 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Random Features
Oct 13, 2021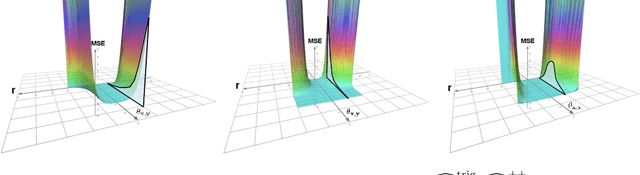
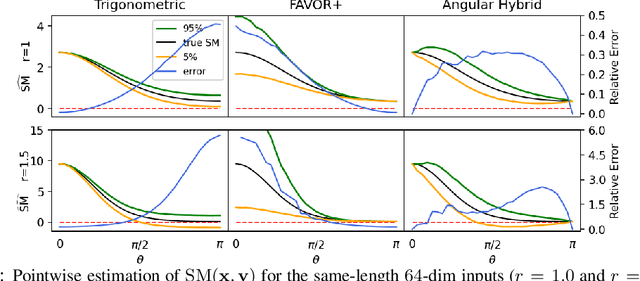
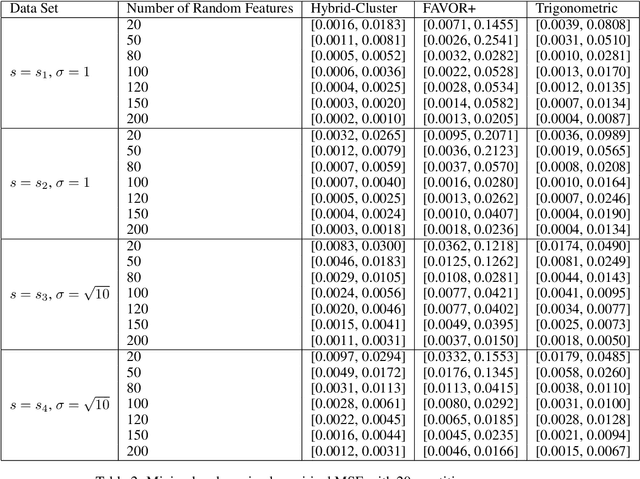
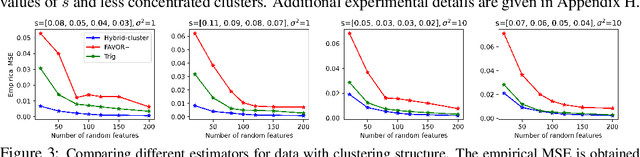
We propose a new class of random feature methods for linearizing softmax and Gaussian kernels called hybrid random features (HRFs) that automatically adapt the quality of kernel estimation to provide most accurate approximation in the defined regions of interest. Special instantiations of HRFs lead to well-known methods such as trigonometric (Rahimi and Recht, 2007) or (recently introduced in the context of linear-attention Transformers) positive random features (Choromanski et al., 2021). By generalizing Bochner's Theorem for softmax/Gaussian kernels and leveraging random features for compositional kernels, the HRF-mechanism provides strong theoretical guarantees - unbiased approximation and strictly smaller worst-case relative errors than its counterparts. We conduct exhaustive empirical evaluation of HRF ranging from pointwise kernel estimation experiments, through tests on data admitting clustering structure to benchmarking implicit-attention Transformers (also for downstream Robotics applications), demonstrating its quality in a wide spectrum of machine learning problems.
