 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA k-space approach to modeling multi-channel parametric array loudspeaker systems
Jul 30, 2025Multi-channel parametric array loudspeaker (MCPAL) systems offer enhanced flexibility and promise for generating highly directional audio beams in real-world applications. However, efficient and accurate prediction of their generated sound fields remains a major challenge due to the complex nonlinear behavior and multi-channel signal processing involved. To overcome this obstacle, we propose a k-space approach for modeling arbitrary MCPAL systems arranged on a baffled planar surface. In our method, the linear ultrasound field is first solved using the angular spectrum approach, and the quasilinear audio sound field is subsequently computed efficiently in k-space. By leveraging three-dimensional fast Fourier transforms, our approach not only achieves high computational and memory efficiency but also maintains accuracy without relying on the paraxial approximation. For typical configurations studied, the proposed method demonstrates a speed-up of more than four orders of magnitude compared to the direct integration method. Our proposed approach paved the way for simulating and designing advanced MCPAL systems.
Generating Localized Audible Zones Using a Single-Channel Parametric Loudspeaker
Apr 24, 2025



Advanced sound zone control (SZC) techniques typically rely on massive multi-channel loudspeaker arrays to create high-contrast personal sound zones, making single-loudspeaker SZC seem impossible. In this Letter, we challenge this paradigm by introducing the multi-carrier parametric loudspeaker (MCPL), which enables SZC using only a single loudspeaker. In our approach, distinct audio signals are modulated onto separate ultrasonic carrier waves at different frequencies and combined into a single composite signal. This signal is emitted by a single-channel ultrasonic transducer, and through nonlinear demodulation in air, the audio signals interact to virtually form multi-channel outputs. This novel capability allows the application of existing SZC algorithms originally designed for multi-channel loudspeaker arrays. Simulations validate the effectiveness of our proposed single-channel MCPL, demonstrating its potential as a promising alternative to traditional multi-loudspeaker systems for achieving high-contrast SZC. Our work opens new avenues for simplifying SZC systems without compromising performance.
Deep Learning-Based Approach for Identification and Compensation of Nonlinear Distortions in Parametric Array Loudspeakers
Dec 02, 2024



Compared to traditional electrodynamic loudspeakers, the parametric array loudspeaker (PAL) offers exceptional directivity for audio applications but suffers from significant nonlinear distortions due to its inherent intricate demodulation process. The Volterra filter-based approaches have been widely used to reduce these distortions, but the effectiveness is limited by its inverse filter's capability. Specifically, its pth-order inverse filter can only compensate for nonlinearities up to the pth order, while the higher-order nonlinearities it introduces continue to generate lower-order harmonics. In contrast, this paper introduces the modern deep learning methods for the first time to address nonlinear identification and compensation for PAL systems. Specifically, a feedforward variant of the WaveNet neural network, recognized for its success in audio nonlinear system modeling, is utilized to identify and compensate for distortions in a double sideband amplitude modulation-based PAL system. Experimental measurements from 250 Hz to 8 kHz demonstrate that our proposed approach significantly reduces both total harmonic distortion and intermodulation distortion of audio sound generated by PALs, achieving average reductions to 4.55% and 2.47%, respectively. This performance is notably superior to results obtained using the current state-of-the-art Volterra filter-based methods. Our work opens new possibilities for improving the sound reproduction performance of PALs.
The feasibility of sound zone control using an array of parametric array loudspeakers
Jul 14, 2024



Parametric array loudspeakers (PALs) are known for producing highly directional audio beams, a feat more challenging to achieve with conventional electro-dynamic loudspeakers (EDLs). Due to their intrinsic physical mechanisms, PALs hold promising potential for spatial audio applications such as virtual reality (VR). However, the feasibility of using an array of PALs for sound zone control (SZC) has remained unexplored, mainly due to the complexity of the nonlinear demodulation process inherent in PALs. Leveraging recent advancements in PAL modeling, this work proposes an optimization algorithm to achieve the acoustic contrast control (ACC) between two target areas using a PAL array. The performance and robustness of the proposed ACC-based SZC using PAL arrays are investigated through simulations, and the results are compared with those obtained using EDL arrays. The results show that the PAL array outperforms the EDL array in SZC performance and robustness at higher frequencies and lower signal-to-noise ratio, while being comparable under other conditions. This work paves the way for high-contrast acoustic control using PAL arrays.
Multi-channel Integrated Recommendation with Exposure Constraints
May 21, 2023



