 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Fragment Retrieval in Multi-modal Long-form Dialogues
Jun 03, 2026With the widespread adoption of multi-modal communication platforms, long-form dialogues interleaving text and images have become increasingly common. Users often need to retrieve coherent dialogue fragments related to specific topics, rather than isolated utterances. We propose Fine-grained Fragment Retrieval (FFR), which locates semantically relevant multi-utterance, multi-image fragments in multi-modal long-form dialogues. We explore two settings: (1) FFR within Single-Dialogue, retrieving fragments from a given dialogue; and (2) FFR within Dialogue Corpus, retrieving from a large-scale corpus for open-domain scenarios. For (1), we introduce F2RVLM, a generation-based retrieval model trained with reinforcement learning, using multi-objective rewards and difficulty-aware curriculum sampling to enhance fragment coherence. For (2), we develop FFRS, a two-stage system combining offline fragment-level indexing with online retrieval. Specifically, each dialogue is decomposed into minimal semantic fragments encoded by a Fragment Embedding Model (FEM) into a vector database; at inference, FEM rapidly recalls Top-K candidates, and F2RVLM performs fine-grained reasoning to identify the most relevant sub-content. To support FFR, we construct MLDR, the longest multi-modal dialogue retrieval dataset to date, and a WeChat-based real-world test set. Experiments on both benchmarks demonstrate that F2RVLM and FFRS consistently achieve superior performance across single-dialogue and corpus-level FFR.
SketchSong: Hierarchical Song Generation with Sketch Planning and Fine-Grained Multi-Track Modeling
Jun 02, 2026Recent song generation systems can synthesize realistic audio, yet generating complete songs remains challenging for two reasons. First, explicit song-level arrangement planning remains limited in existing methods, so models often need to organize overall arrangement development while generating low-level audio details. This often leads to incoherence in arrangements, such as weak section transitions and limited dynamic progression. Second, coarse modeling of different musical parts obscures their distinct roles and interactions, limiting arrangement richness of generated songs. In this paper, we present SketchSong, a hierarchical song generation framework that addresses these issues through song-level sketch planning and fine-grained multi-track modeling. Along the temporal dimension, SketchSong first predicts a compact sequence of high-level sketch tokens derived from compressed audio representations, and then generates audio tokens conditioned on these sketches. This coarse-to-fine process gives the model an explicit arrangement plan before detailed audio generation. Along the track dimension, SketchSong explicitly models four tracks, i.e., vocals, bass, drums and other instruments. This enables the model to capture the roles and interactions of different musical parts more precisely. Experiments on song generation benchmarks show that SketchSong consistently outperforms our baseline on both objective metrics and human listening tests. Despite not employing additional post-training for preference optimization such as lyrics and text-prompt alignments, SketchSong achieves competitive results against strong, post-trained open-source systems, demonstrating the effectiveness of our overall design.
CoDA: Color Distribution Probing for Efficient and Generalizable AI-Generated Image Detection
May 23, 2026AI-generated image detection faces a persistent trade-off between generalization and efficiency: lightweight artifact-based methods often degrade on unseen generators or domains, whereas more robust large-scale models are computationally expensive. Meanwhile, existing benchmarks mainly focus on cross-model evaluation in photorealistic settings, leaving cross-domain robustness underexplored. To address this gap, we introduce FakeForm, a large-scale benchmark with approximately 370,000 images across 62 diverse domains for both cross-model and cross-domain evaluation. Motivated by this broader setting, we revisit color-distribution probing as an efficient complementary cue for AI-generated image detection. We observe that, especially for photographic content, real photographs tend to exhibit smoother and more stable color patterns, whereas synthetic images often show characteristic color imbalances introduced by neural generation. Based on this observation, we propose CoDA, a compact 1.48M-parameter detector built on a Noise-Quantization Probe, together with a theoretical analysis linking probe responses to color non-uniformity. Experiments show that CoDA achieves state-of-the-art performance on standard benchmarks and the best results on the challenging cross-domain evaluation of FakeForm, while remaining highly competitive in cross-model photorealistic settings. These results suggest that persistent generative artifacts can provide a practical foundation for efficient and robust AI-generated image detection. The models and FakeForm benchmark will be made publicly available.
