 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould you give me a hint? Generating inference graphs for defeasible reasoning
May 29, 2021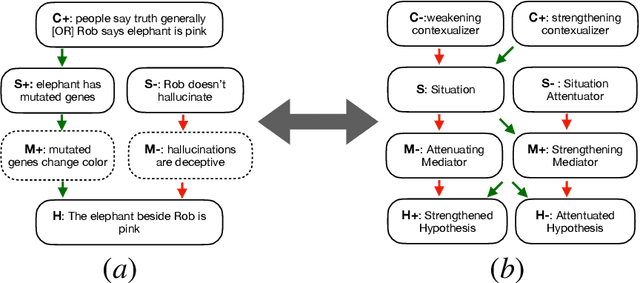

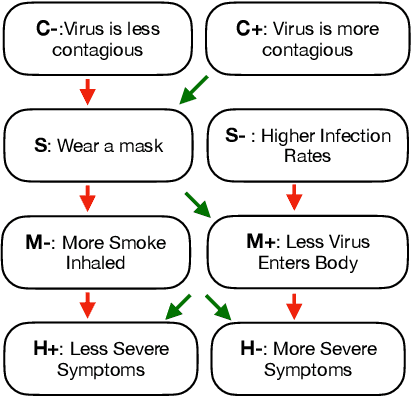

Defeasible reasoning is the mode of reasoning where conclusions can be overturned by taking into account new evidence. A commonly used method in cognitive science and logic literature is to handcraft argumentation supporting inference graphs. While humans find inference graphs very useful for reasoning, constructing them at scale is difficult. In this paper, we automatically generate such inference graphs through transfer learning from another NLP task that shares the kind of reasoning that inference graphs support. Through automated metrics and human evaluation, we find that our method generates meaningful graphs for the defeasible inference task. Human accuracy on this task improves by 20% by consulting the generated graphs. Our findings open up exciting new research avenues for cases where machine reasoning can help human reasoning. (A dataset of 230,000 influence graphs for each defeasible query is located at: https://tinyurl.com/defeasiblegraphs.)
Improving Neural Model Performance through Natural Language Feedback on Their Explanations
Apr 18, 2021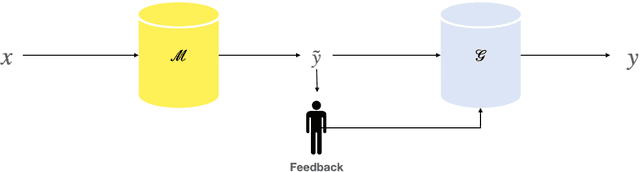
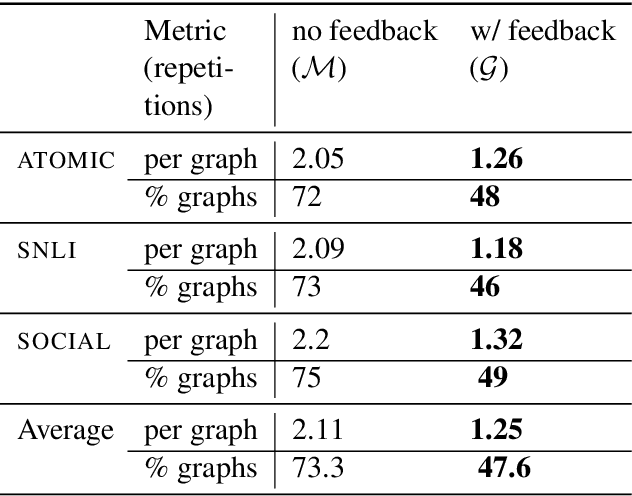
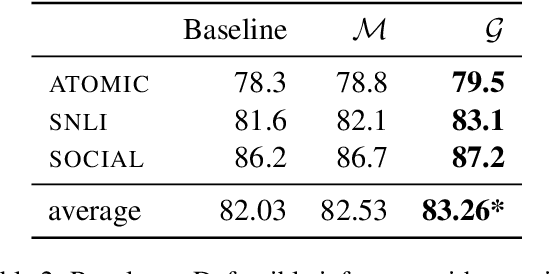
A class of explainable NLP models for reasoning tasks support their decisions by generating free-form or structured explanations, but what happens when these supporting structures contain errors? Our goal is to allow users to interactively correct explanation structures through natural language feedback. We introduce MERCURIE - an interactive system that refines its explanations for a given reasoning task by getting human feedback in natural language. Our approach generates graphs that have 40% fewer inconsistencies as compared with the off-the-shelf system. Further, simply appending the corrected explanation structures to the output leads to a gain of 1.2 points on accuracy on defeasible reasoning across all three domains. We release a dataset of over 450k graphs for defeasible reasoning generated by our system at https://tinyurl.com/mercurie .
