 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCI-VID: A Coherent Interleaved Text-Video Dataset
Jul 02, 2025Text-to-video (T2V) generation has recently attracted considerable attention, resulting in the development of numerous high-quality datasets that have propelled progress in this area. However, existing public datasets are primarily composed of isolated text-video (T-V) pairs and thus fail to support the modeling of coherent multi-clip video sequences. To address this limitation, we introduce CI-VID, a dataset that moves beyond isolated text-to-video (T2V) generation toward text-and-video-to-video (TV2V) generation, enabling models to produce coherent, multi-scene video sequences. CI-VID contains over 340,000 samples, each featuring a coherent sequence of video clips with text captions that capture both the individual content of each clip and the transitions between them, enabling visually and textually grounded generation. To further validate the effectiveness of CI-VID, we design a comprehensive, multi-dimensional benchmark incorporating human evaluation, VLM-based assessment, and similarity-based metrics. Experimental results demonstrate that models trained on CI-VID exhibit significant improvements in both accuracy and content consistency when generating video sequences. This facilitates the creation of story-driven content with smooth visual transitions and strong temporal coherence, underscoring the quality and practical utility of the CI-VID dataset We release the CI-VID dataset and the accompanying code for data construction and evaluation at: https://github.com/ymju-BAAI/CI-VID
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
May 08, 2025Recent progress in unified models for image understanding and generation has been impressive, yet most approaches remain limited to single-modal generation conditioned on multiple modalities. In this paper, we present Mogao, a unified framework that advances this paradigm by enabling interleaved multi-modal generation through a causal approach. Mogao integrates a set of key technical improvements in architecture design, including a deep-fusion design, dual vision encoders, interleaved rotary position embeddings, and multi-modal classifier-free guidance, which allow it to harness the strengths of both autoregressive models for text generation and diffusion models for high-quality image synthesis. These practical improvements also make Mogao particularly effective to process interleaved sequences of text and images arbitrarily. To further unlock the potential of unified models, we introduce an efficient training strategy on a large-scale, in-house dataset specifically curated for joint text and image generation. Extensive experiments show that Mogao not only achieves state-of-the-art performance in multi-modal understanding and text-to-image generation, but also excels in producing high-quality, coherent interleaved outputs. Its emergent capabilities in zero-shot image editing and compositional generation highlight Mogao as a practical omni-modal foundation model, paving the way for future development and scaling the unified multi-modal systems.
Autoregressive Video Generation without Vector Quantization
Dec 18, 2024



This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
Dec 09, 2024



Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data -- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a warping-based pipeline for high-fidelity 3D generation. Our numerical and visual comparisons on single and sparse reconstruction benchmarks show that See3D, trained on cost-effective and scalable video data, achieves notable zero-shot and open-world generation capabilities, markedly outperforming models trained on costly and constrained 3D datasets. Please refer to our project page at: https://vision.baai.ac.cn/see3d
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024



While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
Generative Multimodal Models are In-Context Learners
Dec 20, 2023The human ability to easily solve multimodal tasks in context (i.e., with only a few demonstrations or simple instructions), is what current multimodal systems have largely struggled to imitate. In this work, we demonstrate that the task-agnostic in-context learning capabilities of large multimodal models can be significantly enhanced by effective scaling-up. We introduce Emu2, a generative multimodal model with 37 billion parameters, trained on large-scale multimodal sequences with a unified autoregressive objective. Emu2 exhibits strong multimodal in-context learning abilities, even emerging to solve tasks that require on-the-fly reasoning, such as visual prompting and object-grounded generation. The model sets a new record on multiple multimodal understanding tasks in few-shot settings. When instruction-tuned to follow specific instructions, Emu2 further achieves new state-of-the-art on challenging tasks such as question answering benchmarks for large multimodal models and open-ended subject-driven generation. These achievements demonstrate that Emu2 can serve as a base model and general-purpose interface for a wide range of multimodal tasks. Code and models are publicly available to facilitate future research.
End-to-end Alternating Optimization for Real-World Blind Super Resolution
Aug 17, 2023Blind Super-Resolution (SR) usually involves two sub-problems: 1) estimating the degradation of the given low-resolution (LR) image; 2) super-resolving the LR image to its high-resolution (HR) counterpart. Both problems are ill-posed due to the information loss in the degrading process. Most previous methods try to solve the two problems independently, but often fall into a dilemma: a good super-resolved HR result requires an accurate degradation estimation, which however, is difficult to be obtained without the help of original HR information. To address this issue, instead of considering these two problems independently, we adopt an alternating optimization algorithm, which can estimate the degradation and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the estimated degradation, and \textit{Estimator} estimates the degradation with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, both \textit{Restorer} and \textit{Estimator} could get benefited from the intermediate results of each other, and make each sub-problem easier. Moreover, \textit{Restorer} and \textit{Estimator} are optimized in an end-to-end manner, thus they could get more tolerant of the estimation deviations of each other and cooperate better to achieve more robust and accurate final results. Extensive experiments on both synthetic datasets and real-world images show that the proposed method can largely outperform state-of-the-art methods and produce more visually favorable results. The codes are rleased at \url{https://github.com/greatlog/RealDAN.git}.
* Extension of our previous NeurIPS paper. Accepted to IJCV
VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
Mar 22, 2023