Integrated recommendation, which aims at jointly recommending heterogeneous items from different channels in a main feed, has been widely applied to various online platforms. Though attractive, integrated recommendation requires the ranking methods to migrate from conventional user-item models to the new user-channel-item paradigm in order to better capture users' preferences on both item and channel levels. Moreover, practical feed recommendation systems usually impose exposure constraints on different channels to ensure user experience. This leads to greater difficulty in the joint ranking of heterogeneous items. In this paper, we investigate the integrated recommendation task with exposure constraints in practical recommender systems. Our contribution is forth-fold. First, we formulate this task as a binary online linear programming problem and propose a two-layer framework named Multi-channel Integrated Recommendation with Exposure Constraints (MIREC) to obtain the optimal solution. Second, we propose an efficient online allocation algorithm to determine the optimal exposure assignment of different channels from a global view of all user requests over the entire time horizon. We prove that this algorithm reaches the optimal point under a regret bound of $ \mathcal{O}(\sqrt{T}) $ with linear complexity. Third, we propose a series of collaborative models to determine the optimal layout of heterogeneous items at each user request. The joint modeling of user interests, cross-channel correlation, and page context in our models aligns more with the browsing nature of feed products than existing models. Finally, we conduct extensive experiments on both offline datasets and online A/B tests to verify the effectiveness of MIREC. The proposed framework has now been implemented on the homepage of Taobao to serve the main traffic.
Multi-factor Sequential Re-ranking with Perception-Aware Diversification
May 21, 2023



Feed recommendation systems, which recommend a sequence of items for users to browse and interact with, have gained significant popularity in practical applications. In feed products, users tend to browse a large number of items in succession, so the previously viewed items have a significant impact on users' behavior towards the following items. Therefore, traditional methods that mainly focus on improving the accuracy of recommended items are suboptimal for feed recommendations because they may recommend highly similar items. For feed recommendation, it is crucial to consider both the accuracy and diversity of the recommended item sequences in order to satisfy users' evolving interest when consecutively viewing items. To this end, this work proposes a general re-ranking framework named Multi-factor Sequential Re-ranking with Perception-Aware Diversification (MPAD) to jointly optimize accuracy and diversity for feed recommendation in a sequential manner. Specifically, MPAD first extracts users' different scales of interests from their behavior sequences through graph clustering-based aggregations. Then, MPAD proposes two sub-models to respectively evaluate the accuracy and diversity of a given item by capturing users' evolving interest due to the ever-changing context and users' personal perception of diversity from an item sequence perspective. This is consistent with the browsing nature of the feed scenario. Finally, MPAD generates the return list by sequentially selecting optimal items from the candidate set to maximize the joint benefits of accuracy and diversity of the entire list. MPAD has been implemented in Taobao's homepage feed to serve the main traffic and provide services to recommend billions of items to hundreds of millions of users every day.
Entire Space Learning Framework: Unbias Conversion Rate Prediction in Full Stages of Recommender System
Mar 01, 2023



Recommender system is an essential part of online services, especially for e-commerce platform. Conversion Rate (CVR) prediction in RS plays a significant role in optimizing Gross Merchandise Volume (GMV) goal of e-commerce. However, CVR suffers from well-known Sample Selection Bias (SSB) and Data Sparsity (DS) problems. Although existing methods ESMM and ESM2 train with all impression samples over the entire space by modeling user behavior paths, SSB and DS problems still exist. In real practice, the online inference space are samples from previous stage of RS process, rather than the impression space modeled by existing methods. Moreover, existing methods solve the DS problem mainly by building behavior paths of their own specific scene, ignoring the behaviors in various scenes of e-commerce platform. In this paper, we propose Entire Space Learning Framework: Unbias Conversion Rate Prediction in Full Stages of Recommender System, solving SSB and DS problems by reformulating GMV goal in a novel manner. Specifically, we rebuild the CVR on the entire data space with samples from previous stage of RS process, unifying training and online inference space. Moreover, we explicitly introduce purchase samples from other scenes of e-commerce platform in model learning process. Online A/B test and offline experiments show the superiority of our framework. Our framework has been deployed in rank stage of Taobao recommendation, providing recommendation service for hundreds of millions of consumers everyday.
MAKE: Product Retrieval with Vision-Language Pre-training in Taobao Search
Jan 30, 2023



