 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MAKE: Product Retrieval with Vision-Language Pre-training in Taobao Search
Jan 30, 2023

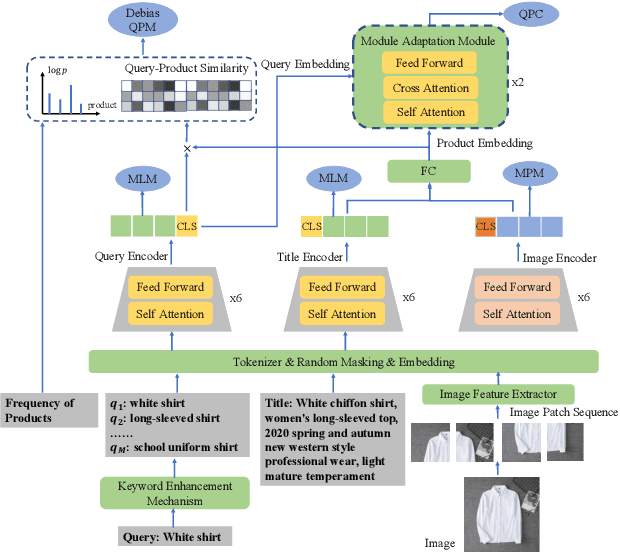
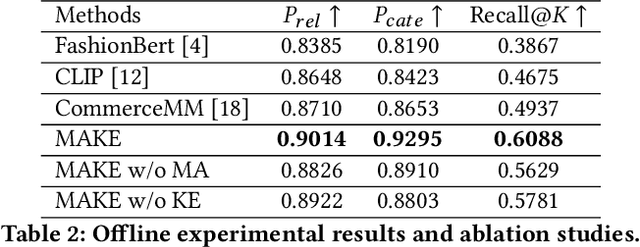
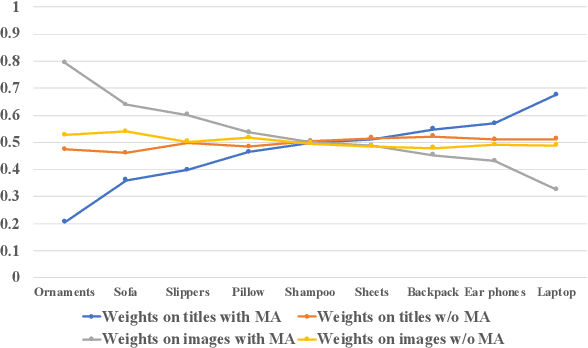
Taobao Search consists of two phases: the retrieval phase and the ranking phase. Given a user query, the retrieval phase returns a subset of candidate products for the following ranking phase. Recently, the paradigm of pre-training and fine-tuning has shown its potential in incorporating visual clues into retrieval tasks. In this paper, we focus on solving the problem of text-to-multimodal retrieval in Taobao Search. We consider that users' attention on titles or images varies on products. Hence, we propose a novel Modal Adaptation module for cross-modal fusion, which helps assigns appropriate weights on texts and images across products. Furthermore, in e-commerce search, user queries tend to be brief and thus lead to significant semantic imbalance between user queries and product titles. Therefore, we design a separate text encoder and a Keyword Enhancement mechanism to enrich the query representations and improve text-to-multimodal matching. To this end, we present a novel vision-language (V+L) pre-training methods to exploit the multimodal information of (user query, product title, product image). Extensive experiments demonstrate that our retrieval-specific pre-training model (referred to as MAKE) outperforms existing V+L pre-training methods on the text-to-multimodal retrieval task. MAKE has been deployed online and brings major improvements on the retrieval system of Taobao Search.