A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
Learning the Degradation Distribution for Blind Image Super-Resolution
Mar 09, 2022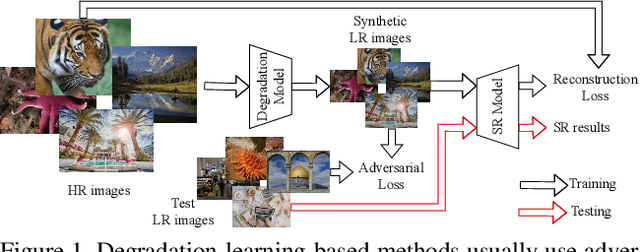
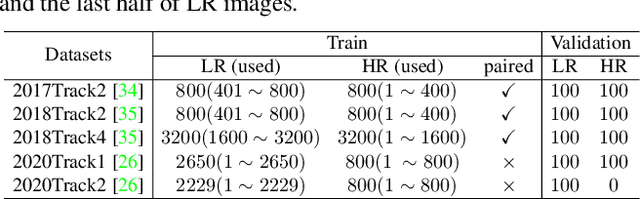
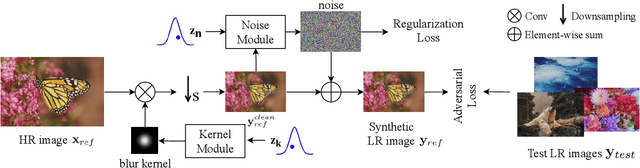
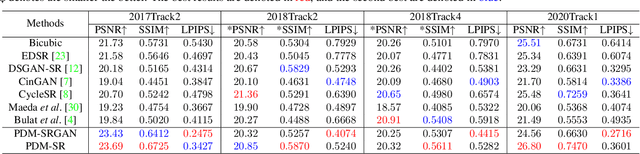
Synthetic high-resolution (HR) \& low-resolution (LR) pairs are widely used in existing super-resolution (SR) methods. To avoid the domain gap between synthetic and test images, most previous methods try to adaptively learn the synthesizing (degrading) process via a deterministic model. However, some degradations in real scenarios are stochastic and cannot be determined by the content of the image. These deterministic models may fail to model the random factors and content-independent parts of degradations, which will limit the performance of the following SR models. In this paper, we propose a probabilistic degradation model (PDM), which studies the degradation $\mathbf{D}$ as a random variable, and learns its distribution by modeling the mapping from a priori random variable $\mathbf{z}$ to $\mathbf{D}$. Compared with previous deterministic degradation models, PDM could model more diverse degradations and generate HR-LR pairs that may better cover the various degradations of test images, and thus prevent the SR model from over-fitting to specific ones. Extensive experiments have demonstrated that our degradation model can help the SR model achieve better performance on different datasets. The source codes are released at \url{git@github.com:greatlog/UnpairedSR.git}.
Approaching the Limit of Image Rescaling via Flow Guidance
Nov 09, 2021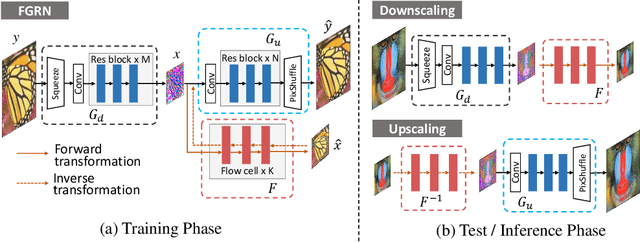
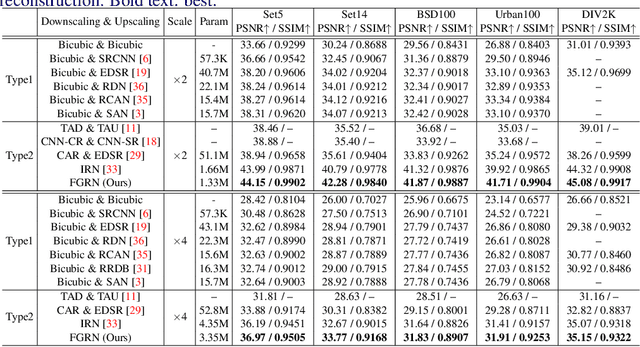
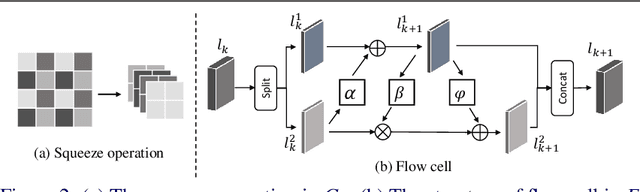
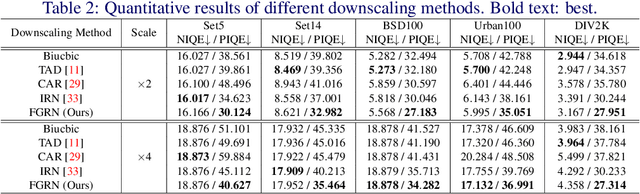
Image downscaling and upscaling are two basic rescaling operations. Once the image is downscaled, it is difficult to be reconstructed via upscaling due to the loss of information. To make these two processes more compatible and improve the reconstruction performance, some efforts model them as a joint encoding-decoding task, with the constraint that the downscaled (i.e. encoded) low-resolution (LR) image must preserve the original visual appearance. To implement this constraint, most methods guide the downscaling module by supervising it with the bicubically downscaled LR version of the original high-resolution (HR) image. However, this bicubic LR guidance may be suboptimal for the subsequent upscaling (i.e. decoding) and restrict the final reconstruction performance. In this paper, instead of directly applying the LR guidance, we propose an additional invertible flow guidance module (FGM), which can transform the downscaled representation to the visually plausible image during downscaling and transform it back during upscaling. Benefiting from the invertibility of FGM, the downscaled representation could get rid of the LR guidance and would not disturb the downscaling-upscaling process. It allows us to remove the restrictions on the downscaling module and optimize the downscaling and upscaling modules in an end-to-end manner. In this way, these two modules could cooperate to maximize the HR reconstruction performance. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SotA) performance on both downscaled and reconstructed images.