Multi-Task Learning with Sequence-Conditioned Transporter Networks
Sep 15, 2021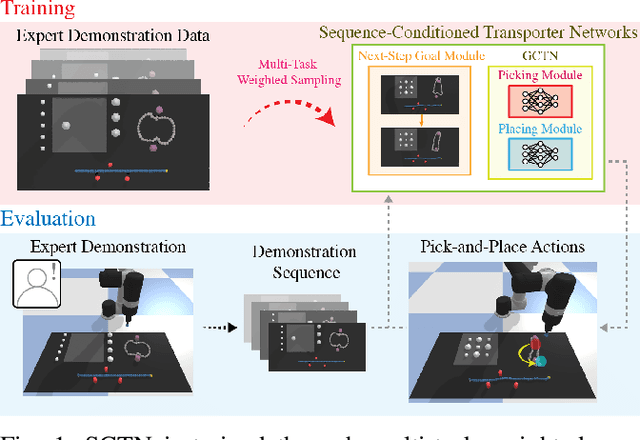
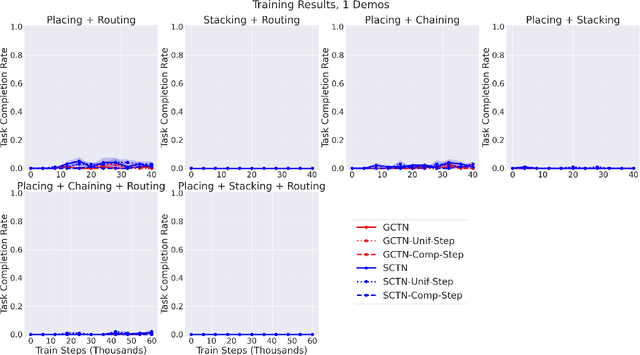
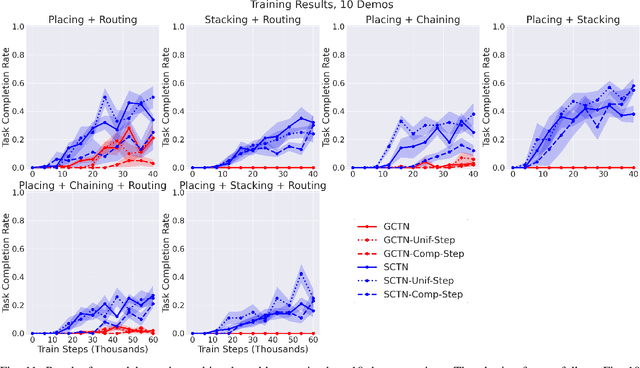
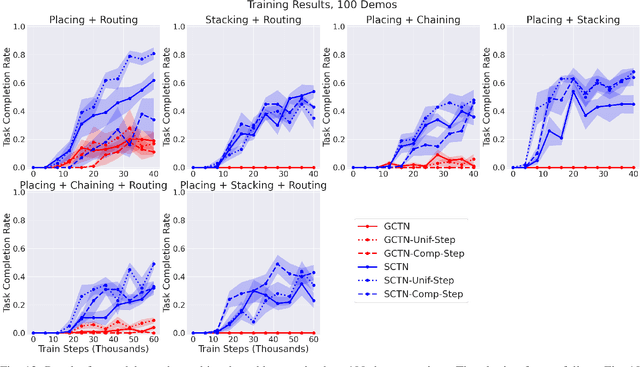
Enabling robots to solve multiple manipulation tasks has a wide range of industrial applications. While learning-based approaches enjoy flexibility and generalizability, scaling these approaches to solve such compositional tasks remains a challenge. In this work, we aim to solve multi-task learning through the lens of sequence-conditioning and weighted sampling. First, we propose a new suite of benchmark specifically aimed at compositional tasks, MultiRavens, which allows defining custom task combinations through task modules that are inspired by industrial tasks and exemplify the difficulties in vision-based learning and planning methods. Second, we propose a vision-based end-to-end system architecture, Sequence-Conditioned Transporter Networks, which augments Goal-Conditioned Transporter Networks with sequence-conditioning and weighted sampling and can efficiently learn to solve multi-task long horizon problems. Our analysis suggests that not only the new framework significantly improves pick-and-place performance on novel 10 multi-task benchmark problems, but also the multi-task learning with weighted sampling can vastly improve learning and agent performances on individual tasks.
