 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Neural Operators
May 06, 2022
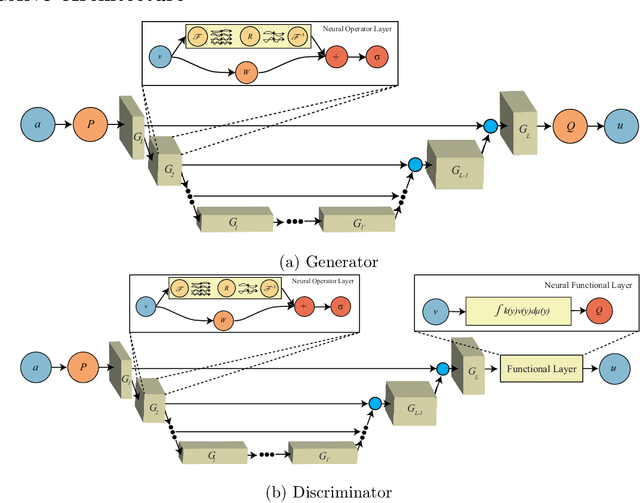
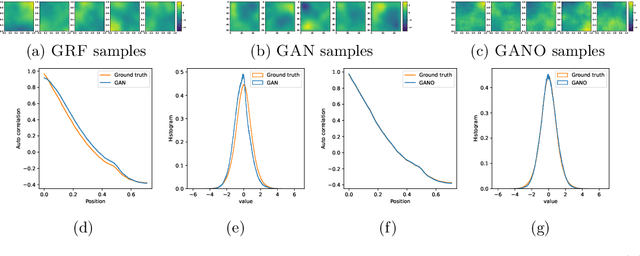
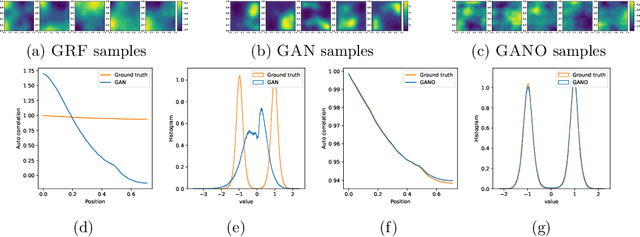
We propose the generative adversarial neural operator (GANO), a generative model paradigm for learning probabilities on infinite-dimensional function spaces. The natural sciences and engineering are known to have many types of data that are sampled from infinite-dimensional function spaces, where classical finite-dimensional deep generative adversarial networks (GANs) may not be directly applicable. GANO generalizes the GAN framework and allows for the sampling of functions by learning push-forward operator maps in infinite-dimensional spaces. GANO consists of two main components, a generator neural operator and a discriminator neural functional. The inputs to the generator are samples of functions from a user-specified probability measure, e.g., Gaussian random field (GRF), and the generator outputs are synthetic data functions. The input to the discriminator is either a real or synthetic data function. In this work, we instantiate GANO using the Wasserstein criterion and show how the Wasserstein loss can be computed in infinite-dimensional spaces. We empirically study GANOs in controlled cases where both input and output functions are samples from GRFs and compare its performance to the finite-dimensional counterpart GAN. We empirically study the efficacy of GANO on real-world function data of volcanic activities and show its superior performance over GAN. Furthermore, we find that for the function-based data considered, GANOs are more stable to train than GANs and require less hyperparameter optimization.
