 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Earthquake Wave Arrival Time Picking from Labels with Inaccuracies
Jun 13, 2026Inaccurately labeled training data, or "label noise", poses a significant threat to the integrity of supervised machine learning models. This corruption directly degrades performance by teaching the model erroneous mappings between features and labels, which leads to poor generalization and reduced accuracy on properly labeled validation and test data. Current seismological applications mainly rely on large-scale training sets or data augmentation to reduce the label-noise impact, which can be labor-intensive and costly. Here, we introduce a Label Noise-Contrastive Robust Learning (LaNCoR) approach that can effectively handle noisy labels in seismic signal processing tasks, without requiring large-scale training datasets. In this approach, the input waveform feature and label representation distributions are aligned in the feature space to correct mislabeling and reduce its impact on the training process. We present LaNCoR's performance on the task of P-phase arrival-time picking of real microseismic data using two baseline models and training approaches. Our results indicate that LaNCoR can improve performance by up to 28.8% across performance metrics. This approach holds great promise for model training in seismology and geosciences.
Bridging MARL to SARL: An Order-Independent Multi-Agent Transformer via Latent Consensus
Apr 15, 2026Cooperative multi-agent reinforcement learning (MARL) is widely used to address large joint observation and action spaces by decomposing a centralized control problem into multiple interacting agents. However, such decomposition often introduces additional challenges, including non-stationarity, unstable training, weak coordination, and limited theoretical guarantees. In this paper, we propose the Consensus Multi-Agent Transformer (CMAT), a centralized framework that bridges cooperative MARL to a hierarchical single-agent reinforcement learning (SARL) formulation. CMAT treats all agents as a unified entity and employs a Transformer encoder to process the large joint observation space. To handle the extensive joint action space, we introduce a hierarchical decision-making mechanism in which a Transformer decoder autoregressively generates a high-level consensus vector, simulating the process by which agents reach agreement on their strategies in latent space. Conditioned on this consensus, all agents generate their actions simultaneously, enabling order-independent joint decision making and avoiding the sensitivity to action-generation order in conventional Multi-Agent Transformers (MAT). This factorization allows the joint policy to be optimized using single-agent PPO while preserving expressive coordination through the latent consensus. To evaluate the proposed method, we conduct experiments on benchmark tasks from StarCraft II, Multi-Agent MuJoCo, and Google Research Football. The results show that CMAT achieves superior performance over recent centralized solutions, sequential MARL methods, and conventional MARL baselines. The code for this paper is available at:https://github.com/RS2002/CMAT .
Invertible Diffusion for Low-Memory Channel Gain Map Construction in Wireless Communication Networks
Apr 13, 2026Channel gain maps (CGMs) enable propagation-aware services in edge-intelligent wireless communication networks, while diffusion-based CGM construction is memory intensive for on-device training or adaptation. This letter proposes InvDiff-CGM, an invertible diffusion framework that constructs CGMs from sparse measurements and environmental priors. By adopting invertible architectures in both the diffusion process and the U-Net noise estimator, InvDiff-CGM achieves near-constant training memory consumption. A prior-informed multi-scale injector further integrates environmental priors with sparse measurements to improve physical consistency and detail preservation. Experiments on RadioMap3DSeer show about an 85\% reduction in peak training memory and a PSNR of 38.02~dB, outperforming representative recent baselines. This validates the practicality of InvDiff-CGM for high-fidelity CGM construction under edge resource constraints.
AutoFed: Manual-Free Federated Traffic Prediction via Personalized Prompt
Dec 31, 2025Accurate traffic prediction is essential for Intelligent Transportation Systems, including ride-hailing, urban road planning, and vehicle fleet management. However, due to significant privacy concerns surrounding traffic data, most existing methods rely on local training, resulting in data silos and limited knowledge sharing. Federated Learning (FL) offers an efficient solution through privacy-preserving collaborative training; however, standard FL struggles with the non-independent and identically distributed (non-IID) problem among clients. This challenge has led to the emergence of Personalized Federated Learning (PFL) as a promising paradigm. Nevertheless, current PFL frameworks require further adaptation for traffic prediction tasks, such as specialized graph feature engineering, data processing, and network architecture design. A notable limitation of many prior studies is their reliance on hyper-parameter optimization across datasets-information that is often unavailable in real-world scenarios-thus impeding practical deployment. To address this challenge, we propose AutoFed, a novel PFL framework for traffic prediction that eliminates the need for manual hyper-parameter tuning. Inspired by prompt learning, AutoFed introduces a federated representor that employs a client-aligned adapter to distill local data into a compact, globally shared prompt matrix. This prompt then conditions a personalized predictor, allowing each client to benefit from cross-client knowledge while maintaining local specificity. Extensive experiments on real-world datasets demonstrate that AutoFed consistently achieves superior performance across diverse scenarios. The code of this paper is provided at https://github.com/RS2002/AutoFed .
CitySeeker: How Do VLMS Explore Embodied Urban Navigation With Implicit Human Needs?