Implicit Behavioral Cloning
Sep 01, 2021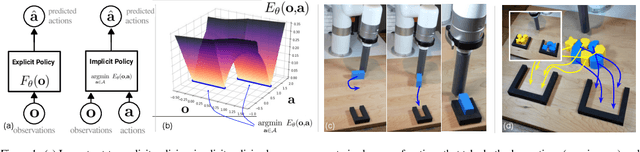

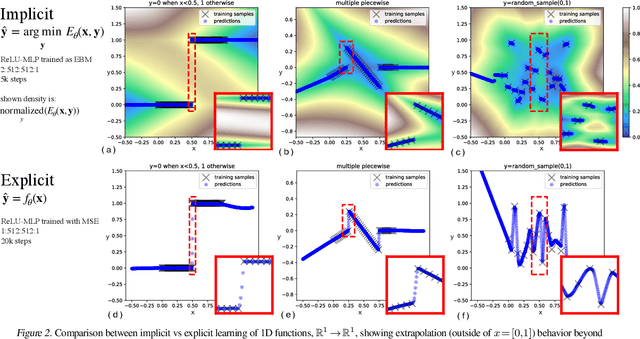
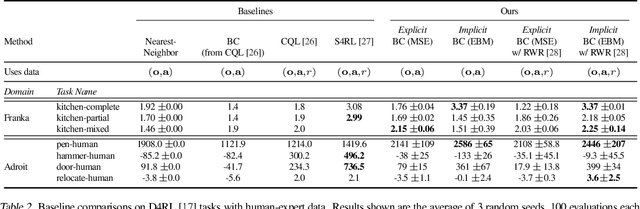
We find that across a wide range of robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used explicit models. We present extensive experiments on this finding, and we provide both intuitive insight and theoretical arguments distinguishing the properties of implicit models compared to their explicit counterparts, particularly with respect to approximating complex, potentially discontinuous and multi-valued (set-valued) functions. On robotic policy learning tasks we show that implicit behavioral cloning policies with energy-based models (EBM) often outperform common explicit (Mean Square Error, or Mixture Density) behavioral cloning policies, including on tasks with high-dimensional action spaces and visual image inputs. We find these policies provide competitive results or outperform state-of-the-art offline reinforcement learning methods on the challenging human-expert tasks from the D4RL benchmark suite, despite using no reward information. In the real world, robots with implicit policies can learn complex and remarkably subtle behaviors on contact-rich tasks from human demonstrations, including tasks with high combinatorial complexity and tasks requiring 1mm precision.
Learning to See before Learning to Act: Visual Pre-training for Manipulation
Jul 01, 2021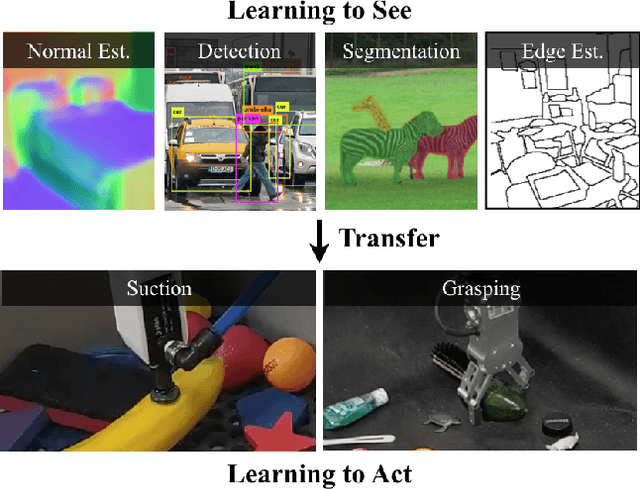

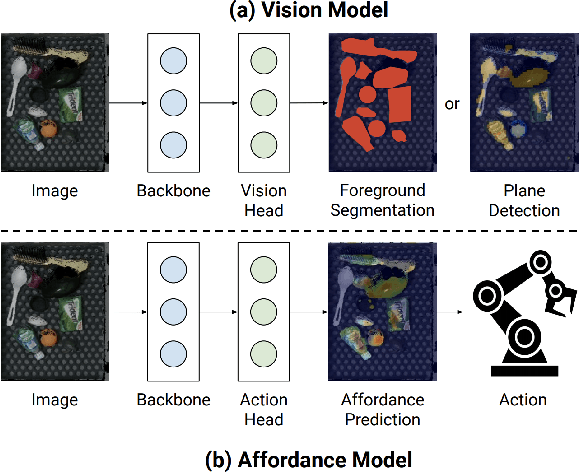

Does having visual priors (e.g. the ability to detect objects) facilitate learning to perform vision-based manipulation (e.g. picking up objects)? We study this problem under the framework of transfer learning, where the model is first trained on a passive vision task, and adapted to perform an active manipulation task. We find that pre-training on vision tasks significantly improves generalization and sample efficiency for learning to manipulate objects. However, realizing these gains requires careful selection of which parts of the model to transfer. Our key insight is that outputs of standard