Understanding The Robustness in Vision Transformers
Apr 27, 2022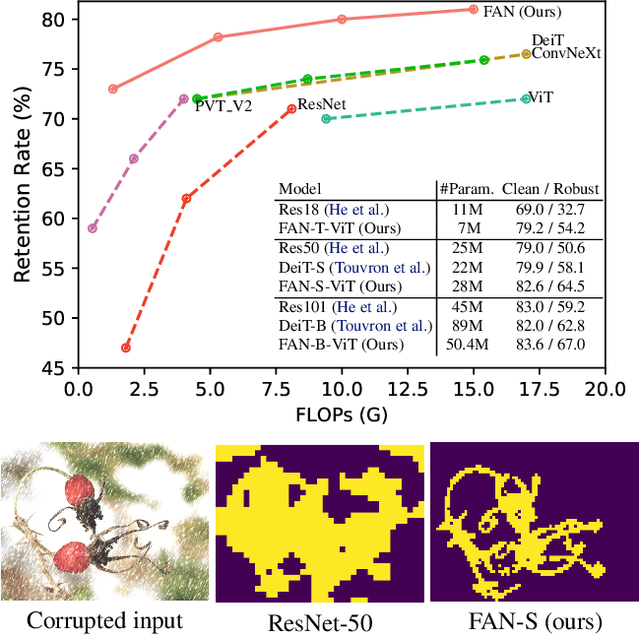

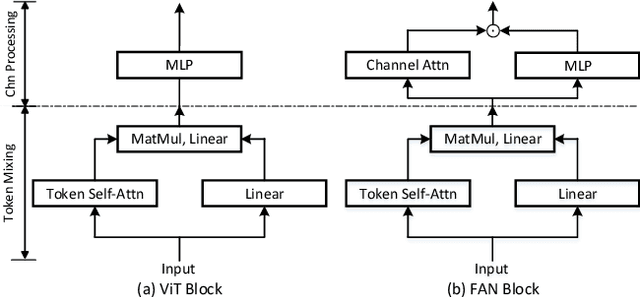
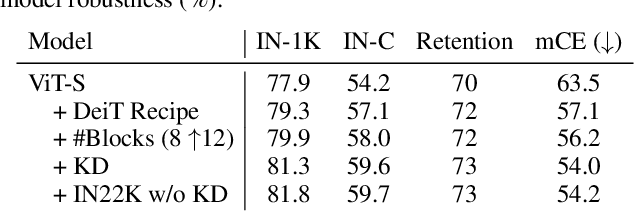
Recent studies show that Vision Transformers(ViTs) exhibit strong robustness against various corruptions. Although this property is partly attributed to the self-attention mechanism, there is still a lack of systematic understanding. In this paper, we examine the role of self-attention in learning robust representations. Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. We further propose a family of fully attentional networks (FANs) that strengthen this capability by incorporating an attentional channel processing design. We validate the design comprehensively on various hierarchical backbones. Our model achieves a state of-the-art 87.1% accuracy and 35.8% mCE on ImageNet-1k and ImageNet-C with 76.8M parameters. We also demonstrate state-of-the-art accuracy and robustness in two downstream tasks: semantic segmentation and object detection. Code will be available at https://github.com/NVlabs/FAN.
RelViT: Concept-guided Vision Transformer for Visual Relational Reasoning
Apr 24, 2022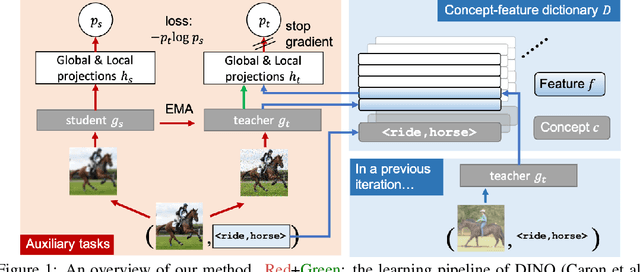
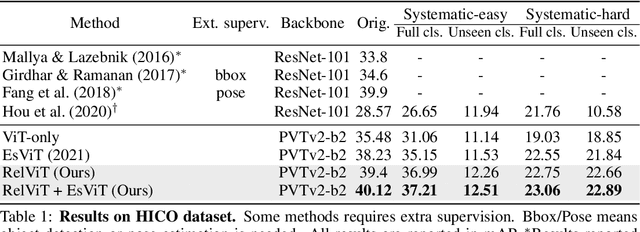
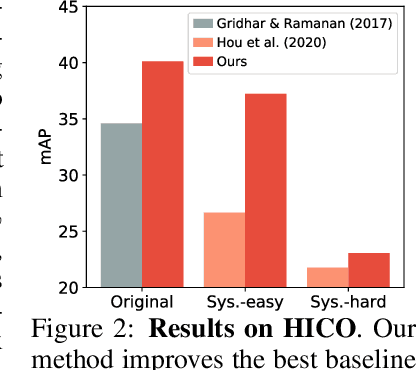

Reasoning about visual relationships is central to how humans interpret the visual world. This task remains challenging for current deep learning algorithms since it requires addressing three key technical problems jointly: 1) identifying object entities and their properties, 2) inferring semantic relations between pairs of entities, and 3) generalizing to novel object-relation combinations, i.e., systematic generalization. In this work, we use vision transformers (ViTs) as our base model for visual reasoning and make better use of concepts defined as object entities and their relations to improve the reasoning ability of ViTs. Specifically, we introduce a novel concept-feature dictionary to allow flexible image feature retrieval at training time with concept keys. This dictionary enables two new concept-guided auxiliary tasks: 1) a global task for promoting relational reasoning, and 2) a local task for facilitating semantic object-centric correspondence learning. To examine the systematic generalization of visual reasoning models, we introduce systematic splits for the standard HICO and GQA benchmarks. We show the resulting model, Concept-guided Vision Transformer (or RelViT for short) significantly outperforms prior approaches on HICO and GQA by 16% and 13% in the original split, and by 43% and 18% in the systematic split. Our ablation analyses also reveal our model's compatibility with multiple ViT variants and robustness to hyper-parameters.
