 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoBench: Rethinking Multimodal Geometric Problem-Solving via Hierarchical Evaluation
Dec 30, 2025Geometric problem solving constitutes a critical branch of mathematical reasoning, requiring precise analysis of shapes and spatial relationships. Current evaluations of geometric reasoning in vision-language models (VLMs) face limitations, including the risk of test data contamination from textbook-based benchmarks, overemphasis on final answers over reasoning processes, and insufficient diagnostic granularity. To address these issues, we present GeoBench, a hierarchical benchmark featuring four reasoning levels in geometric problem-solving: Visual Perception, Goal-Oriented Planning, Rigorous Theorem Application, and Self-Reflective Backtracking. Through six formally verified tasks generated via TrustGeoGen, we systematically assess capabilities ranging from attribute extraction to logical error correction. Experiments reveal that while reasoning models like OpenAI-o3 outperform general MLLMs, performance declines significantly with increasing task complexity. Key findings demonstrate that sub-goal decomposition and irrelevant premise filtering critically influence final problem-solving accuracy, whereas Chain-of-Thought prompting unexpectedly degrades performance in some tasks. These findings establish GeoBench as a comprehensive benchmark while offering actionable guidelines for developing geometric problem-solving systems.
ViLaCD-R1: A Vision-Language Framework for Semantic Change Detection in Remote Sensing
Dec 29, 2025Remote sensing change detection (RSCD), a complex multi-image inference task, traditionally uses pixel-based operators or encoder-decoder networks that inadequately capture high-level semantics and are vulnerable to non-semantic perturbations. Although recent multimodal and vision-language model (VLM)-based approaches enhance semantic understanding of change regions by incorporating textual descriptions, they still suffer from challenges such as inaccurate spatial localization, imprecise pixel-level boundary delineation, and limited interpretability. To address these issues, we propose ViLaCD-R1, a two-stage framework comprising a Multi-Image Reasoner (MIR) and a Mask-Guided Decoder (MGD). Specifically, the VLM is trained through supervised fine-tuning (SFT) and reinforcement learning (RL) on block-level dual-temporal inference tasks, taking dual-temporal image patches as input and outputting a coarse change mask. Then, the decoder integrates dual-temporal image features with this coarse mask to predict a precise binary change map. Comprehensive evaluations on multiple RSCD benchmarks demonstrate that ViLaCD-R1 substantially improves true semantic change recognition and localization, robustly suppresses non-semantic variations, and achieves state-of-the-art accuracy in complex real-world scenarios.
GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation
Dec 29, 2025Driving World Models (DWMs) have been developing rapidly with the advances of generative models. However, existing DWMs lack 3D scene understanding capabilities and can only generate content conditioned on input data, without the ability to interpret or reason about the driving environment. Moreover, current approaches represent 3D spatial information with point cloud or BEV features do not accurately align textual information with the underlying 3D scene. To address these limitations, we propose a novel unified DWM framework based on 3D Gaussian scene representation, which enables both 3D scene understanding and multi-modal scene generation, while also enabling contextual enrichment for understanding and generation tasks. Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process. We conduct comprehensive studies on the nuScenes, and NuInteract datasets to validate the effectiveness of our framework. Our method achieves state-of-the-art performance. We will release the code publicly on GitHub https://github.com/dtc111111/GaussianDWM.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
GuangMing-Explorer: A Four-Legged Robot Platform for Autonomous Exploration in General Environments
Dec 17, 2025Autonomous exploration is a fundamental capability that tightly integrates perception, planning, control, and motion execution. It plays a critical role in a wide range of applications, including indoor target search, mapping of extreme environments, resource exploration, etc. Despite significant progress in individual components, a holistic and practical description of a completely autonomous exploration system, encompassing both hardware and software, remains scarce. In this paper, we present GuangMing-Explorer, a fully integrated autonomous exploration platform designed for robust operation across diverse environments. We provide a comprehensive overview of the system architecture, including hardware design, software stack, algorithm deployment, and experimental configuration. Extensive real-world experiments demonstrate the platform's effectiveness and efficiency in executing autonomous exploration tasks, highlighting its potential for practical deployment in complex and unstructured environments.
ViRC: Enhancing Visual Interleaved Mathematical CoT with Reason Chunking
Dec 17, 2025CoT has significantly enhanced the reasoning ability of LLMs while it faces challenges when extended to multimodal domains, particularly in mathematical tasks. Existing MLLMs typically perform textual reasoning solely from a single static mathematical image, overlooking dynamic visual acquisition during reasoning. In contrast, humans repeatedly examine visual image and employ step-by-step reasoning to prove intermediate propositions. This strategy of decomposing the problem-solving process into key logical nodes adheres to Miller's Law in cognitive science. Inspired by this insight, we propose a ViRC framework for multimodal mathematical tasks, introducing a Reason Chunking mechanism that structures multimodal mathematical CoT into consecutive Critical Reasoning Units (CRUs) to simulate human expert problem-solving patterns. CRUs ensure intra-unit textual coherence for intermediate proposition verification while integrating visual information across units to generate subsequent propositions and support structured reasoning. To this end, we present CRUX dataset by using three visual tools and four reasoning patterns to provide explicitly annotated CRUs across multiple reasoning paths for each mathematical problem. Leveraging the CRUX dataset, we propose a progressive training strategy inspired by human cognitive learning, which includes Instructional SFT, Practice SFT, and Strategic RL, aimed at further strengthening the Reason Chunking ability of the model. The resulting ViRC-7B model achieves a 18.8% average improvement over baselines across multiple mathematical benchmarks. Code is available at https://github.com/Leon-LihongWang/ViRC.
OmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving
Dec 16, 2025



The deployment of Vision-Language Models (VLMs) in safety-critical domains like autonomous driving (AD) is critically hindered by reliability failures, most notably object hallucination. This failure stems from their reliance on ungrounded, text-based Chain-of-Thought (CoT) reasoning.While existing multi-modal CoT approaches attempt mitigation, they suffer from two fundamental flaws: (1) decoupled perception and reasoning stages that prevent end-to-end joint optimization, and (2) reliance on expensive, dense localization labels.Thus we introduce OmniDrive-R1, an end-to-end VLM framework designed for autonomous driving, which unifies perception and reasoning through an interleaved Multi-modal Chain-of-Thought (iMCoT) mechanism. Our core innovation is an Reinforcement-driven visual grounding capability, enabling the model to autonomously direct its attention and "zoom in" on critical regions for fine-grained analysis. This capability is enabled by our pure two-stage reinforcement learning training pipeline and Clip-GRPO algorithm. Crucially, Clip-GRPO introduces an annotation-free, process-based grounding reward. This reward not only eliminates the need for dense labels but also circumvents the instability of external tool calls by enforcing real-time cross-modal consistency between the visual focus and the textual reasoning. Extensive experiments on DriveLMM-o1 demonstrate our model's significant improvements. Compared to the baseline Qwen2.5VL-7B, OmniDrive-R1 improves the overall reasoning score from 51.77% to 80.35%, and the final answer accuracy from 37.81% to 73.62%.
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Dec 15, 2025We introduce QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. The key technical breakthroughs of QwenLong-L1.5 are as follows: (1) Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities. (2) Stabilized Reinforcement Learning for Long-Context Training: To overcome the critical instability in long-context RL, we introduce task-balanced sampling with task-specific advantage estimation to mitigate reward bias, and propose Adaptive Entropy-Controlled Policy Optimization (AEPO) that dynamically regulates exploration-exploitation trade-offs. (3) Memory-Augmented Architecture for Ultra-Long Contexts: Recognizing that even extended context windows cannot accommodate arbitrarily long sequences, we develop a memory management framework with multi-stage fusion RL training that seamlessly integrates single-pass reasoning with iterative memory-based processing for tasks exceeding 4M tokens. Based on Qwen3-30B-A3B-Thinking, QwenLong-L1.5 achieves performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks, surpassing its baseline by 9.90 points on average. On ultra-long tasks (1M~4M tokens), QwenLong-L1.5's memory-agent framework yields a 9.48-point gain over the agent baseline. Additionally, the acquired long-context reasoning ability translates to enhanced performance in general domains like scientific reasoning, memory tool using, and extended dialogue.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025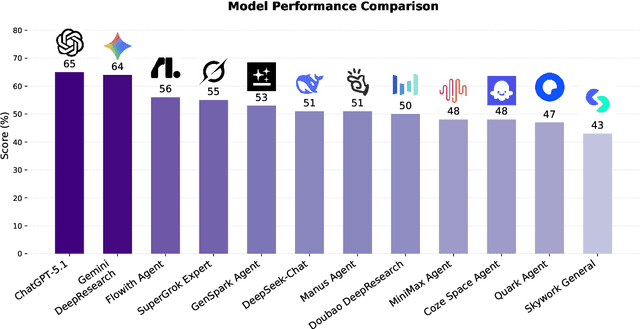
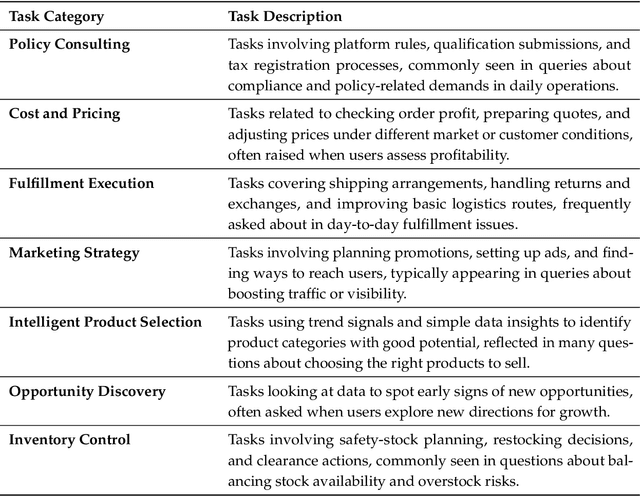

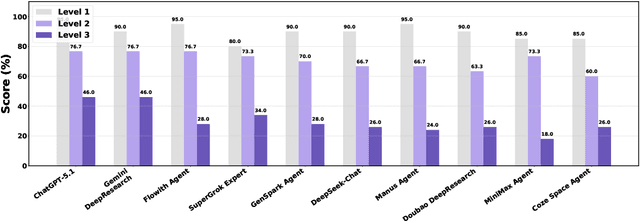
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.