vision models highly correlate with affordance maps commonly used in manipulation. Therefore, we explore directly transferring model parameters from vision networks to affordance prediction networks, and show that this can result in successful zero-shot adaptation, where a robot can pick up certain objects with zero robotic experience. With just a small amount of robotic experience, we can further fine-tune the affordance model to achieve better results. With just 10 minutes of suction experience or 1 hour of grasping experience, our method achieves ~80% success rate at picking up novel objects.
XIRL: Cross-embodiment Inverse Reinforcement Learning
Jun 07, 2021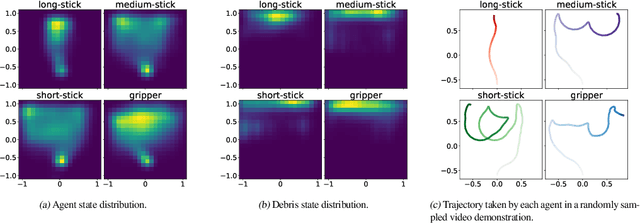

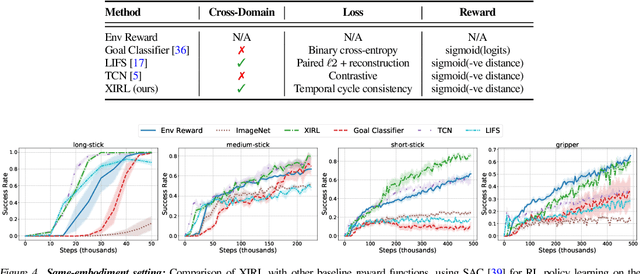
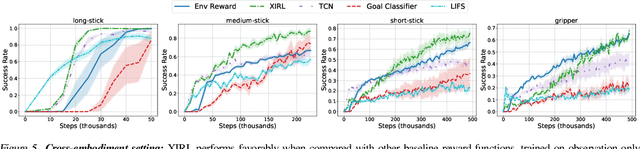
We investigate the visual cross-embodiment imitation setting, in which agents learn policies from videos of other agents (such as humans) demonstrating the same task, but with stark differences in their embodiments -- shape, actions, end-effector dynamics, etc. In this work, we demonstrate that it is possible to automatically discover and learn vision-based reward functions from cross-embodiment demonstration videos that are robust to these differences. Specifically, we present a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle-consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences. Prior to our work, producing rewards from self-supervised embeddings has typically required alignment with a reference trajectory, which may be difficult to acquire. We show empirically that if the embeddings are aware of task-progress, simply taking the negative distance between the current state and goal state in the learned embedding space is useful as a reward for training policies with reinforcement learning. We find our learned reward function not only works for embodiments seen during training, but also generalizes to entirely new embodiments. We also find that XIRL policies are more sample efficient than baselines, and in some cases exceed the sample efficiency of the same agent trained with ground truth sparse rewards.