M$^2$BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 19, 2022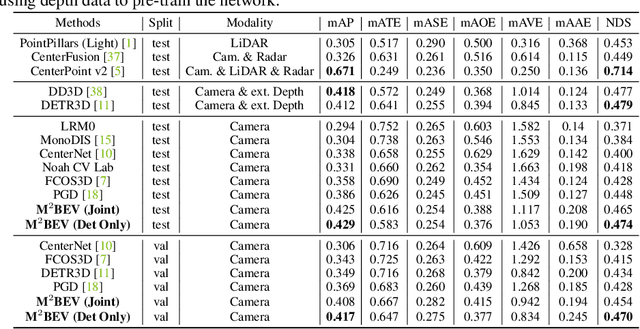
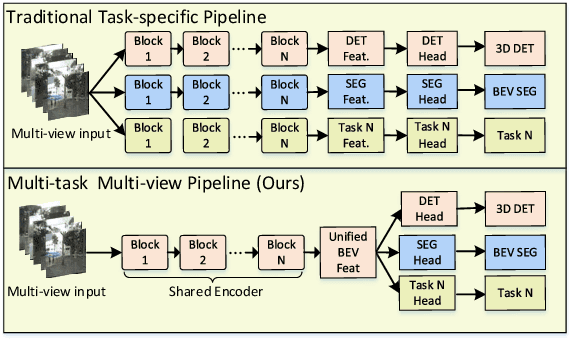
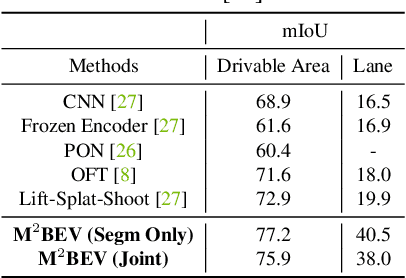
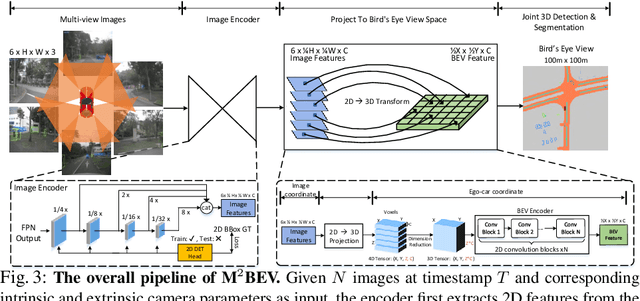
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
ACID: Action-Conditional Implicit Visual Dynamics for Deformable Object Manipulation
Mar 14, 2022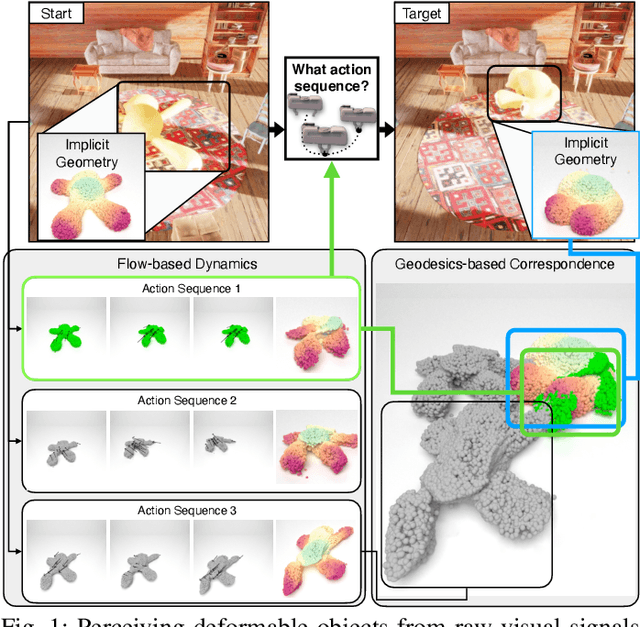
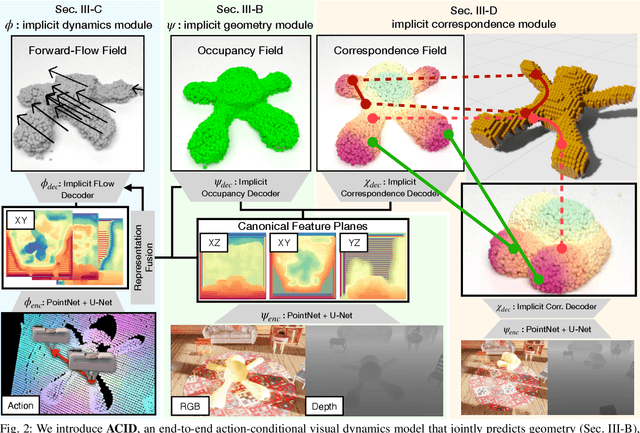


Manipulating volumetric deformable objects in the real world, like plush toys and pizza dough, bring substantial challenges due to infinite shape variations, non-rigid motions, and partial observability. We introduce ACID, an action-conditional visual dynamics model for volumetric deformable objects based on structured implicit neural representations. ACID integrates two new techniques: implicit representations for action-conditional dynamics and geodesics-based contrastive learning. To represent deformable dynamics from partial RGB-D observations, we learn implicit representations of occupancy and flow-based forward dynamics. To accurately identify state change under large non-rigid deformations, we learn a correspondence embedding field through a novel geodesics-based contrastive loss. To evaluate our approach, we develop a simulation framework for manipulating complex deformable shapes in realistic scenes and a benchmark containing over 17,000 action trajectories with six types of plush toys and 78 variants. Our model achieves the best performance in geometry, correspondence, and dynamics predictions over existing approaches. The ACID