 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEPA-MSAC: A Joint-Embedding Predictive Architecture for Multimodal Sensing-Assisted Communications
Mar 31, 2026Future wireless systems increasingly require predictive and transferable representations that can support multiple physical-layer (PHY) tasks under dynamic environments. However, most existing supervised learning-based methods are designed for a single task, which leads to high adaptation cost. To address this issue, we propose a joint-embedding predictive architecture for multimodal sensing-assisted communications (JEPA-MSAC), a self-supervised multimodal predictive representation learning framework for wireless environments. The proposed framework first maps multimodal sensing and communication measurements into a unified token space, and then pretrains a shared backbone using temporal block-masked JEPA to learn a predictive latent space that captures environment dynamics and cross-modal dependencies. After pretraining, the backbone is frozen and reused as a general future-feature generator, on top of which lightweight task heads are trained for localization, beam prediction, and received signal strength indicator (RSSI) prediction. Extensive experiments show the latent state supports accurate multi-task prediction with low adaptation cost. Additionally, ablation studies reveal its scaling behavior and the impact of key pretraining setups.
High-Resolution Underwater Camouflaged Object Detection: GBU-UCOD Dataset and Topology-Aware and Frequency-Decoupled Networks
Feb 03, 2026Underwater Camouflaged Object Detection (UCOD) is a challenging task due to the extreme visual similarity between targets and backgrounds across varying marine depths. Existing methods often struggle with topological fragmentation of slender creatures in the deep sea and the subtle feature extraction of transparent organisms. In this paper, we propose DeepTopo-Net, a novel framework that integrates topology-aware modeling with frequency-decoupled perception. To address physical degradation, we design the Water-Conditioned Adaptive Perceptor (WCAP), which employs Riemannian metric tensors to dynamically deform convolutional sampling fields. Furthermore, the Abyssal-Topology Refinement Module (ATRM) is developed to maintain the structural connectivity of spindly targets through skeletal priors. Specifically, we first introduce GBU-UCOD, the first high-resolution (2K) benchmark tailored for marine vertical zonation, filling the data gap for hadal and abyssal zones. Extensive experiments on MAS3K, RMAS, and our proposed GBU-UCOD datasets demonstrate that DeepTopo-Net achieves state-of-the-art performance, particularly in preserving the morphological integrity of complex underwater patterns. The datasets and codes will be released at https://github.com/Wuwenji18/GBU-UCOD.
Performance Comparison of Aerial RIS and STAR-RIS in 3D Wireless Environments
Dec 09, 2025Reconfigurable intelligent surface (RIS) and simultaneously transmitting and reflecting RIS (STAR-RIS) have emerged as key enablers for enhancing wireless coverage and capacity in next-generation networks. When mounted on unmanned aerial vehicles (UAVs), they benefit from flexible deployment and improved line-of-sight conditions. Despite their promising potential, a comprehensive performance comparison between aerial RIS and STAR-RIS architectures has not been thoroughly investigated. This letter presents a detailed performance comparison between aerial RIS and STAR-RIS in three-dimensional wireless environments. Accurate channel models incorporating directional radiation patterns are established, and the influence of deployment altitude and orientation is thoroughly examined. To optimize the system sum-rate, we formulate joint optimization problems for both architectures and propose an efficient solution based on the weighted minimum mean square error and block coordinate descent algorithms. Simulation results reveal that STAR-RIS outperforms RIS in low-altitude scenarios due to its full-space coverage capability, whereas RIS delivers better performance near the base station at higher altitudes. The findings provide practical insights for the deployment of aerial intelligent surfaces in future 6G communication systems.
Efficient Beamforming Optimization for STAR-RIS-Assisted Communications: A Gradient-Based Meta Learning Approach
Dec 09, 2025Simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) has emerged as a promising technology to realize full-space coverage and boost spectral efficiency in next-generation wireless networks. Yet, the joint design of the base station precoding matrix as well as the STAR-RIS transmission and reflection coefficient matrices leads to a high-dimensional, strongly nonconvex, and NP-hard optimization problem. Conventional alternating optimization (AO) schemes typically involve repeated large-scale matrix inversion operations, resulting in high computational complexity and poor scalability, while existing deep learning approaches often rely on expensive pre-training and large network models. In this paper, we develop a gradient-based meta learning (GML) framework that directly feeds optimization gradients into lightweight neural networks, thereby removing the need for pre-training and enabling fast adaptation. Specifically, we design dedicated GML-based schemes for both independent-phase and coupled-phase STAR-RIS models, effectively handling their respective amplitude and phase constraints while achieving weighted sum-rate performance very close to that of AO-based benchmarks. Extensive simulations demonstrate that, for both phase models, the proposed methods substantially reduce computational overhead, with complexity growing nearly linearly when the number of BS antennas and STAR-RIS elements grows, and yielding up to 10 times runtime speedup over AO, which confirms the scalability and practicality of the proposed GML method for large-scale STAR-RIS-assisted communications.