Spatial Intention Maps for Multi-Agent Mobile Manipulation
Mar 23, 2021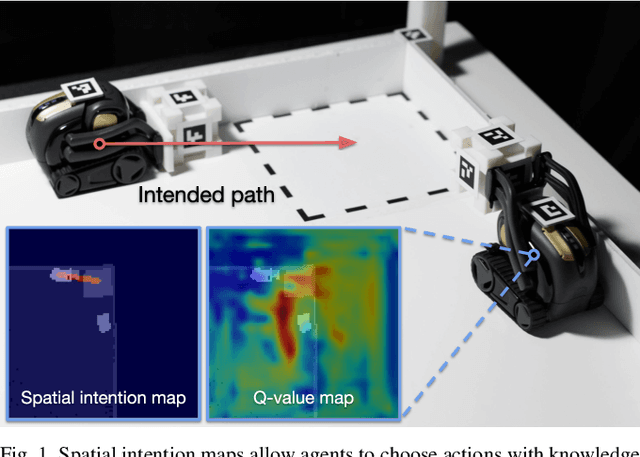
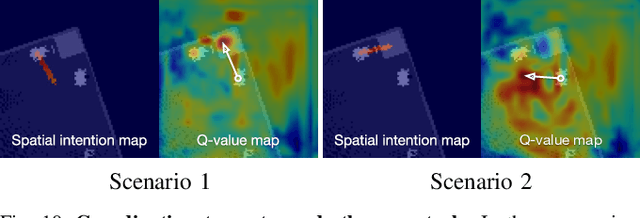
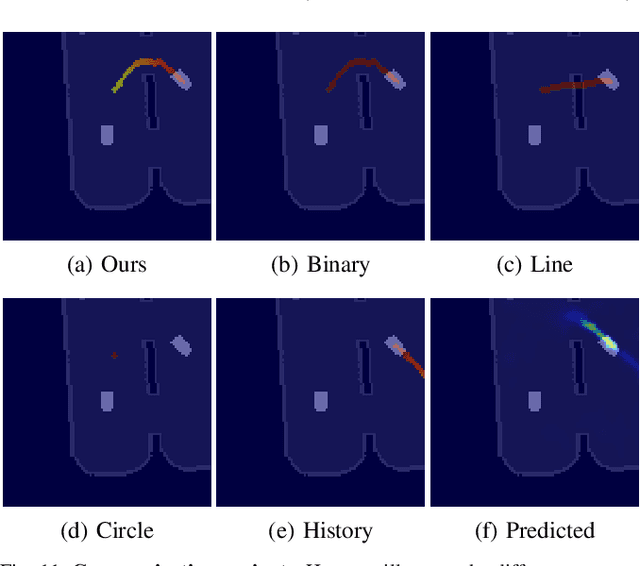
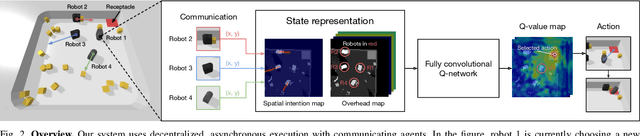
The ability to communicate intention enables decentralized multi-agent robots to collaborate while performing physical tasks. In this work, we present spatial intention maps, a new intention representation for multi-agent vision-based deep reinforcement learning that improves coordination between decentralized mobile manipulators. In this representation, each agent's intention is provided to other agents, and rendered into an overhead 2D map aligned with visual observations. This synergizes with the recently proposed spatial action maps framework, in which state and action representations are spatially aligned, providing inductive biases that encourage emergent cooperative behaviors requiring spatial coordination, such as passing objects to each other or avoiding collisions. Experiments across a variety of multi-agent environments, including heterogeneous robot teams with different abilities (lifting, pushing, or throwing), show that incorporating spatial intention maps improves performance for different mobile manipulation tasks while significantly enhancing cooperative behaviors.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020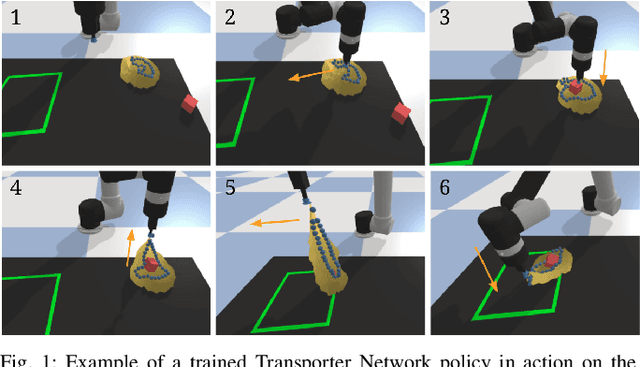
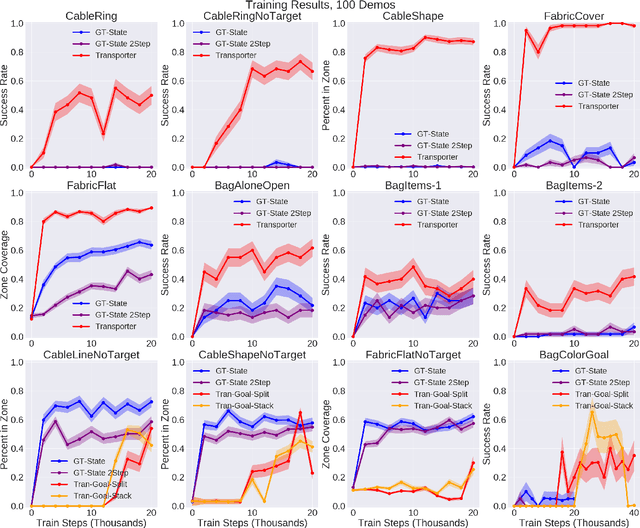
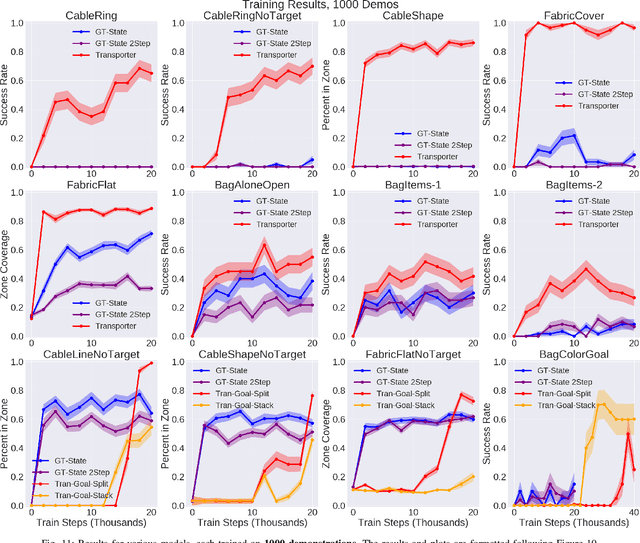