Dec 18, 2025Vision-Language Models (VLMs) have made significant progress in explicit instruction-based navigation; however, their ability to interpret implicit human needs (e.g., "I am thirsty") in dynamic urban environments remains underexplored. This paper introduces CitySeeker, a novel benchmark designed to assess VLMs' spatial reasoning and decision-making capabilities for exploring embodied urban navigation to address implicit needs. CitySeeker includes 6,440 trajectories across 8 cities, capturing diverse visual characteristics and implicit needs in 7 goal-driven scenarios. Extensive experiments reveal that even top-performing models (e.g., Qwen2.5-VL-32B-Instruct) achieve only 21.1% task completion. We find key bottlenecks in error accumulation in long-horizon reasoning, inadequate spatial cognition, and deficient experiential recall. To further analyze them, we investigate a series of exploratory strategies-Backtracking Mechanisms, Enriching Spatial Cognition, and Memory-Based Retrieval (BCR), inspired by human cognitive mapping's emphasis on iterative observation-reasoning cycles and adaptive path optimization. Our analysis provides actionable insights for developing VLMs with robust spatial intelligence required for tackling "last-mile" navigation challenges.
C2T-ID: Converting Semantic Codebooks to Textual Document Identifiers for Generative Search
Oct 22, 2025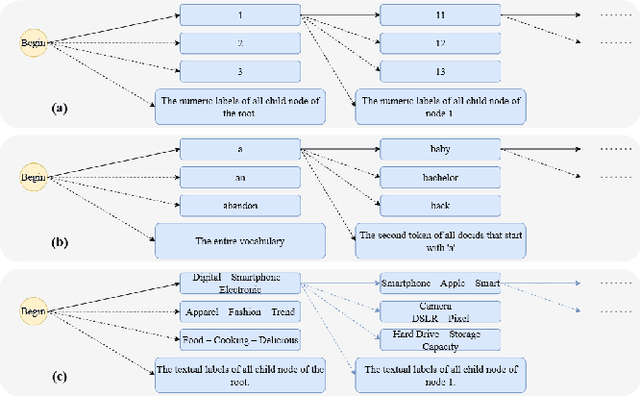
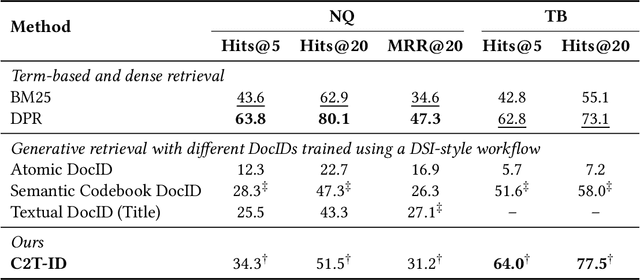
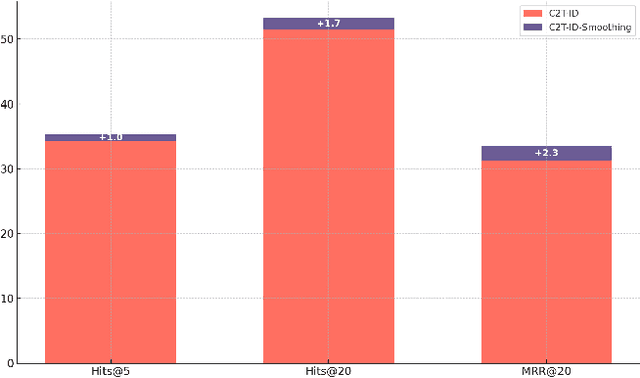
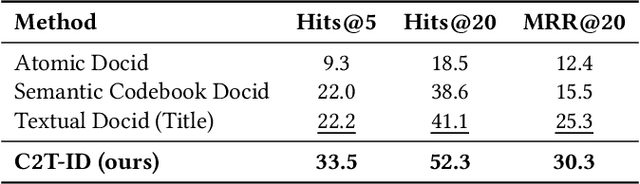
Designing document identifiers (docids) that carry rich semantic information while maintaining tractable search spaces is a important challenge in generative retrieval (GR). Popular codebook methods address this by building a hierarchical semantic tree and constraining generation to its child nodes, yet their numeric identifiers cannot leverage the large language model's pretrained natural language understanding. Conversely, using text as docid provides more semantic expressivity but inflates the decoding space, making the system brittle to early-step errors. To resolve this trade-off, we propose C2T-ID: (i) first construct semantic numerical docid via hierarchical clustering; (ii) then extract high-frequency metadata keywords and iteratively replace each numeric label with its cluster's top-K keywords; and (iii) an optional two-level semantic smoothing step further enhances the fluency of C2T-ID. Experiments on Natural Questions and Taobao's product search demonstrate that C2T-ID significantly outperforms atomic, semantic codebook, and pure-text docid baselines, demonstrating its effectiveness in balancing semantic expressiveness with search space constraints.