Multimodal Radio and Vision Fusion for Robust Localization in Urban V2I Communications
Aug 25, 2025Accurate localization is critical for vehicle-to-infrastructure (V2I) communication systems, especially in urban areas where GPS signals are often obstructed by tall buildings, leading to significant positioning errors, necessitating alternative or complementary techniques for reliable and precise positioning in applications like autonomous driving and smart city infrastructure. This paper proposes a multimodal contrastive learning regression based localization framework for V2I scenarios that combines channel state information (CSI) with visual information to achieve improved accuracy and reliability. The approach leverages the complementary strengths of wireless and visual data to overcome the limitations of traditional localization methods, offering a robust solution for V2I applications. Simulation results demonstrate that the proposed CSI and vision fusion model significantly outperforms traditional methods and single modal models, achieving superior localization accuracy and precision in complex urban environments.
M2BeamLLM: Multimodal Sensing-empowered mmWave Beam Prediction with Large Language Models
Jun 17, 2025This paper introduces a novel neural network framework called M2BeamLLM for beam prediction in millimeter-wave (mmWave) massive multi-input multi-output (mMIMO) communication systems. M2BeamLLM integrates multi-modal sensor data, including images, radar, LiDAR, and GPS, leveraging the powerful reasoning capabilities of large language models (LLMs) such as GPT-2 for beam prediction. By combining sensing data encoding, multimodal alignment and fusion, and supervised fine-tuning (SFT), M2BeamLLM achieves significantly higher beam prediction accuracy and robustness, demonstrably outperforming traditional deep learning (DL) models in both standard and few-shot scenarios. Furthermore, its prediction performance consistently improves with increased diversity in sensing modalities. Our study provides an efficient and intelligent beam prediction solution for vehicle-to-infrastructure (V2I) mmWave communication systems.
BeamLLM: Vision-Empowered mmWave Beam Prediction with Large Language Models
Mar 13, 2025In this paper, we propose BeamLLM, a vision-aided millimeter-wave (mmWave) beam prediction framework leveraging large language models (LLMs) to address the challenges of high training overhead and latency in mmWave communication systems. By combining computer vision (CV) with LLMs' cross-modal reasoning capabilities, the framework extracts user equipment (UE) positional features from RGB images and aligns visual-temporal features with LLMs' semantic space through reprogramming techniques. Evaluated on a realistic vehicle-to-infrastructure (V2I) scenario, the proposed method achieves 61.01% top-1 accuracy and 97.39% top-3 accuracy in standard prediction tasks, significantly outperforming traditional deep learning models. In few-shot prediction scenarios, the performance degradation is limited to 12.56% (top-1) and 5.55% (top-3) from time sample 1 to 10, demonstrating superior prediction capability.
CardiacMamba: A Multimodal RGB-RF Fusion Framework with State Space Models for Remote Physiological Measurement
Feb 19, 2025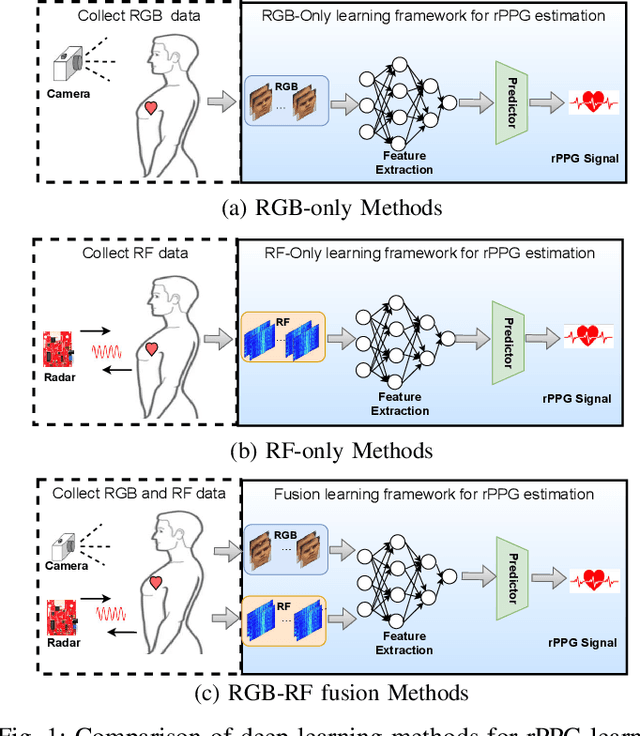
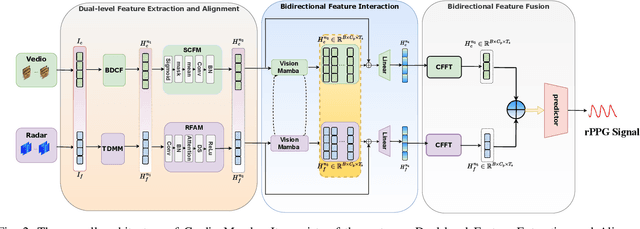
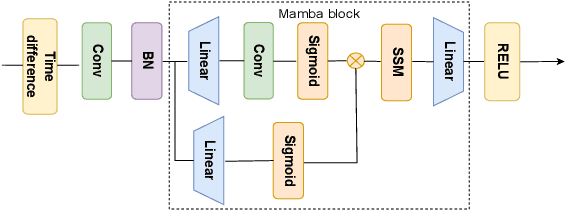
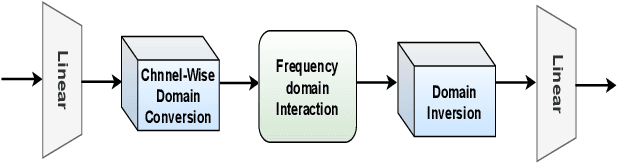