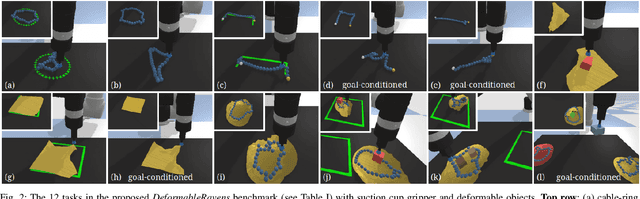
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Oct 27, 2020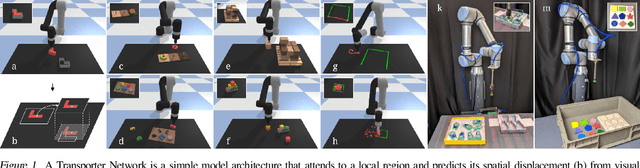
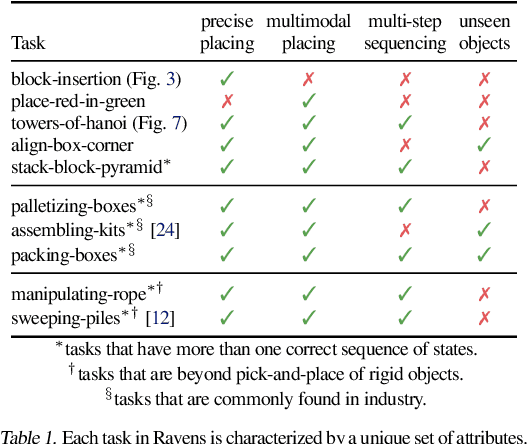
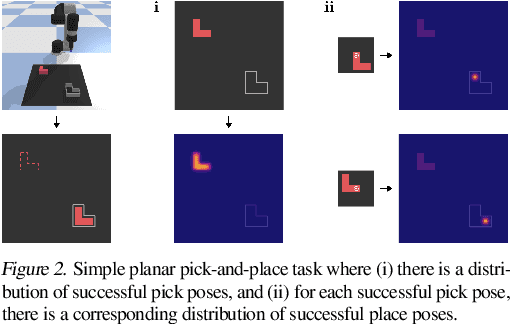
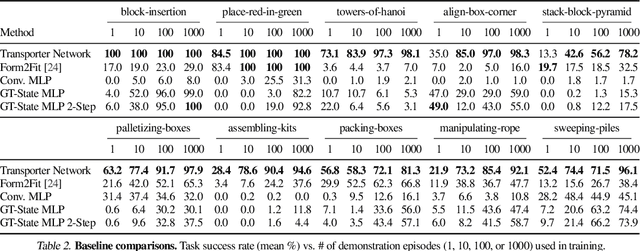
Robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass an object, part of an object, or end effector. In this work, we propose the Transporter Network, a simple model architecture that rearranges deep features to infer spatial displacements from visual input - which can parameterize robot actions. It makes no assumptions of objectness (e.g. canonical poses, models, or keypoints), it exploits spatial symmetries, and is orders of magnitude more sample efficient than our benchmarked alternatives in learning vision-based manipulation tasks: from stacking a pyramid of blocks, to assembling kits with unseen objects; from manipulating deformable ropes, to pushing piles of small objects with closed-loop feedback. Our method can represent complex multi-modal policy distributions and generalizes to multi-step sequential tasks, as well as 6DoF pick-and-place. Experiments on 10 simulated tasks show that it learns faster and generalizes better than a variety of end-to-end baselines, including policies that use ground-truth object poses. We validate our methods with hardware in the real world. Experiment videos and code will be made available at https://transporternets.github.io
Spatial Action Maps for Mobile Manipulation
Apr 20, 2020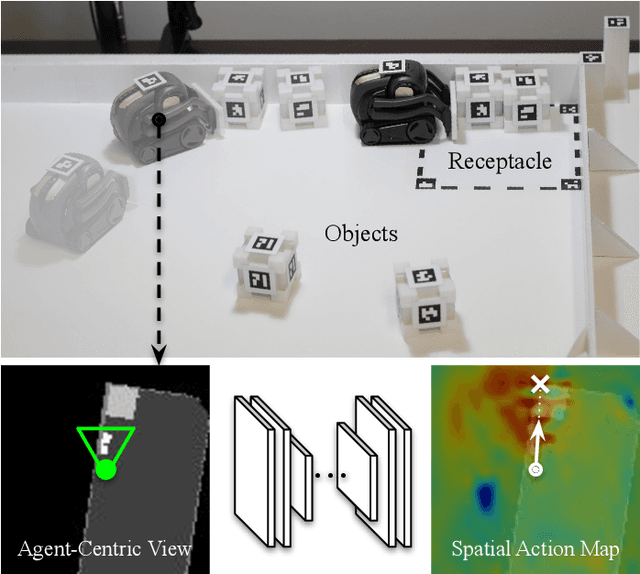