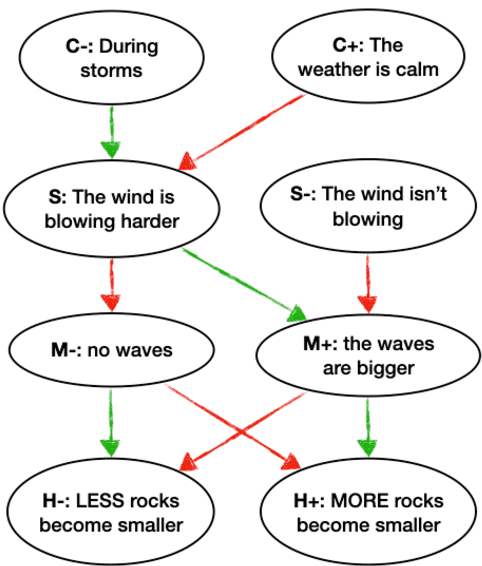
CURIE: An Iterative Querying Approach for Reasoning About Situations
Apr 05, 2021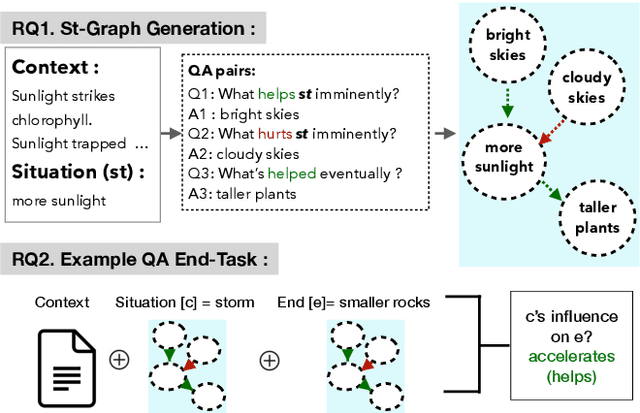
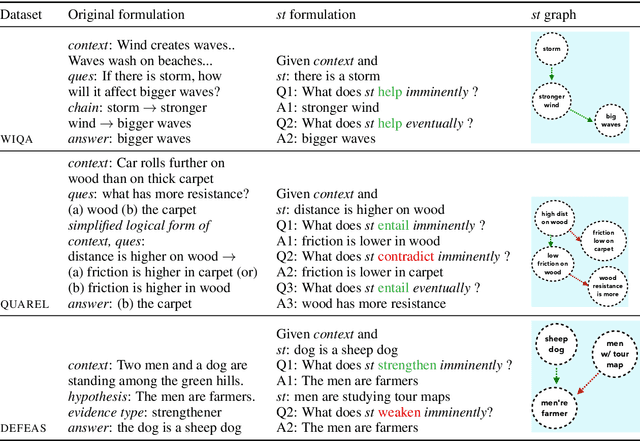
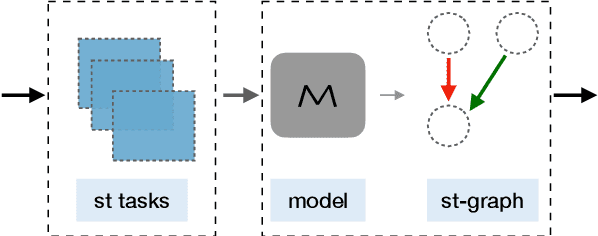
Recently, models have been shown to predict the effects of unexpected situations, e.g., would cloudy skies help or hinder plant growth? Given a context, the goal of such situational reasoning is to elicit the consequences of a new situation (st) that arises in that context. We propose a method to iteratively build a graph of relevant consequences explicitly in a structured situational graph (st-graph) using natural language queries over a finetuned language model (M). Across multiple domains, CURIE generates st-graphs that humans find relevant and meaningful in eliciting the consequences of a new situation. We show that st-graphs generated by CURIE improve a situational reasoning end task (WIQA-QA) by 3 points on accuracy by simply augmenting their input with our generated situational graphs, especially for a hard subset that requires background knowledge and multi-hop reasoning.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
EIGEN: Event Influence GENeration using Pre-trained Language Models
Oct 22, 2020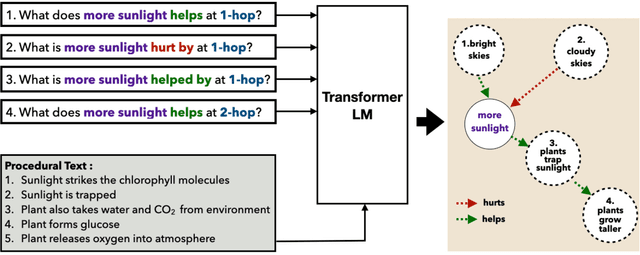
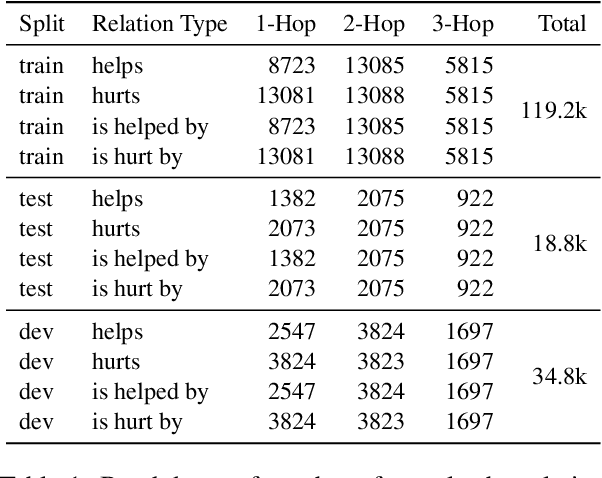

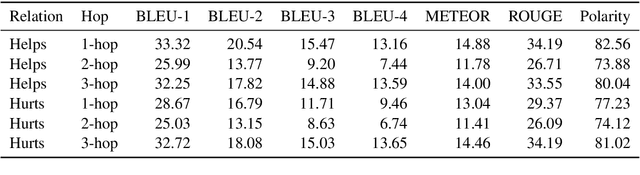
Reasoning about events and tracking their influences is fundamental to understanding processes. In this paper, we present EIGEN - a method to leverage pre-trained language models to generate event influences conditioned on a context, nature of their influence, and the distance in a reasoning chain. We also derive a new dataset for research and evaluation of methods for event influence generation. EIGEN