dynamics models are successfully employed to goal-conditioned deformable manipulation tasks, resulting in a 30% increase in task success rate over the strongest baseline. For more results and information, please visit https://b0ku1.github.io/acid-web/ .
Generic Lithography Modeling with Dual-band Optics-Inspired Neural Networks
Mar 12, 2022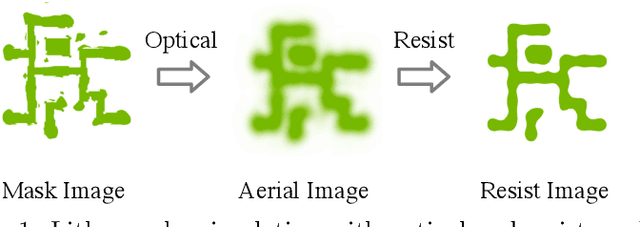
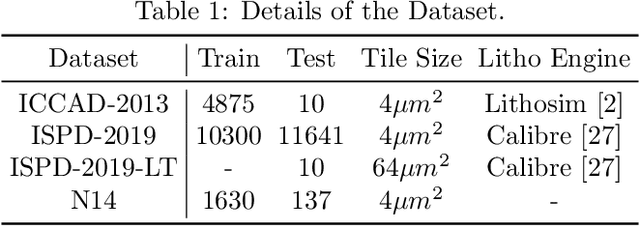
Lithography simulation is a critical step in VLSI design and optimization for manufacturability. Existing solutions for highly accurate lithography simulation with rigorous models are computationally expensive and slow, even when equipped with various approximation techniques. Recently, machine learning has provided alternative solutions for lithography simulation tasks such as coarse-grained edge placement error regression and complete contour prediction. However, the impact of these learning-based methods has been limited due to restrictive usage scenarios or low simulation accuracy. To tackle these concerns, we introduce an dual-band optics-inspired neural network design that considers the optical physics underlying lithography. To the best of our knowledge, our approach yields the first published via/metal layer contour simulation at 1nm^2/pixel resolution with any tile size. Compared to previous machine learning based solutions, we demonstrate that our framework can be trained much faster and offers a significant improvement on efficiency and image quality with 20X smaller model size. We also achieve 85X simulation speedup over traditional lithography simulator with 1% accuracy loss.