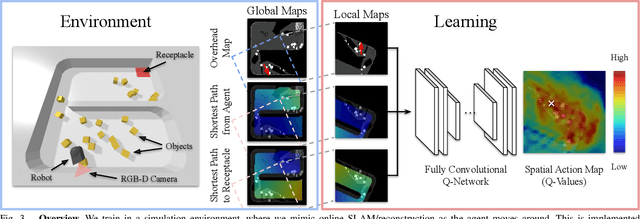
This paper proposes a new action representation for learning to perform complex mobile manipulation tasks. In a typical deep Q-learning setup, a convolutional neural network (ConvNet) is trained to map from an image representing the current state (e.g., a birds-eye view of a SLAM reconstruction of the scene) to predicted Q-values for a small set of steering command actions (step forward, turn right, turn left, etc.). Instead, we propose an action representation in the same domain as the state: "spatial action maps." In our proposal, the set of possible actions is represented by pixels of an image, where each pixel represents a trajectory to the corresponding scene location along a shortest path through obstacles of the partially reconstructed scene. A significant advantage of this approach is that the spatial position of each state-action value prediction represents a local milestone (local end-point) for the agent's policy, which may be easily recognizable in local visual patterns of the state image. A second advantage is that atomic actions can perform long-range plans (follow the shortest path to a point on the other side of the scene), and thus it is simpler to learn complex behaviors with a deep Q-network. A third advantage is that we can use a fully convolutional network (FCN) with skip connections to learn the mapping from state images to pixel-aligned action images efficiently. During experiments with a robot that learns to push objects to a goal location, we find that policies learned with this proposed action representation achieve significantly better performance than traditional alternatives.