G-DReaM: Graph-conditioned Diffusion Retargeting across Multiple Embodiments
May 27, 2025Motion retargeting for specific robot from existing motion datasets is one critical step in transferring motion patterns from human behaviors to and across various robots. However, inconsistencies in topological structure, geometrical parameters as well as joint correspondence make it difficult to handle diverse embodiments with a unified retargeting architecture. In this work, we propose a novel unified graph-conditioned diffusion-based motion generation framework for retargeting reference motions across diverse embodiments. The intrinsic characteristics of heterogeneous embodiments are represented with graph structure that effectively captures topological and geometrical features of different robots. Such a graph-based encoding further allows for knowledge exploitation at the joint level with a customized attention mechanisms developed in this work. For lacking ground truth motions of the desired embodiment, we utilize an energy-based guidance formulated as retargeting losses to train the diffusion model. As one of the first cross-embodiment motion retargeting methods in robotics, our experiments validate that the proposed model can retarget motions across heterogeneous embodiments in a unified manner. Moreover, it demonstrates a certain degree of generalization to both diverse skeletal structures and similar motion patterns.
Car-1000: A New Large Scale Fine-Grained Visual Categorization Dataset
Mar 16, 2025



Fine-grained visual categorization (FGVC) is a challenging but significant task in computer vision, which aims to recognize different sub-categories of birds, cars, airplanes, etc. Among them, recognizing models of different cars has significant application value in autonomous driving, traffic surveillance and scene understanding, which has received considerable attention in the past few years. However, Stanford-Car, the most widely used fine-grained dataset for car recognition, only has 196 different categories and only includes vehicle models produced earlier than 2013. Due to the rapid advancements in the automotive industry during recent years, the appearances of various car models have become increasingly intricate and sophisticated. Consequently, the previous Stanford-Car dataset fails to capture this evolving landscape and cannot satisfy the requirements of automotive industry. To address these challenges, in our paper, we introduce Car-1000, a large-scale dataset designed specifically for fine-grained visual categorization of diverse car models. Car-1000 encompasses vehicles from 165 different automakers, spanning a wide range of 1000 distinct car models. Additionally, we have reproduced several state-of-the-art FGVC methods on the Car-1000 dataset, establishing a new benchmark for research in this field. We hope that our work will offer a fresh perspective for future FGVC researchers. Our dataset is available at https://github.com/toggle1995/Car-1000.
MetaOcc: Surround-View 4D Radar and Camera Fusion Framework for 3D Occupancy Prediction with Dual Training Strategies
Jan 26, 2025



3D occupancy prediction is crucial for autonomous driving perception. Fusion of 4D radar and camera provides a potential solution of robust occupancy prediction on serve weather with least cost. How to achieve effective multi-modal feature fusion and reduce annotation costs remains significant challenges. In this work, we propose MetaOcc, a novel multi-modal occupancy prediction framework that fuses surround-view cameras and 4D radar for comprehensive environmental perception. We first design a height self-attention module for effective 3D feature extraction from sparse radar points. Then, a local-global fusion mechanism is proposed to adaptively capture modality contributions while handling spatio-temporal misalignments. Temporal alignment and fusion module is employed to further aggregate historical feature. Furthermore, we develop a semi-supervised training procedure leveraging open-set segmentor and geometric constraints for pseudo-label generation, enabling robust perception with limited annotations. Extensive experiments on OmniHD-Scenes dataset demonstrate that MetaOcc achieves state-of-the-art performance, surpassing previous methods by significant margins. Notably, as the first semi-supervised 4D radar and camera fusion-based occupancy prediction approach, MetaOcc maintains 92.5% of the fully-supervised performance while using only 50% of ground truth annotations, establishing a new benchmark for multi-modal 3D occupancy prediction. Code and data are available at https://github.com/LucasYang567/MetaOcc.
Coordinating Ride-Pooling with Public Transit using Reward-Guided Conservative Q-Learning: An Offline Training and Online Fine-Tuning Reinforcement Learning Framework
Jan 24, 2025



This paper introduces a novel reinforcement learning (RL) framework, termed Reward-Guided Conservative Q-learning (RG-CQL), to enhance coordination between ride-pooling and public transit within a multimodal transportation network. We model each ride-pooling vehicle as an agent governed by a Markov Decision Process (MDP) and propose an offline training and online fine-tuning RL framework to learn the optimal operational decisions of the multimodal transportation systems, including rider-vehicle matching, selection of drop-off locations for passengers, and vehicle routing decisions, with improved data efficiency. During the offline training phase, we develop a Conservative Double Deep Q Network (CDDQN) as the action executor and a supervised learning-based reward estimator, termed the Guider Network, to extract valuable insights into action-reward relationships from data batches. In the online fine-tuning phase, the Guider Network serves as an exploration guide, aiding CDDQN in effectively and conservatively exploring unknown state-action pairs. The efficacy of our algorithm is demonstrated through a realistic case study using real-world data from Manhattan. We show that integrating ride-pooling with public transit outperforms two benchmark cases solo rides coordinated with transit and ride-pooling without transit coordination by 17% and 22% in the achieved system rewards, respectively. Furthermore, our innovative offline training and online fine-tuning framework offers a remarkable 81.3% improvement in data efficiency compared to traditional online RL methods with adequate exploration budgets, with a 4.3% increase in total rewards and a 5.6% reduction in overestimation errors. Experimental results further demonstrate that RG-CQL effectively addresses the challenges of transitioning from offline to online RL in large-scale ride-pooling systems integrated with transit.