Parameter-Efficient Semantic Augmentation for Enhancing Open-Vocabulary Object Detection
Apr 06, 2026Open-vocabulary object detection (OVOD) enables models to detect any object category, including unseen ones. Benefiting from large-scale pre-training, existing OVOD methods achieve strong detection performance on general scenarios (e.g., OV-COCO) but suffer severe performance drops when transferred to downstream tasks with substantial domain shifts. This degradation stems from the scarcity and weak semantics of category labels in domain-specific task, as well as the inability of existing models to capture auxiliary semantics beyond coarse-grained category label. To address these issues, we propose HSA-DINO, a parameter-efficient semantic augmentation framework for enhancing open-vocabulary object detection. Specifically, we propose a multi-scale prompt bank that leverages image feature pyramids to capture hierarchical semantics and select domain-specific local semantic prompts, progressively enriching textual representations from coarse to fine-grained levels. Furthermore, we introduce a semantic-aware router that dynamically selects the appropriate semantic augmentation strategy during inference, thereby preventing parameter updates from degrading the generalization ability of the pre-trained OVOD model. We evaluate HSA-DINO on OV-COCO, several vertical domain datasets, and modified benchmark settings. The results show that HSA-DINO performs favorably against previous state-of-the-art methods, achieving a superior trade-off between domain adaptability and open-vocabulary generalization.
Tutti: Expressive Multi-Singer Synthesis via Structure-Level Timbre Control and Vocal Texture Modeling
Feb 09, 2026While existing Singing Voice Synthesis systems achieve high-fidelity solo performances, they are constrained by global timbre control, failing to address dynamic multi-singer arrangement and vocal texture within a single song. To address this, we propose Tutti, a unified framework designed for structured multi-singer generation. Specifically, we introduce a Structure-Aware Singer Prompt to enable flexible singer scheduling evolving with musical structure, and propose Complementary Texture Learning via Condition-Guided VAE to capture implicit acoustic textures (e.g., spatial reverberation and spectral fusion) that are complementary to explicit controls. Experiments demonstrate that Tutti excels in precise multi-singer scheduling and significantly enhances the acoustic realism of choral generation, offering a novel paradigm for complex multi-singer arrangement. Audio samples are available at https://annoauth123-ctrl.github.io/Tutii_Demo/.
F2RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model
Aug 25, 2025Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users' actual needs for revisiting semantically coherent content scattered across long-form conversations. To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To this end, we propose F2RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards promoting semantic precision, relevance, and contextual coherence. To handle varying intra-fragment complexity, from locally dense to sparsely distributed, we introduce difficulty-aware curriculum sampling that ranks training instances by model-predicted difficulty and gradually exposes the model to harder samples. This boosts reasoning ability in long, multi-turn contexts. F2RVLM outperforms popular VLMs in both in-domain and real-domain settings, demonstrating superior retrieval performance.
Enhancing Visual Reliance in Text Generation: A Bayesian Perspective on Mitigating Hallucination in Large Vision-Language Models
May 26, 2025Large Vision-Language Models (LVLMs) usually generate texts which satisfy context coherence but don't match the visual input. Such a hallucination issue hinders LVLMs' applicability in the real world. The key to solving hallucination in LVLM is to make the text generation rely more on the visual content. Most previous works choose to enhance/adjust the features/output of a specific modality (i.e., visual or textual) to alleviate hallucinations in LVLM, which do not explicitly or systematically enhance the visual reliance. In this paper, we comprehensively investigate the factors which may degenerate the visual reliance in text generation of LVLM from a Bayesian perspective. Based on our observations, we propose to mitigate hallucination in LVLM from three aspects. Firstly, we observe that not all visual tokens are informative in generating meaningful texts. We propose to evaluate and remove redundant visual tokens to avoid their disturbance. Secondly, LVLM may encode inappropriate prior information, making it lean toward generating unexpected words. We propose a simple yet effective way to rectify the prior from a Bayesian perspective. Thirdly, we observe that starting from certain steps, the posterior of next-token prediction conditioned on visual tokens may collapse to a prior distribution which does not depend on any informative visual tokens at all. Thus, we propose to stop further text generation to avoid hallucination. Extensive experiments on three benchmarks including POPE, CHAIR, and MME demonstrate that our method can consistently mitigate the hallucination issue of LVLM and performs favorably against previous state-of-the-arts.