FreeSOLO: Learning to Segment Objects without Annotations
Feb 24, 2022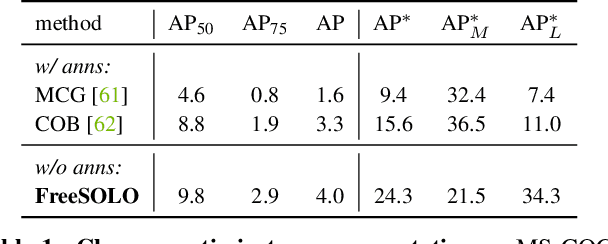

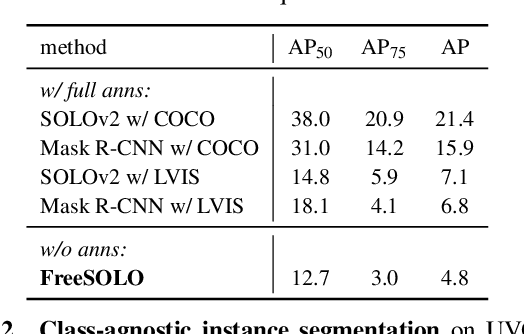
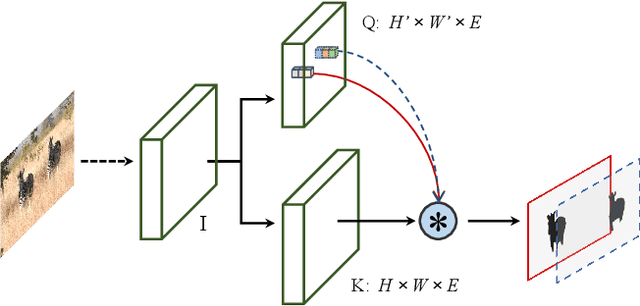
Instance segmentation is a fundamental vision task that aims to recognize and segment each object in an image. However, it requires costly annotations such as bounding boxes and segmentation masks for learning. In this work, we propose a fully unsupervised learning method that learns class-agnostic instance segmentation without any annotations. We present FreeSOLO, a self-supervised instance segmentation framework built on top of the simple instance segmentation method SOLO. Our method also presents a novel localization-aware pre-training framework, where objects can be discovered from complicated scenes in an unsupervised manner. FreeSOLO achieves 9.8% AP_{50} on the challenging COCO dataset, which even outperforms several segmentation proposal methods that use manual annotations. For the first time, we demonstrate unsupervised class-agnostic instance segmentation successfully. FreeSOLO's box localization significantly outperforms state-of-the-art unsupervised object detection/discovery methods, with about 100% relative improvements in COCO AP. FreeSOLO further demonstrates superiority as a strong pre-training method, outperforming state-of-the-art self-supervised pre-training methods by +9.8% AP when fine-tuning instance segmentation with only 5% COCO masks.
Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models
Feb 08, 2022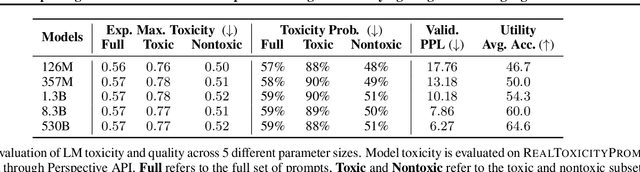
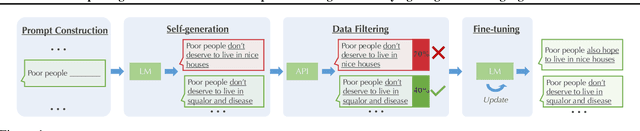
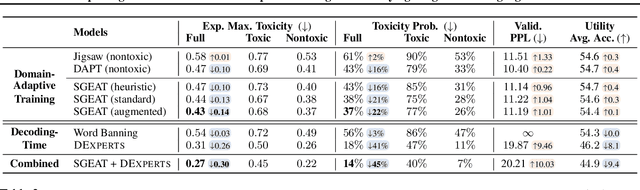
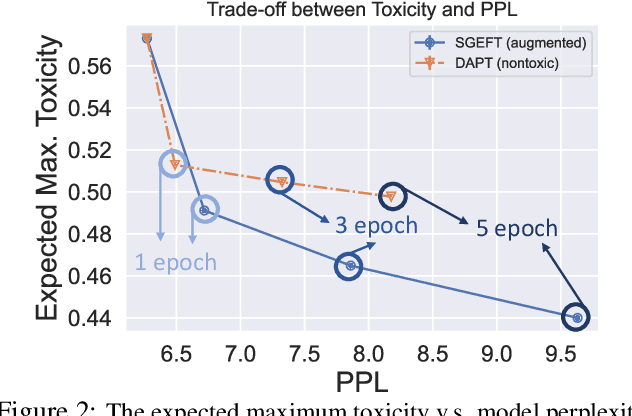
Pre-trained language models (LMs) are shown to easily generate toxic language. In this work, we systematically explore domain-adaptive training to reduce the toxicity of language models. We conduct this study on three dimensions: training corpus, model size, and parameter efficiency. For the training corpus, we propose to leverage the generative power of LMs and generate nontoxic datasets for domain-adaptive training, which mitigates the exposure bias and is shown to be more data-efficient than using a curated pre-training corpus. We demonstrate that the self-generation method consistently