outperforms strong baselines both in terms of automated evaluation metrics (by 10 ROUGE points) and human judgments on closeness to reference and relevance of generations. Furthermore, we show that the event influences generated by EIGEN improve the performance on a "what-if" Question Answering (WIQA) benchmark (over 3% F1), especially for questions that require background knowledge and multi-hop reasoning.
Neural Language Modeling for Contextualized Temporal Graph Generation
Oct 20, 2020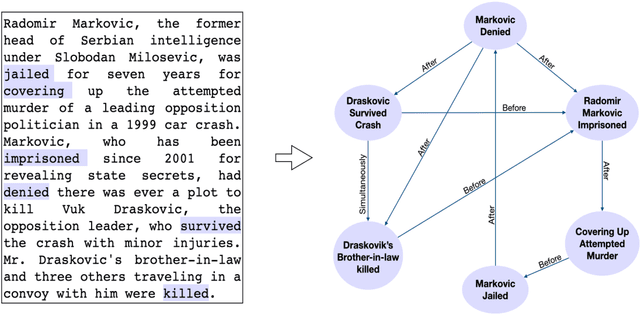
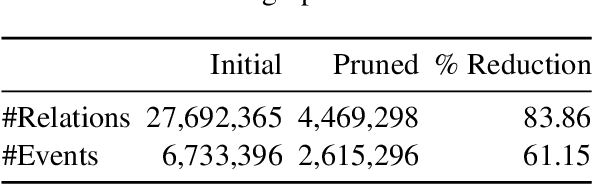
This paper presents the first study on using large-scale pre-trained language models for automated generation of an event-level temporal graph for a document. Despite the huge success of neural pre-training methods in NLP tasks, its potential for temporal reasoning over event graphs has not been sufficiently explored. Part of the reason is the difficulty in obtaining large training corpora with human-annotated events and temporal links. We address this challenge by using existing IE/NLP tools to automatically generate a large quantity (89,000) of system-produced document-graph pairs, and propose a novel formulation of the contextualized graph generation problem as a sequence-to-sequence mapping task. These strategies enable us to leverage and fine-tune pre-trained language models on the system-induced training data for the graph generation task. Our experiments show that our approach is highly effective in generating structurally and semantically valid graphs. Further, evaluation on a challenging hand-labeled, out-domain corpus shows that our method outperforms the closest existing method by a large margin on several metrics. Code and pre-trained models are available at https://github.com/madaan/temporal-graph-gen.