AgAsk: An Agent to Help Answer Farmer's Questions From Scientific Documents
Dec 21, 2022

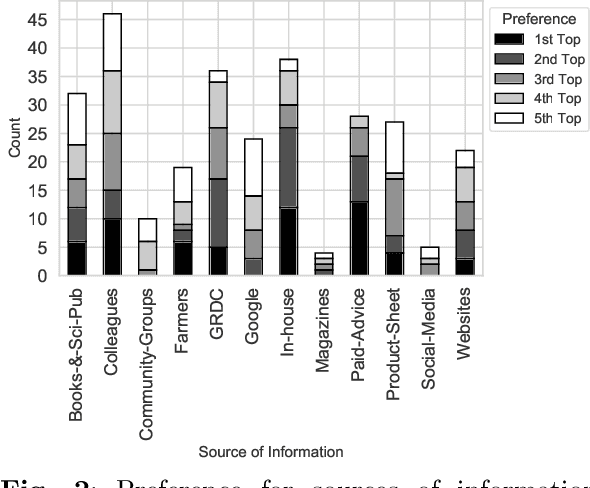
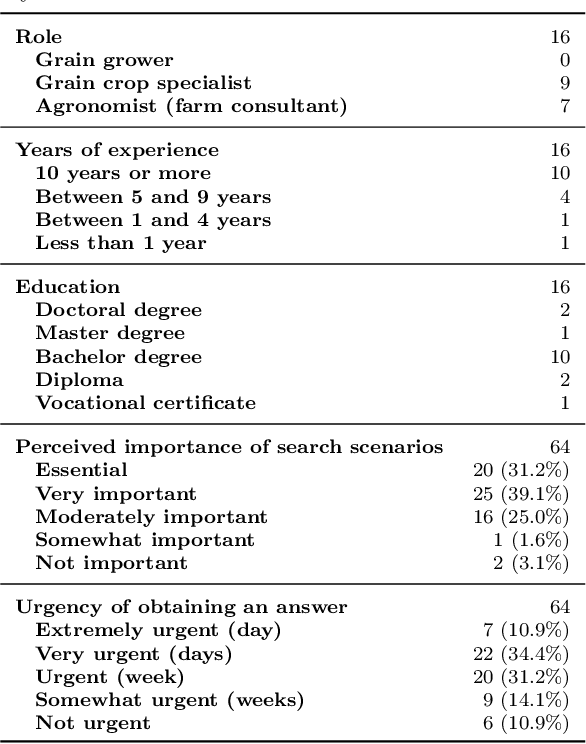
Decisions in agriculture are increasingly data-driven; however, valuable agricultural knowledge is often locked away in free-text reports, manuals and journal articles. Specialised search systems are needed that can mine agricultural information to provide relevant answers to users' questions. This paper presents AgAsk -- an agent able to answer natural language agriculture questions by mining scientific documents. We carefully survey and analyse farmers' information needs. On the basis of these needs we release an information retrieval test collection comprising real questions, a large collection of scientific documents split in passages, and ground truth relevance assessments indicating which passages are relevant to each question. We implement and evaluate a number of information retrieval models to answer farmers questions, including two state-of-the-art neural ranking models. We show that neural rankers are highly effective at matching passages to questions in this context. Finally, we propose a deployment architecture for AgAsk that includes a client based on the Telegram messaging platform and retrieval model deployed on commodity hardware. The test collection we provide is intended to stimulate more research in methods to match natural language to answers in scientific documents. While the retrieval models were evaluated in the agriculture domain, they are generalisable and of interest to others working on similar problems. The test collection is available at: \url{https://github.com/ielab/agvaluate}.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022



We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
Deep-Learning Tool for Early Identifying Non-Traumatic Intracranial Hemorrhage Etiology based on CT Scan