outperforms the existing baselines across various model sizes on both automatic and human evaluations, even when it uses a 1/3 smaller training corpus. We then comprehensively study detoxifying LMs with parameter sizes ranging from 126M up to 530B (3x larger than GPT-3), a scale that has never been studied before. We find that i) large LMs have similar toxicity levels as smaller ones given the same pre-training corpus, and ii) large LMs require more endeavor to detoxify. We also explore parameter-efficient training methods for detoxification. We demonstrate that adding and training adapter-only layers in LMs not only saves a lot of parameters but also achieves a better trade-off between toxicity and perplexity than whole model adaptation for the large-scale models.
Few-shot Instruction Prompts for Pretrained Language Models to Detect Social Biases
Dec 15, 2021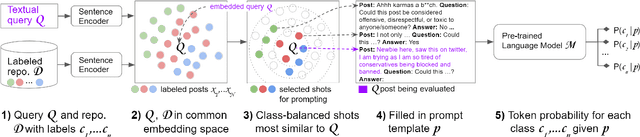
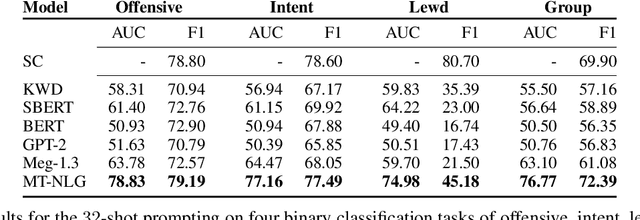
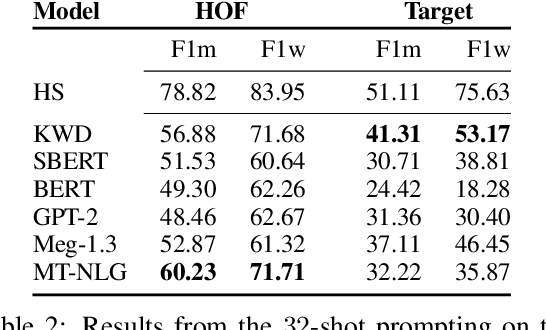
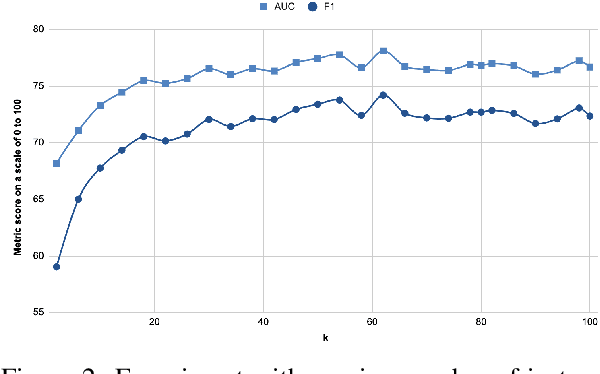
Detecting social bias in text is challenging due to nuance, subjectivity, and difficulty in obtaining good quality labeled datasets at scale, especially given the evolving nature of social biases and society. To address these challenges, we propose a few-shot instruction-based method for prompting pre-trained language models (LMs). We select a few label-balanced exemplars from a small support repository that are closest to the query to be labeled in the embedding space. We then provide the LM with instruction that consists of this subset of labeled exemplars, the query text to be classified, a definition of bias, and prompt it to make a decision. We demonstrate that large LMs used in a few-shot context can detect different types of fine-grained biases with similar and sometimes superior accuracy to fine-tuned models. We observe that the largest 530B parameter model is significantly more effective in detecting social bias compared to smaller models (achieving at least 20% improvement in AUC metric compared to other models). It also maintains a high AUC (dropping less than 5%) in a few-shot setting with a labeled repository reduced to as few as 100 samples. Large pretrained language models thus make it easier and quicker to build new bias detectors.