Taobao Search consists of two phases: the retrieval phase and the ranking phase. Given a user query, the retrieval phase returns a subset of candidate products for the following ranking phase. Recently, the paradigm of pre-training and fine-tuning has shown its potential in incorporating visual clues into retrieval tasks. In this paper, we focus on solving the problem of text-to-multimodal retrieval in Taobao Search. We consider that users' attention on titles or images varies on products. Hence, we propose a novel Modal Adaptation module for cross-modal fusion, which helps assigns appropriate weights on texts and images across products. Furthermore, in e-commerce search, user queries tend to be brief and thus lead to significant semantic imbalance between user queries and product titles. Therefore, we design a separate text encoder and a Keyword Enhancement mechanism to enrich the query representations and improve text-to-multimodal matching. To this end, we present a novel vision-language (V+L) pre-training methods to exploit the multimodal information of (user query, product title, product image). Extensive experiments demonstrate that our retrieval-specific pre-training model (referred to as MAKE) outperforms existing V+L pre-training methods on the text-to-multimodal retrieval task. MAKE has been deployed online and brings major improvements on the retrieval system of Taobao Search.
Hierarchical Multi-Interest Co-Network For Coarse-Grained Ranking
Oct 19, 2022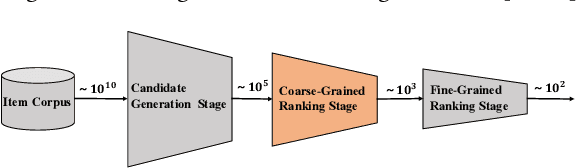
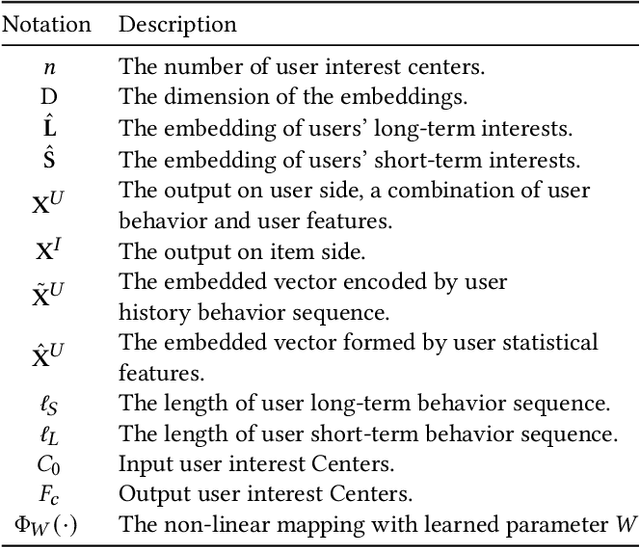
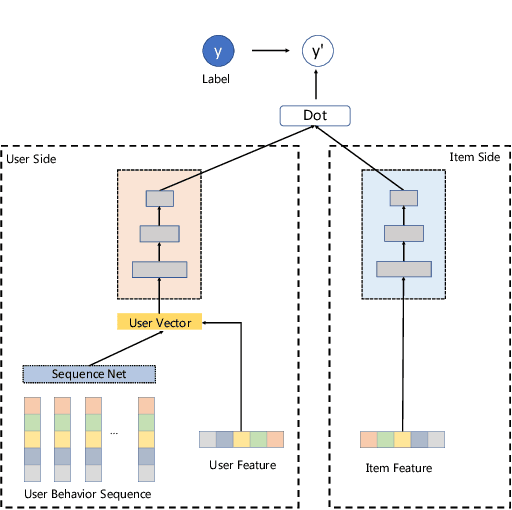
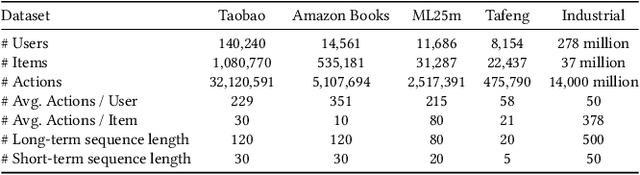
In this era of information explosion, a personalized recommendation system is convenient for users to get information they are interested in. To deal with billions of users and items, large-scale online recommendation services usually consist of three stages: candidate generation, coarse-grained ranking, and fine-grained ranking. The success of each stage depends on whether the model accurately captures the interests of users, which are usually hidden in users' behavior data. Previous research shows that users' interests are diverse, and one vector is not sufficient to capture users' different preferences. Therefore, many methods use multiple vectors to encode users' interests. However, there are two unsolved problems: (1) The similarity of different vectors in existing methods is too high, with too much redundant information. Consequently, the interests of users are not fully represented. (2) Existing methods model the long-term and short-term behaviors together, ignoring the differences between them. This paper proposes a Hierarchical Multi-Interest Co-Network (HCN) to capture users' diverse interests in the coarse-grained ranking stage. Specifically, we design a hierarchical multi-interest extraction layer to update users' diverse interest centers iteratively. The multiple embedded vectors obtained in this way contain more information and represent the interests of users better in various aspects. Furthermore, we develop a Co-Interest Network to integrate users' long-term and short-term interests. Experiments on several real-world datasets and one large-scale industrial dataset show that HCN effectively outperforms the state-of-the-art methods. We deploy HCN into a large-scale real world E-commerce system and achieve extra 2.5\% improvements on GMV (Gross Merchandise Value).
Multi-Objective Personalized Product Retrieval in Taobao Search
Oct 09, 2022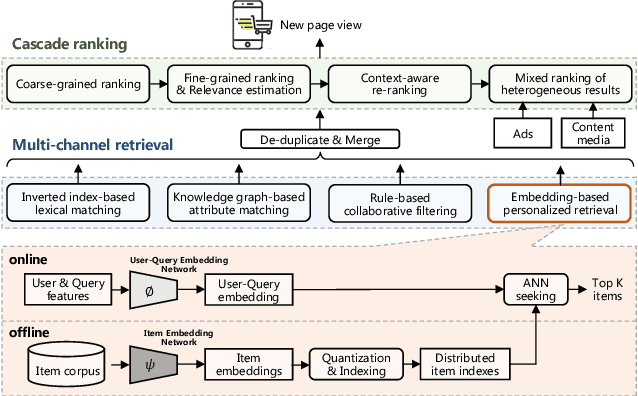