Feb 02, 2023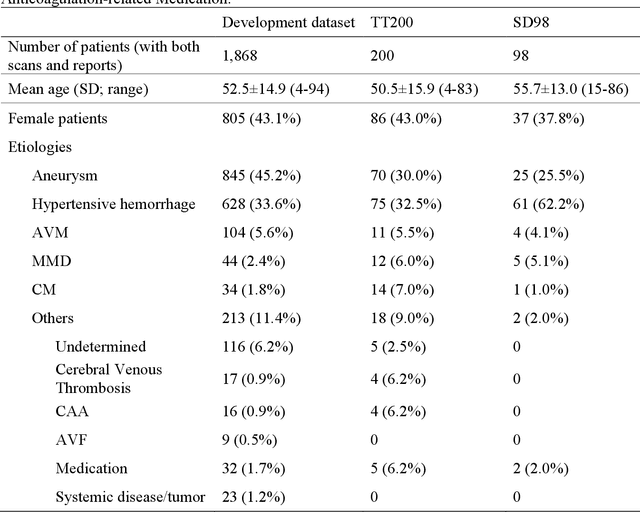
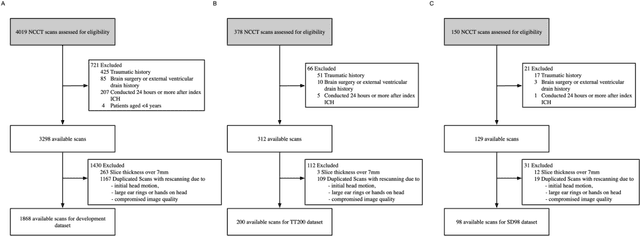
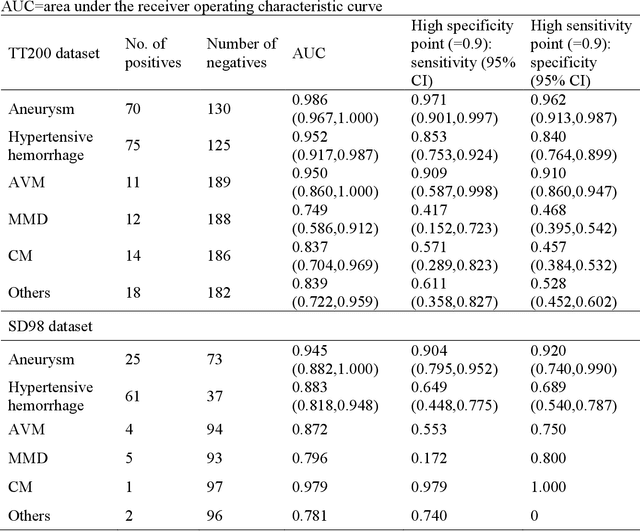
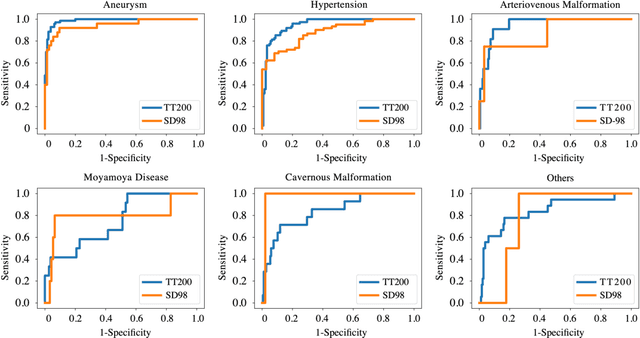
Background: To develop an artificial intelligence system that can accurately identify acute non-traumatic intracranial hemorrhage (ICH) etiology based on non-contrast CT (NCCT) scans and investigate whether clinicians can benefit from it in a diagnostic setting. Materials and Methods: The deep learning model was developed with 1868 eligible NCCT scans with non-traumatic ICH collected between January 2011 and April 2018. We tested the model on two independent datasets (TT200 and SD 98) collected after April 2018. The model's diagnostic performance was compared with clinicians's performance. We further designed a simulated study to compare the clinicians's performance with and without the deep learning system augmentation. Results: The proposed deep learning system achieved area under the receiver operating curve of 0.986 (95% CI 0.967-1.000) on aneurysms, 0.952 (0.917-0.987) on hypertensive hemorrhage, 0.950 (0.860-1.000) on arteriovenous malformation (AVM), 0.749 (0.586-0.912) on Moyamoya disease (MMD), 0.837 (0.704-0.969) on cavernous malformation (CM), and 0.839 (0.722-0.959) on other causes in TT200 dataset. Given a 90% specificity level, the sensitivities of our model were 97.1% and 90.9% for aneurysm and AVM diagnosis, respectively. The model also shows an impressive generalizability in an independent dataset SD98. The clinicians achieve significant improvements in the sensitivity, specificity, and accuracy of diagnoses of certain hemorrhage etiologies with proposed system augmentation. Conclusions: The proposed deep learning algorithms can be an effective tool for early identification of hemorrhage etiologies based on NCCT scans. It may also provide more information for clinicians for triage and further imaging examination selection.
Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features
Jun 02, 2022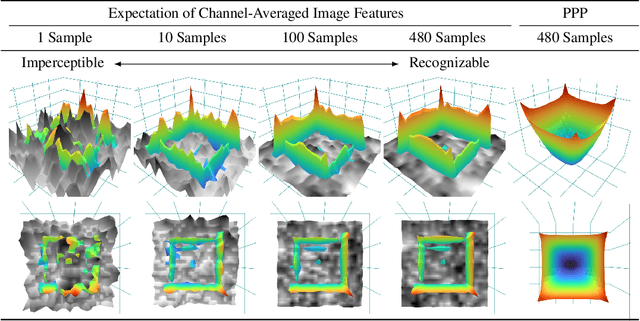
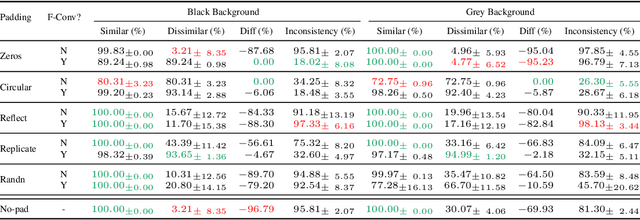
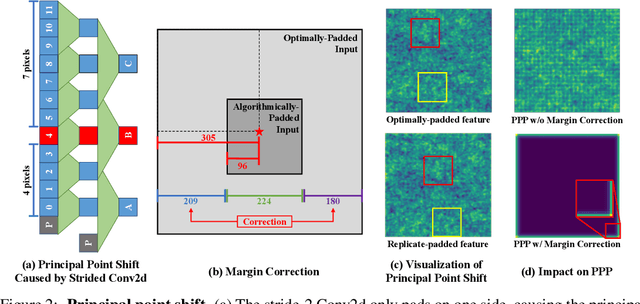
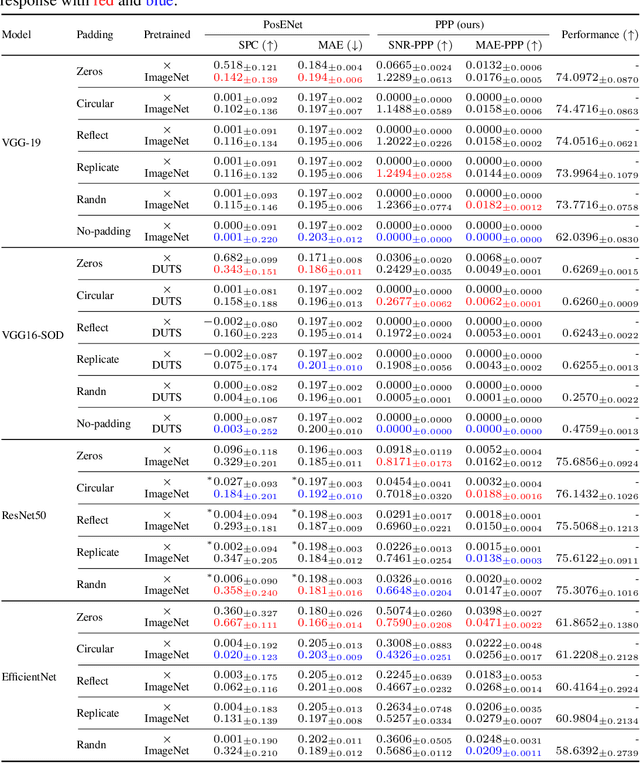
Recent studies show that paddings in convolutional neural networks encode absolute position information which can negatively affect the model performance for certain tasks. However, existing metrics for quantifying the strength of positional information remain unreliable and frequently lead to erroneous results. To address this issue, we propose novel metrics for measuring (and visualizing) the encoded positional information. We formally define the encoded information as PPP (Position-information Pattern from Padding) and conduct a series of experiments to study its properties as well as its formation. The proposed metrics measure the presence of positional information more reliably than the existing metrics based on PosENet and a test in F-Conv. We also demonstrate that for any extant (and proposed) padding schemes, PPP is primarily a learning artifact and is less dependent on the characteristics of the underlying padding schemes.