Grasping in the Wild:Learning 6DoF Closed-Loop Grasping from Low-Cost Demonstrations
Dec 09, 2019
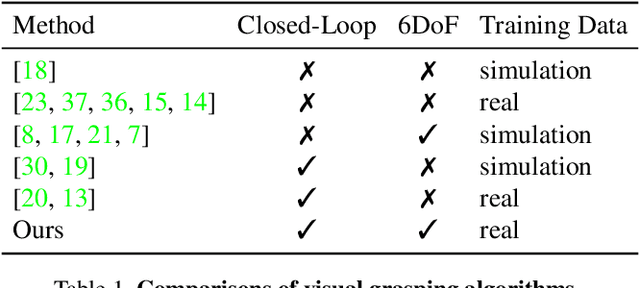
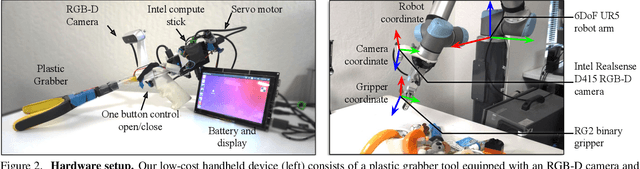

Intelligent manipulation benefits from the capacity to flexibly control an end-effector with high degrees of freedom (DoF) and dynamically react to the environment. However, due to the challenges of collecting effective training data and learning efficiently, most grasping algorithms today are limited to top-down movements and open-loop execution. In this work, we propose a new low-cost hardware interface for collecting grasping demonstrations by people in diverse environments. Leveraging this data, we show that it is possible to train a robust end-to-end 6DoF closed-loop grasping model with reinforcement learning that transfers to real robots. A key aspect of our grasping model is that it uses ``action-view'' based rendering to simulate future states with respect to different possible actions. By evaluating these states using a learned value function (Q-function), our method is able to better select corresponding actions that maximize total rewards (i.e., grasping success). Our final grasping system is able to achieve reliable 6DoF closed-loop grasping of novel objects across various scene configurations, as well as dynamic scenes with moving objects.