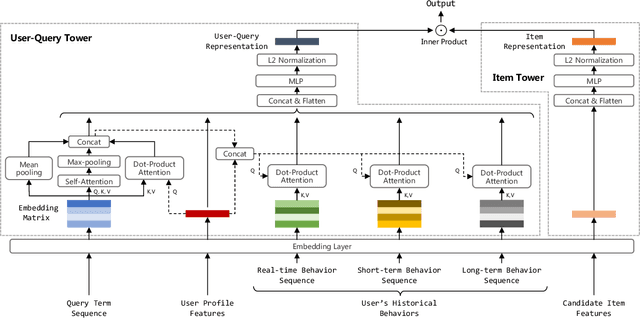

In large-scale e-commerce platforms like Taobao, it is a big challenge to retrieve products that satisfy users from billions of candidates. This has been a common concern of academia and industry. Recently, plenty of works in this domain have achieved significant improvements by enhancing embedding-based retrieval (EBR) methods, including the Multi-Grained Deep Semantic Product Retrieval (MGDSPR) model [16] in Taobao search engine. However, we find that MGDSPR still has problems of poor relevance and weak personalization compared to other retrieval methods in our online system, such as lexical matching and collaborative filtering. These problems promote us to further strengthen the capabilities of our EBR model in both relevance estimation and personalized retrieval. In this paper, we propose a novel Multi-Objective Personalized Product Retrieval (MOPPR) model with four hierarchical optimization objectives: relevance, exposure, click and purchase. We construct entire-space multi-positive samples to train MOPPR, rather than the single-positive samples for existing EBR models.We adopt a modified softmax loss for optimizing multiple objectives. Results of extensive offline and online experiments show that MOPPR outperforms the baseline MGDSPR on evaluation metrics of relevance estimation and personalized retrieval. MOPPR achieves 0.96% transaction and 1.29% GMV improvements in a 28-day online A/B test. Since the Double-11 shopping festival of 2021, MOPPR has been fully deployed in mobile Taobao search, replacing the previous MGDSPR. Finally, we discuss several advanced topics of our deeper explorations on multi-objective retrieval and ranking to contribute to the community.