RIScatter: Unifying Backscatter Communication and Reconfigurable Intelligent Surface
Dec 18, 2022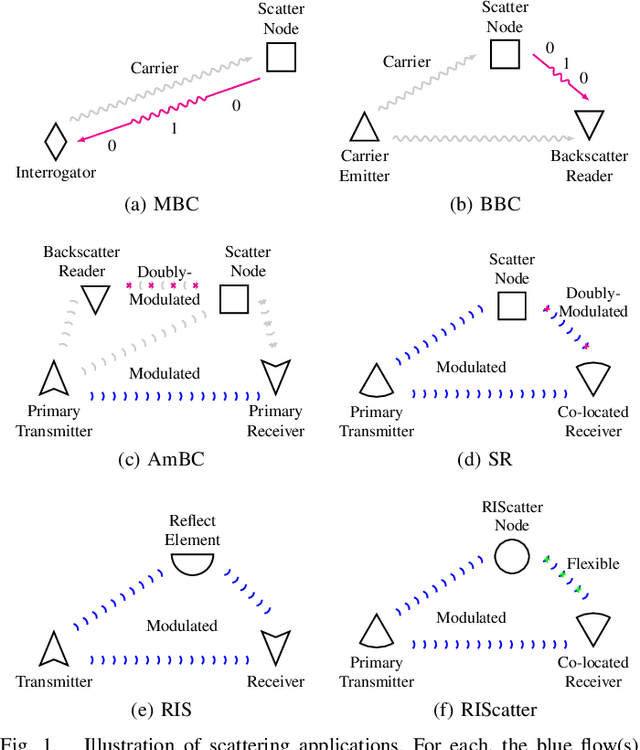
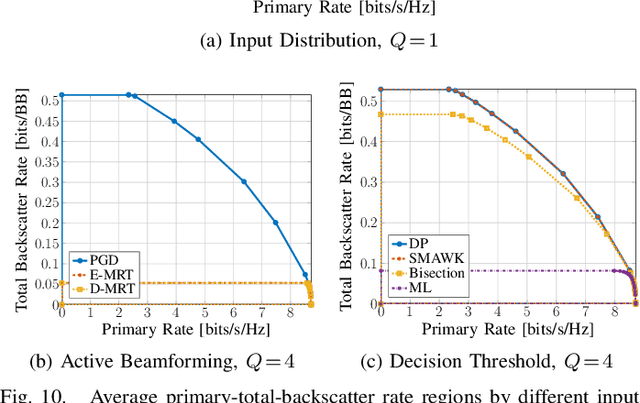
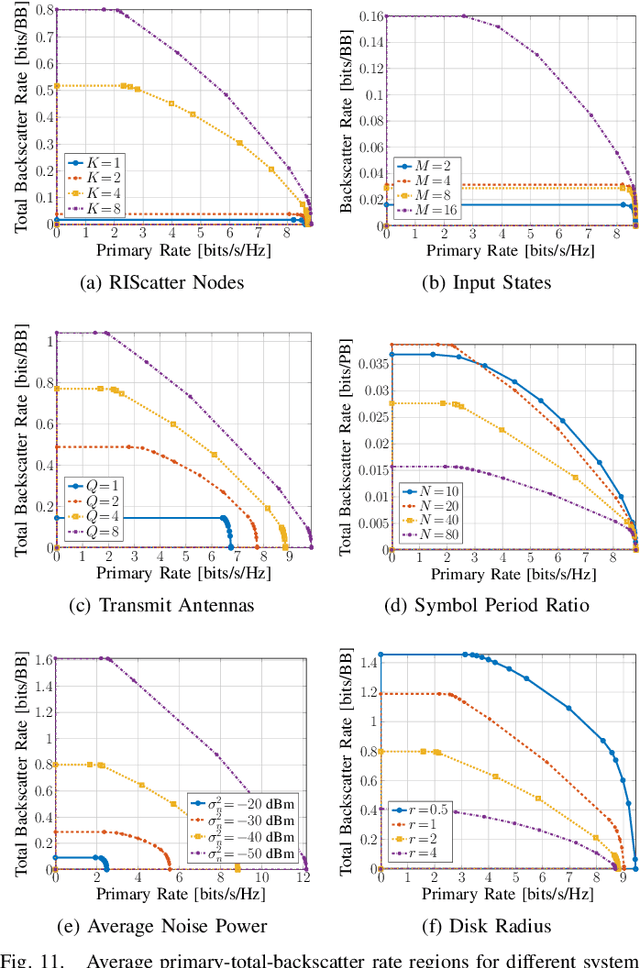

Backscatter Communication (BackCom) nodes harvest energy from and modulate information over an external electromagnetic wave. Reconfigurable Intelligent Surface (RIS) adapts its phase shift response to enhance or attenuate channel strength in specific directions. In this paper, we show how those two seemingly different technologies (and their derivatives) can be unified to leverage their benefits simultaneously into a single architecture called RIScatter. RIScatter consists of multiple dispersed or co-located scatter nodes, whose reflection states can be adapted to partially engineer the wireless channel of the existing link and partially modulate their own information onto the scattered wave. This contrasts with BackCom (resp. RIS) where the reflection pattern is exclusively a function of the information symbol (resp. Channel State Information (CSI)). The key principle in RIScatter is to render the probability distribution of reflection states (i.e., backscatter channel input) as a joint function of the information source, CSI, and Quality of Service (QoS) of the coexisting active primary and passive backscatter links. This enables RIScatter to softly bridge, generalize, and outperform BackCom and RIS; boil down to either under specific input distribution; or evolve in a mixed form for heterogeneous traffic control and universal hardware design. For a single-user multi-node RIScatter network, we characterize the achievable primary-(total-)backscatter rate region by optimizing the input distribution at the nodes, the