoning in Scientific Papers
Mar 21, 2025



Fully comprehending scientific papers by machines reflects a high level of Artificial General Intelligence, requiring the ability to reason across fragmented and heterogeneous sources of information, presenting a complex and practically significant challenge. While Vision-Language Models (VLMs) have made remarkable strides in various tasks, particularly those involving reasoning with evidence source from single image or text page, their ability to use cross-source information for reasoning remains an open problem. This work presents MMCR, a high-difficulty benchmark designed to evaluate VLMs' capacity for reasoning with cross-source information from scientific papers. The benchmark comprises 276 high-quality questions, meticulously annotated by humans across 7 subjects and 10 task types. Experiments with 18 VLMs demonstrate that cross-source reasoning presents a substantial challenge for existing models. Notably, even the top-performing model, GPT-4o, achieved only 48.55% overall accuracy, with only 20% accuracy in multi-table comprehension tasks, while the second-best model, Qwen2.5-VL-72B, reached 39.86% overall accuracy. Furthermore, we investigated the impact of the Chain-of-Thought (CoT) technique on cross-source reasoning and observed a detrimental effect on small models, whereas larger models demonstrated substantially enhanced performance. These results highlight the pressing need to develop VLMs capable of effectively utilizing cross-source information for reasoning.
CardiacMamba: A Multimodal RGB-RF Fusion Framework with State Space Models for Remote Physiological Measurement
Feb 19, 2025
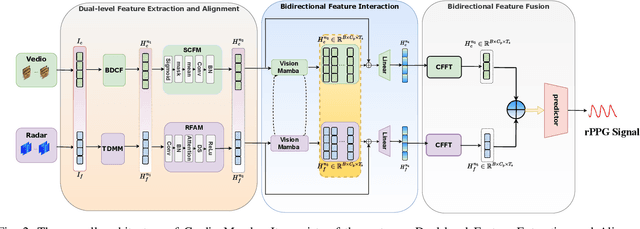
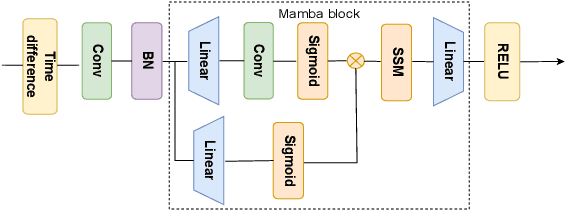
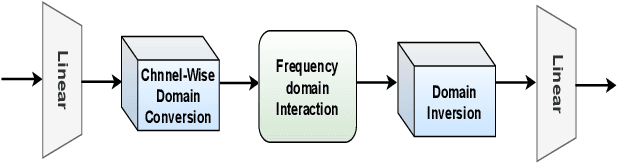
Heart rate (HR) estimation via remote photoplethysmography (rPPG) offers a non-invasive solution for health monitoring. However, traditional single-modality approaches (RGB or Radio Frequency (RF)) face challenges in balancing robustness and accuracy due to lighting variations, motion artifacts, and skin tone bias. In this paper, we propose CardiacMamba, a multimodal RGB-RF fusion framework that leverages the complementary strengths of both modalities. It introduces the Temporal Difference Mamba Module (TDMM) to capture dynamic changes in RF signals using timing differences between frames, enhancing the extraction of local and global features. Additionally, CardiacMamba employs a Bidirectional SSM for cross-modal alignment and a Channel-wise Fast Fourier Transform (CFFT) to effectively capture and refine the frequency domain characteristics of RGB and RF signals, ultimately improving heart rate estimation accuracy and periodicity detection. Extensive experiments on the EquiPleth dataset demonstrate state-of-the-art performance, achieving marked improvements in accuracy and robustness. CardiacMamba significantly mitigates skin tone bias, reducing performance disparities across demographic groups, and maintains resilience under missing-modality scenarios. By addressing critical challenges in fairness, adaptability, and precision, the framework advances rPPG technology toward reliable real-world deployment in healthcare. The codes are available at: https://github.com/WuZheng42/CardiacMamba.
Enhancing Generalization via Sharpness-Aware Trajectory Matching for Dataset Condensation
Feb 03, 2025



Dataset condensation aims to synthesize datasets with a few representative samples that can effectively represent the original datasets. This enables efficient training and produces models with performance close to those trained on the original sets. Most existing dataset condensation methods conduct dataset learning under the bilevel (inner- and outer-loop) based optimization. However, the preceding methods perform with limited dataset generalization due to the notoriously complicated loss landscape and expensive time-space complexity of the inner-loop unrolling of bilevel optimization. These issues deteriorate when the datasets are learned via matching the trajectories of networks trained on the real and synthetic datasets with a long horizon inner-loop. To address these issues, we introduce Sharpness-Aware Trajectory Matching (SATM), which enhances the generalization capability of learned synthetic datasets by optimising the sharpness of the loss landscape and objective simultaneously. Moreover, our approach is coupled with an efficient hypergradient approximation that is mathematically well-supported and straightforward to implement along with controllable computational overhead. Empirical evaluations of SATM demonstrate its effectiveness across various applications, including in-domain benchmarks and out-of-domain settings. Moreover, its easy-to-implement properties afford flexibility, allowing it to integrate with other advanced sharpness-aware minimizers. Our code will be released.
Normalizing Batch Normalization for Long-Tailed Recognition
Jan 06, 2025



In real-world scenarios, the number of training samples across classes usually subjects to a long-tailed distribution. The conventionally trained network may achieve unexpected inferior performance on the rare class compared to the frequent class. Most previous works attempt to rectify the network bias from the data-level or from the classifier-level. Differently, in this paper, we identify that the bias towards the frequent class may be encoded into features, i.e., the rare-specific features which play a key role in discriminating the rare class are much weaker than the frequent-specific features. Based on such an observation, we introduce a simple yet effective approach, normalizing the parameters of Batch Normalization (BN) layer to explicitly rectify the feature bias. To achieve this end, we represent the Weight/Bias parameters of a BN layer as a vector, normalize it into a unit one and multiply the unit vector by a scalar learnable parameter. Through decoupling the direction and magnitude of parameters in BN layer to learn, the Weight/Bias exhibits a more balanced distribution and thus the strength of features becomes more even. Extensive experiments on various long-tailed recognition benchmarks (i.e., CIFAR-10/100-LT, ImageNet-LT and iNaturalist 2018) show that our method outperforms previous state-of-the-arts remarkably. The code and checkpoints are available at https://github.com/yuxiangbao/NBN.
MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
Dec 19, 2024Despite the rapidly growing demand for multimodal retrieval, progress in this field remains severely constrained by a lack of training data. In this paper, we introduce MegaPairs, a novel data synthesis method that leverages vision language models (VLMs) and open-domain images, together with a massive synthetic dataset generated from this method. Our empirical analysis shows that MegaPairs generates high-quality data, enabling the multimodal retriever to significantly outperform the baseline model trained on 70$\times$ more data from existing datasets. Moreover, since MegaPairs solely relies on general image corpora and open-source VLMs, it can be easily scaled up, enabling continuous improvements in retrieval performance. In this stage, we produced more than 26 million training instances and trained several models of varying sizes using this data. These new models achieve state-of-the-art zero-shot performance across 4 popular composed image retrieval (CIR) benchmarks and the highest overall performance on the 36 datasets provided by MMEB. They also demonstrate notable performance improvements with additional downstream fine-tuning. Our produced dataset, well-trained models, and data synthesis pipeline will be made publicly available to facilitate the future development of this field.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024



While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.