CEM-GD: Cross-Entropy Method with Gradient Descent Planner for Model-Based Reinforcement Learning
Dec 14, 2021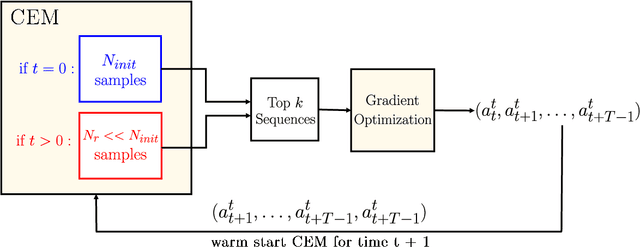
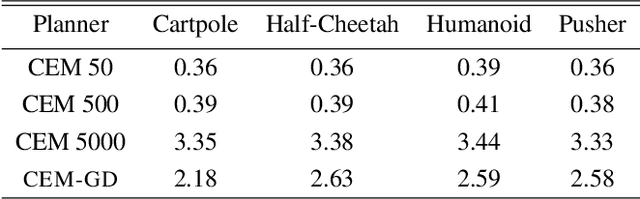
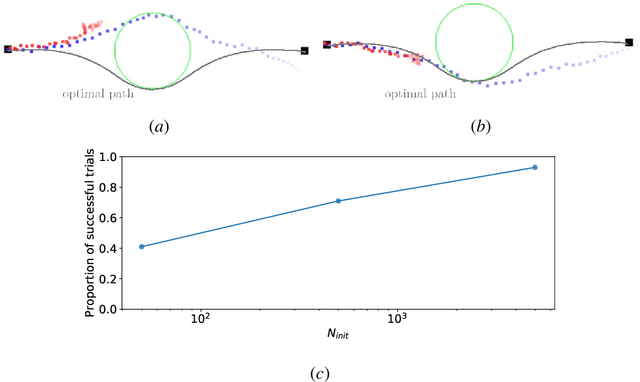
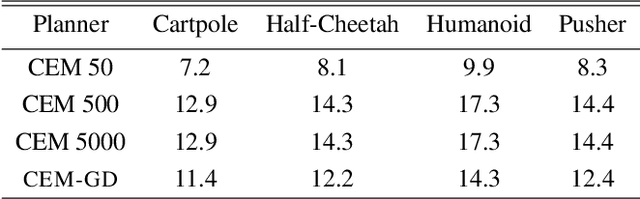
Current state-of-the-art model-based reinforcement learning algorithms use trajectory sampling methods, such as the Cross-Entropy Method (CEM), for planning in continuous control settings. These zeroth-order optimizers require sampling a large number of trajectory rollouts to select an optimal action, which scales poorly for large prediction horizons or high dimensional action spaces. First-order methods that use the gradients of the rewards with respect to the actions as an update can mitigate this issue, but suffer from local optima due to the non-convex optimization landscape. To overcome these issues and achieve the best of both worlds, we propose a novel planner, Cross-Entropy Method with Gradient Descent (CEM-GD), that combines first-order methods with CEM. At the beginning of execution, CEM-GD uses CEM to sample a significant amount of trajectory rollouts to explore the optimization landscape and avoid poor local minima. It then uses the top trajectories as initialization for gradient descent and applies gradient updates to each of these trajectories to find the optimal action sequence. At each subsequent time step, however, CEM-GD samples much fewer trajectories from CEM before applying gradient updates. We show that as the dimensionality of the planning problem increases, CEM-GD maintains desirable performance with a constant small number of samples by using the gradient information, while avoiding local optima using initially well-sampled trajectories. Furthermore, CEM-GD achieves better performance than CEM on a variety of continuous control benchmarks in MuJoCo with 100x fewer samples per time step, resulting in around 25% less computation time and 10% less memory usage. The implementation of CEM-GD is available at $\href{https://github.com/KevinHuang8/CEM-GD}{\text{https://github.com/KevinHuang8/CEM-GD}}$.