active beamforming at the Access Point (AP), and the backscatter detection regions at the user. Simulation results demonstrate RIScatter nodes can exploit the additional propagation paths to smoothly transition between backscatter modulation and passive beamforming.
Zero-shot causal learning
Jan 28, 2023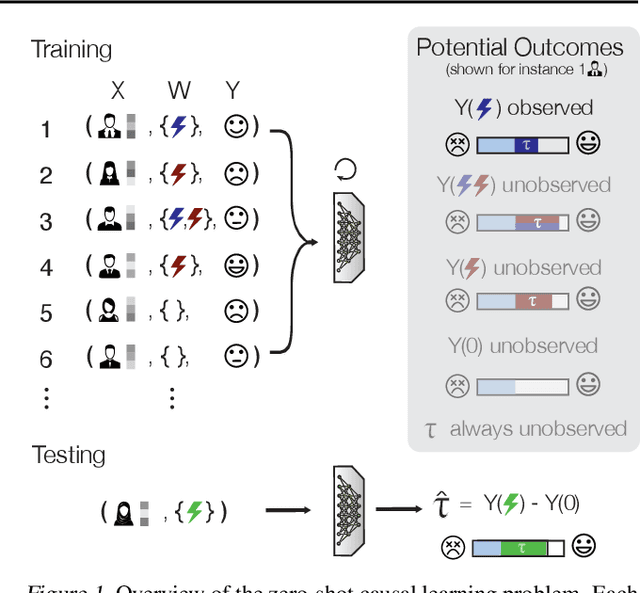


Predicting how different interventions will causally affect a specific individual is important in a variety of domains such as personalized medicine, public policy, and online marketing. However, most existing causal methods cannot generalize to predicting the effects of previously unseen interventions (e.g., a newly invented drug), because they require data for individuals who received the intervention. Here, we consider zero-shot causal learning: predicting the personalized effects of novel, previously unseen interventions. To tackle this problem, we propose CaML, a causal meta-learning framework which formulates the personalized prediction of each intervention's effect as a task. Rather than training a separate model for each intervention, CaML trains as a single meta-model across thousands of tasks, each constructed by sampling an intervention and individuals who either did or did not receive it. By leveraging both intervention information (e.g., a drug's attributes) and individual features (e.g., a patient's history), CaML is able to predict the personalized effects of unseen interventions. Experimental results on real world datasets in large-scale medical claims and cell-line perturbations demonstrate the effectiveness of our approach. Most strikingly, CaML zero-shot predictions outperform even strong baselines which have direct access to data of considered target interventions.