Normalizing Batch Normalization for Long-Tailed Recognition
Jan 06, 2025



In real-world scenarios, the number of training samples across classes usually subjects to a long-tailed distribution. The conventionally trained network may achieve unexpected inferior performance on the rare class compared to the frequent class. Most previous works attempt to rectify the network bias from the data-level or from the classifier-level. Differently, in this paper, we identify that the bias towards the frequent class may be encoded into features, i.e., the rare-specific features which play a key role in discriminating the rare class are much weaker than the frequent-specific features. Based on such an observation, we introduce a simple yet effective approach, normalizing the parameters of Batch Normalization (BN) layer to explicitly rectify the feature bias. To achieve this end, we represent the Weight/Bias parameters of a BN layer as a vector, normalize it into a unit one and multiply the unit vector by a scalar learnable parameter. Through decoupling the direction and magnitude of parameters in BN layer to learn, the Weight/Bias exhibits a more balanced distribution and thus the strength of features becomes more even. Extensive experiments on various long-tailed recognition benchmarks (i.e., CIFAR-10/100-LT, ImageNet-LT and iNaturalist 2018) show that our method outperforms previous state-of-the-arts remarkably. The code and checkpoints are available at https://github.com/yuxiangbao/NBN.
Tuning-Free Inversion-Enhanced Control for Consistent Image Editing
Dec 22, 2023

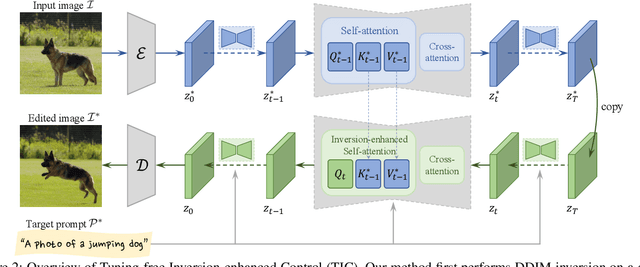

Consistent editing of real images is a challenging task, as it requires performing non-rigid edits (e.g., changing postures) to the main objects in the input image without changing their identity or attributes. To guarantee consistent attributes, some existing methods fine-tune the entire model or the textual embedding for structural consistency, but they are time-consuming and fail to perform non-rigid edits. Other works are tuning-free, but their performances are weakened by the quality of Denoising Diffusion Implicit Model (DDIM) reconstruction, which often fails in real-world scenarios. In this paper, we present a novel approach called Tuning-free Inversion-enhanced Control (TIC), which directly correlates features from the inversion process with those from the sampling process to mitigate the inconsistency in DDIM reconstruction. Specifically, our method effectively obtains inversion features from the key and value features in the self-attention layers, and enhances the sampling process by these inversion features, thus achieving accurate reconstruction and content-consistent editing. To extend the applicability of our method to general editing scenarios, we also propose a mask-guided attention concatenation strategy that combines contents from both the inversion and the naive DDIM editing processes. Experiments show that the proposed method outperforms previous works in reconstruction and consistent editing, and produces impressive results in various settings.
Few-Shot Learning with Visual Distribution Calibration and Cross-Modal Distribution Alignment
May 19, 2023Pre-trained vision-language models have inspired much research on few-shot learning. However, with only a few training images, there exist two crucial problems: (1) the visual feature distributions are easily distracted by class-irrelevant information in images, and (2) the alignment between the visual and language feature distributions is difficult. To deal with the distraction problem, we propose a Selective Attack module, which consists of trainable adapters that generate spatial attention maps of images to guide the attacks on class-irrelevant image areas. By messing up these areas, the critical features are captured and the visual distributions of image features are calibrated. To better align the visual and language feature distributions that describe the same object class, we propose a cross-modal distribution alignment module, in which we introduce a vision-language prototype for each class to align the distributions, and adopt the Earth Mover's Distance (EMD) to optimize the prototypes. For efficient computation, the upper bound of EMD is derived. In addition, we propose an augmentation strategy to increase the diversity of the images and the text prompts, which can reduce overfitting to the few-shot training images. Extensive experiments on 11 datasets demonstrate that our method consistently outperforms prior arts in few-shot learning. The implementation code will be available at https://github.com/bhrqw/SADA.