Heart rate (HR) estimation via remote photoplethysmography (rPPG) offers a non-invasive solution for health monitoring. However, traditional single-modality approaches (RGB or Radio Frequency (RF)) face challenges in balancing robustness and accuracy due to lighting variations, motion artifacts, and skin tone bias. In this paper, we propose CardiacMamba, a multimodal RGB-RF fusion framework that leverages the complementary strengths of both modalities. It introduces the Temporal Difference Mamba Module (TDMM) to capture dynamic changes in RF signals using timing differences between frames, enhancing the extraction of local and global features. Additionally, CardiacMamba employs a Bidirectional SSM for cross-modal alignment and a Channel-wise Fast Fourier Transform (CFFT) to effectively capture and refine the frequency domain characteristics of RGB and RF signals, ultimately improving heart rate estimation accuracy and periodicity detection. Extensive experiments on the EquiPleth dataset demonstrate state-of-the-art performance, achieving marked improvements in accuracy and robustness. CardiacMamba significantly mitigates skin tone bias, reducing performance disparities across demographic groups, and maintains resilience under missing-modality scenarios. By addressing critical challenges in fairness, adaptability, and precision, the framework advances rPPG technology toward reliable real-world deployment in healthcare. The codes are available at: https://github.com/WuZheng42/CardiacMamba.
A Simplified Algorithm for Joint Real-Time Synchronization, NLoS Identification, and Multi-Agent Localization
Dec 17, 2024



Real-time, high-precision localization in large-scale wireless networks faces two primary challenges: clock offsets caused by network asynchrony and non-line-of-sight (NLoS) conditions. To tackle these challenges, we propose a low-complexity real-time algorithm for joint synchronization and NLoS identification-based localization. For precise synchronization, we resolve clock offsets based on accumulated time-of-arrival measurements from all the past time instances, modeling it as a large-scale linear least squares (LLS) problem. To alleviate the high computational burden of solving this LLS, we introduce the blockwise recursive Moore-Penrose inverse (BRMP) technique, a generalized recursive least squares approach, and derive a simplified formulation of BRMP tailored specifically for the real-time synchronization problem. Furthermore, we formulate joint NLoS identification and localization as a robust least squares regression (RLSR) problem and address it by using an efficient iterative approach. Simulations show that the proposed algorithm achieves sub-nanosecond synchronization accuracy and centimeter-level localization precision, while maintaining low computational overhead.
Low-Complexity Near-Field Channel Estimation for Hybrid RIS Assisted Systems
Apr 30, 2024



We investigate the channel estimation (CE) problem for hybrid RIS assisted systems and focus on the near-field (NF) regime. Different from their far-field counterparts, NF channels possess a block-sparsity property, which is leveraged in the two developed CE algorithms: (i) boundary estimation and sub-vector recovery (BESVR) and (ii) linear total variation regularization (TVR). In addition, we adopt the alternating direction method of multipliers to reduce their computational complexity. Numerical results show that the linear TVR algorithm outperforms the chosen baseline schemes in terms of normalized mean square error in the high signal-to-noise ratio regime while the BESVR algorithm achieves comparable performance to the baseline schemes but with the added advantage of minimal CPU time.