Causality-based Dual-Contrastive Learning Framework for Domain Generalization
Jan 22, 2023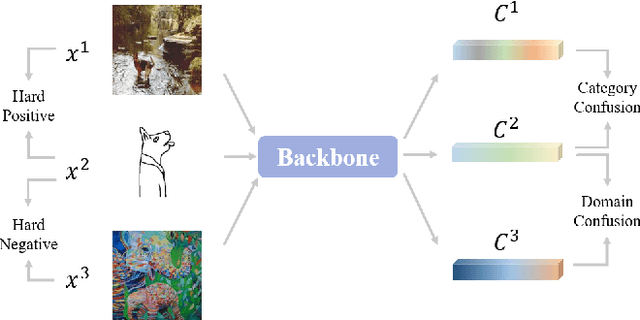
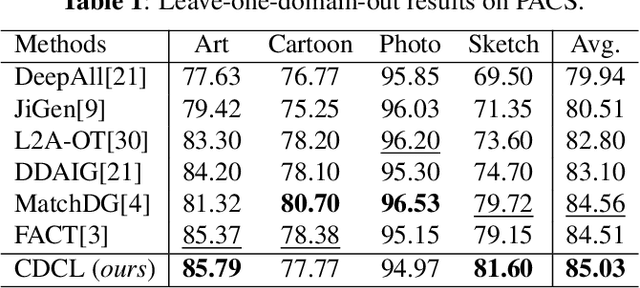
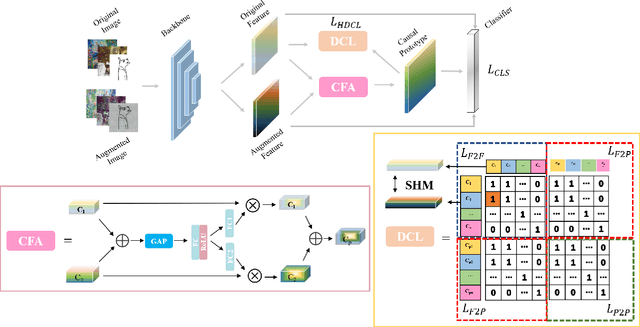
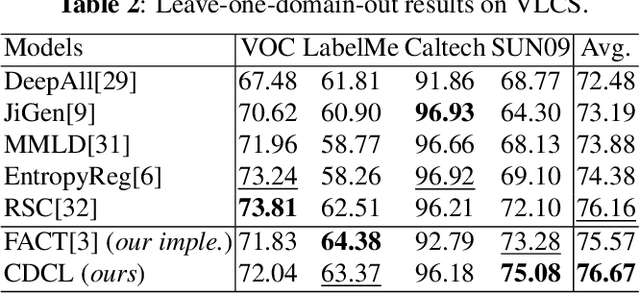
Domain Generalization (DG) is essentially a sub-branch of out-of-distribution generalization, which trains models from multiple source domains and generalizes to unseen target domains. Recently, some domain generalization algorithms have emerged, but most of them were designed with non-transferable complex architecture. Additionally, contrastive learning has become a promising solution for simplicity and efficiency in DG. However, existing contrastive learning neglected domain shifts that caused severe model confusions. In this paper, we propose a Dual-Contrastive Learning (DCL) module on feature and prototype contrast. Moreover, we design a novel Causal Fusion Attention (CFA) module to fuse diverse views of a single image to attain prototype. Furthermore, we introduce a Similarity-based Hard-pair Mining (SHM) strategy to leverage information on diversity shift. Extensive experiments show that our method outperforms state-of-the-art algorithms on three DG datasets. The proposed algorithm can also serve as a plug-and-play module without usage of domain labels.