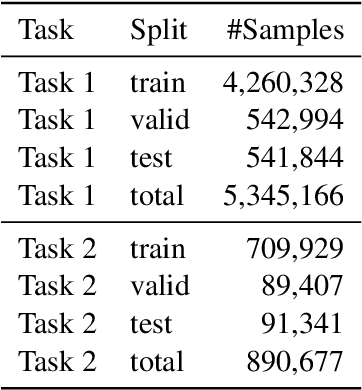
Politeness Transfer: A Tag and Generate Approach
May 01, 2020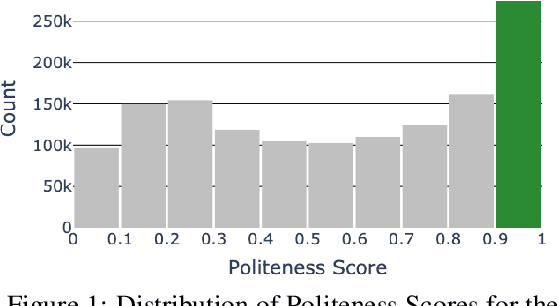
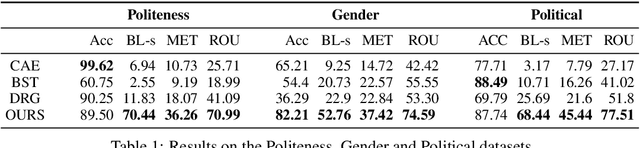
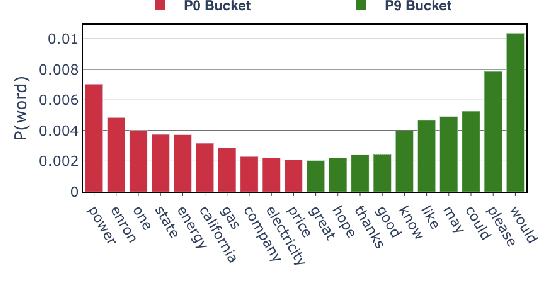

This paper introduces a new task of politeness transfer which involves converting non-polite sentences to polite sentences while preserving the meaning. We also provide a dataset of more than 1.39 instances automatically labeled for politeness to encourage benchmark evaluations on this new task. We design a tag and generate pipeline that identifies stylistic attributes and subsequently generates a sentence in the target style while preserving most of the source content. For politeness as well as five other transfer tasks, our model outperforms the state-of-the-art methods on automatic metrics for content preservation, with a comparable or better performance on style transfer accuracy. Additionally, our model surpasses existing methods on human evaluations for grammaticality, meaning preservation and transfer accuracy across all the six style transfer tasks. The data and code is located at https://github.com/tag-and-generate.
Practical Comparable Data Collection for Low-Resource Languages via Images
Apr 28, 2020
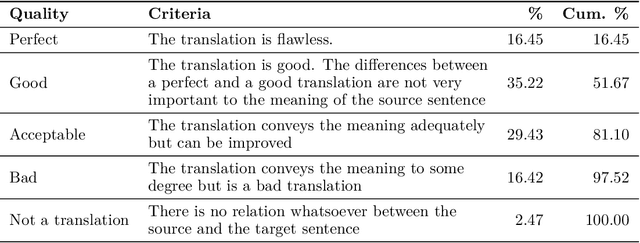

We propose a method of curating high-quality comparable training data for low-resource languages with monolingual annotators. Our method involves using a carefully selected set of images as a pivot between the source and target languages by getting captions for such images in both languages independently. Human evaluations on the English-Hindi comparable corpora created with our method show that 81.1% of the pairs are acceptable translations, and only 2.47% of the pairs are not translations at all. We further establish the potential of the dataset collected through our approach by experimenting on two downstream tasks - machine translation and dictionary extraction. All code and data are available at https://github.com/madaan/PML4DC-Comparable-Data-Collection.
Occurrence Statistics of Entities, Relations and Types on the Web
May 14, 2016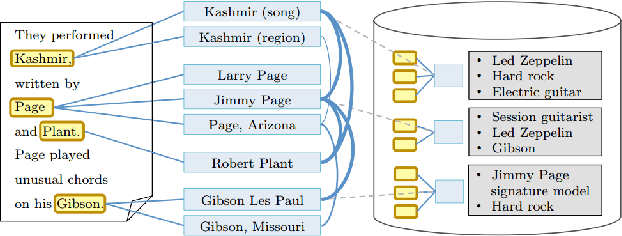
The problem of collecting reliable estimates of occurrence of entities on the open web forms the premise for this report. The models learned for tagging entities cannot be expected to perform well when deployed on the web. This is owing to the severe mismatch in the distributions of such entities on the web and in the relatively diminutive training data. In this report, we build up the case for maximum mean discrepancy for estimation of occurrence statistics of entities on the web, taking a review of named entity disambiguation techniques and related concepts along the way.