DASTSiam: Spatio-Temporal Fusion and Discriminative Augmentation for Improved Siamese Tracking
Jan 22, 2023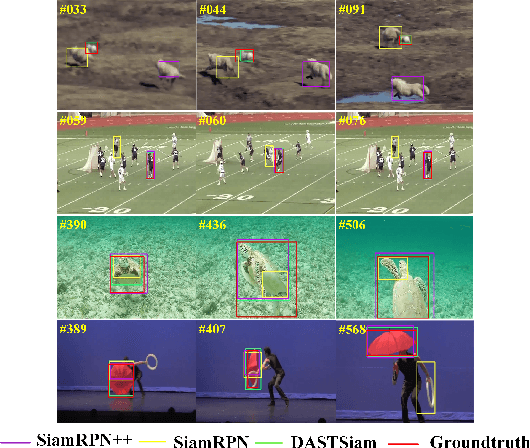


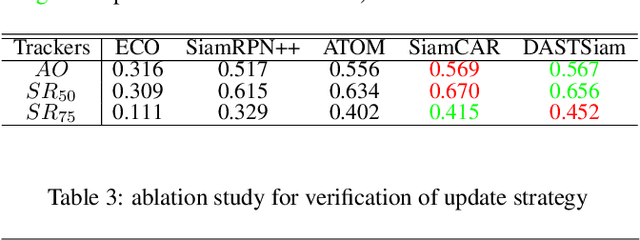
Tracking tasks based on deep neural networks have greatly improved with the emergence of Siamese trackers. However, the appearance of targets often changes during tracking, which can reduce the robustness of the tracker when facing challenges such as aspect ratio change, occlusion, and scale variation. In addition, cluttered backgrounds can lead to multiple high response points in the response map, leading to incorrect target positioning. In this paper, we introduce two transformer-based modules to improve Siamese tracking called DASTSiam: the spatio-temporal (ST) fusion module and the Discriminative Augmentation (DA) module. The ST module uses cross-attention based accumulation of historical cues to improve robustness against object appearance changes, while the DA module associates semantic information between the template and search region to improve target discrimination. Moreover, Modifying the label assignment of anchors also improves the reliability of the object location. Our modules can be used with all Siamese trackers and show improved performance on several public datasets through comparative and ablation experiments.
Multi-Biometric Fuzzy Vault based on Face and Fingerprints
Jan 17, 2023
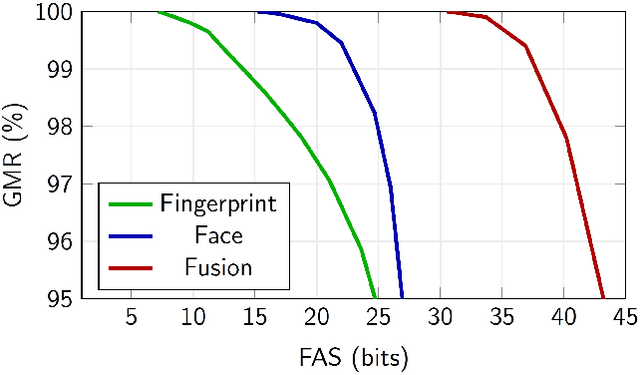

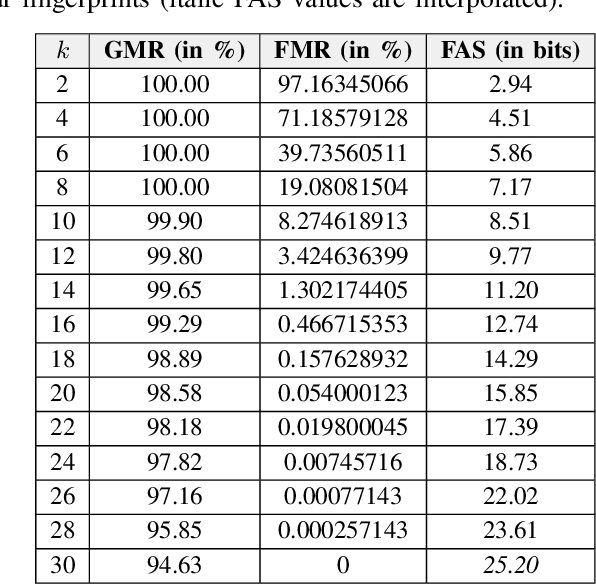
The fuzzy vault scheme has been established as cryptographic primitive suitable for privacy-preserving biometric authentication. To improve accuracy and privacy protection, biometric information of multiple characteristics can be fused at feature level prior to locking it in a fuzzy vault. We construct a multi-biometric fuzzy vault based on face and multiple fingerprints. On a multi-biometric database constructed from the FRGCv2 face and the MCYT-100 fingerprint databases, a perfect recognition accuracy is achieved at a false accept security above 30 bits. Further, we provide a formalisation of feature-level fusion in multi-biometric fuzzy vaults, on the basis of which relevant security issues are elaborated. Said security issues, for which we define countermeasures, are commonly ignored and may impair the overall system's security.